







Abstract
大多数现有的主要基于电子病历(EMRs)的药物推荐系统在显著帮助医生做出更好的临床决策方面,使患者和护理人员均受益。尽管在大数据时代电子病历的增长速度极快,但电子病历中的内容局限性限制了现有的推荐系统反映相关医疗事实,例如药物相互作用。许多包含药物相关信息的医学知识图谱,如DrugBank,可能为推荐系统带来希望。然而,在系统中直接使用这些知识图谱会因图谱的不完整性而受到鲁棒性问题的困扰。为了应对这些挑战,我们基于图嵌入学习技术的最新进展,在本文中提出了一个名为安全药物推荐(SMR)的新框架。具体而言,SMR首先通过连接电子病历(MIMIC - III)和医学知识图谱(ICD - 9本体和DrugBank)构建一个高质量的异质图。然后,SMR将疾病、药物、患者及其相应关系联合嵌入到一个共享的低维空间中。最后,SMR在考虑患者的诊断和药物不良反应的同时,使用嵌入将药物推荐分解为一个链接预测过程。在真实数据集上进行了大量实验,以评估所提出框架的有效性。
关键词:知识图谱、嵌入、推荐系统、药物安全
1. Introduction
在过去的几年里,药物推荐系统已经被开发出来,以协助医生做出准确的药物处方。一方面,许多研究人员[1, 2]采用基于规则的协议,这些协议由临床指南和经验丰富的医生定义。构建、整理和维护这些协议是耗时且劳动密集型的。基于规则的协议可能对特定诊断的一般药物推荐有效,但对复杂患者的个性化推荐帮助甚微。另一方面,监督学习算法及其变体,如多实例多标签(MIML)学习[3],已被提出用于为患者推荐药物。从大量电子病历中提取的输入特征和真实信息都经过训练,以获得一个预测模型,该模型输出新测试数据的多个标签作为药物推荐。事实上,临床实践中的治疗方法更新迅速。不幸的是,监督学习方法无法处理那些未包含在训练阶段的药物。不完整的训练数据集将不利于推荐系统的性能。
据报道[4, 5],患有两种或更多种急性或慢性疾病的患者,通常同时服用五种或更多不同的药物,并面临巨大的健康风险。研究[6, 7]表明,所有医院内滥用处方的3 - 5%归咎于对药物不良反应的无知,即使对于训练有素且经验丰富的临床医生来说,这也难以避免。在传统药物推荐系统的协助下,临床医生仍然需要谨慎排除那些因药物相互作用而可能产生潜在不良影响的推荐。大多数现有工作在很大程度上忽略了对药物中医疗事实的利用,例如药物相互作用,这在药物推荐系统中至关重要。一个可能的原因可能是电子病历中几乎没有医学专家知识。电子病历中的内容局限性限制了系统将准确的医疗事实与推荐的处方紧密关联,这使得对于复杂患者的最终推荐不太可靠。
随着知识图谱的不断涌现,许多世界领先的研究人员已经成功地从大量医学数据库中提取信息,构建了反映药物和疾病医学事实的巨大异质图。例如,DrugBank[8]是药物信息的丰富来源。它包含广泛的实体(药物、药物靶点、化学等)和关系(酶促途径、药物相互作用等)。ICD - 9本体[9]代表了人类疾病的知识库,可用于对患者的诊断进行分类。在基于电子病历的药物推荐系统中利用构建良好的医学知识图谱,可能使改进后的系统能够为特殊患者提供适当的处方,以及可能的副作用和严重药物相互作用(DDIs)的警报。
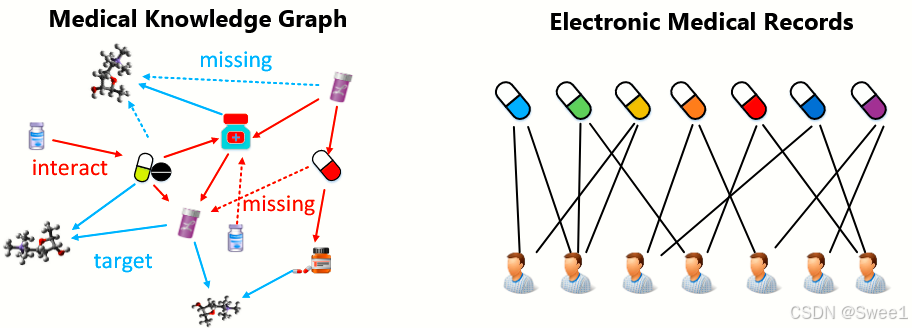
图1:左侧部分是一个缺失关系的医学知识图谱。右侧部分是电子病历(EMRs)中的处方记录,每条边表示患者服用了一种药物。电子病历中的药物之间没有关系。
如图1所示,将电子病历(EMRs)和医学知识图谱相连接以生成一个大型且高质量的异质图,是在更广泛范围内进行药物推荐的一条有前途的途径,但绝非易事。具体而言,新设计的系统面临以下挑战:
- 计算效率:基于传统的基于图的算法查询专门的医学实体和关系,在可移植性和可扩展性方面存在局限性。当异质图达到非常大的规模时,计算复杂度变得不可行。
- 数据不完整性:医学知识图谱也与其他类型的大规模知识库一样遵循长尾分布。在这种分布中,实体和关系之间存在的另一个严重问题是数据不完整性。例如,由于药物相互作用(DDIs)通常在临床试验阶段未被识别,DrugBank中缺乏重要的DDIs,无法为用药提供全面的预防措施。最后但同样重要的是,药物推荐还面临
- 冷启动问题:由于传统系统通常基于历史记录推荐药物,推荐变化的速度跟不上医学实践中新疗法和新治疗方法的频繁更新。历史电子病历中甚至是构建良好的知识图谱中关于新更新药物的不良反应的信息很少,这使得基于证据的推荐模型难以支持新药物作为更新的推荐。
考虑到上述所有挑战,我们受链接预测思想的启发,提出了一种基于图嵌入技术的新型药物推荐框架。在本文中,我们将我们的框架命名为安全药物推荐(SMR)。推荐过程主要包括:
- 从电子病历和医学知识图谱构建一个大型异质图,其中节点是实体(药物、疾病、患者),边(或链接)表示实体之间的各种关系,例如药物相互作用。
- 基于图的嵌入模型,将生成的异质图的不同部分(患者 - 药物二分图、患者 - 疾病二分图、药物知识图谱、疾病知识图谱)嵌入到一个共享的低维空间中。之后,提出了一种联合学习算法来同时优化集成图。
- 基于学习到的嵌入,将一个新患者(由其诊断向量表示)建模为疾病 - 患者图中的一个实体。为患者推荐药物被转化为预测从患者到药物的链接。
这项工作的主要贡献总结如下:
- 我们开发了基于图的嵌入模型,以在共享的低维空间中学习患者、疾病和药物的有效表示。药物的表示使所提出的框架甚至能够有效地为患者推荐新出现的药物,这与大多数现有工作有所不同。
- 为了为新患者推荐安全的药物,我们提出了一种基于学习到的图嵌入来建模患者的新方法,并通过最小化潜在的药物不良反应来进行安全推荐。
- 我们在大型真实世界数据集(MIMIC - III、DrugBank和ICD - 9本体)上进行了大量实验,以评估我们框架的有效性。实验结果表明,所提出的框架优于所有比较方法。
- 据我们所知,我们首先提出了一个进行安全药物推荐(SMR)的框架,并将其表述为一个链接预测问题。该实现生成了一个高质量的异质图,在其中可以更广泛地揭示患者、疾病和药物之间的关系。
本文的其余部分组织如下:第2节详细介绍了我们提出的框架SMR。第3节报告实验结果,第4节回顾相关工作。第5节给出结论和未来工作。
2. The Proposed Framework
在本节中,我们将首先描述相关符号并阐述药物推荐问题,然后介绍图嵌入模型以及如何使用学习到的嵌入为患者推荐安全药物。
2.1. Problem Formulation
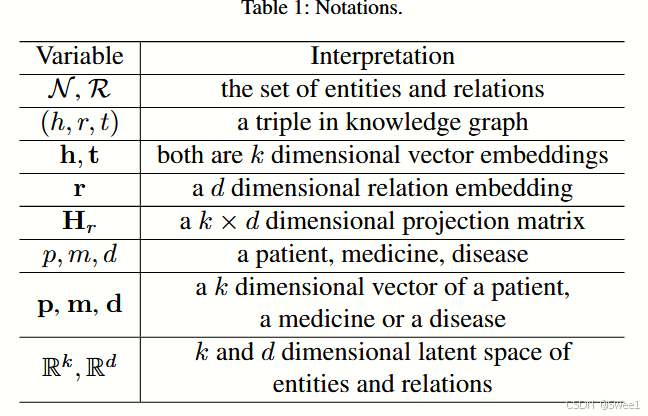
在我们专注于药物推荐问题之前,我们首先简要介绍本文其余部分所使用的重要符号。表1也对它们进行了总结。
医学知识图谱描述了从集成来源收集的医学实体以及这些实体之间的关系。例如,三元组(糖皮质激素,不良相互作用,阿司匹林)表示在DrugBank中糖皮质激素与阿司匹林之间存在不良相互作用关系。我们将医学知识图谱定义如下。
定义1(医学知识图谱):医学知识图谱 G = ( N , R ) G = (\mathcal{N}, \mathcal{R}) G=(N,R)是一组形如 ( h , r , t ) (h, r, t) (h,r,t)的三元组,其中 N \mathcal{N} N是实体集, R \mathcal{R} R是关系集, h , t ∈ N h, t \in \mathcal{N} h,t∈N且 r ∈ R r \in \mathcal{R} r∈R。
为了捕捉电子病历中患者、疾病和药物的相互关系,我们如下定义患者 - 疾病、患者 - 药物二分图。
定义2(患者 - 药物二分图):患者 - 药物二分图表示为 G p m = ( P ∪ M , E p m ) G_{pm} = (\mathcal{P} \cup \mathcal{M}, \mathcal{E}_{pm}) Gpm=(P∪M,Epm),其中 P \mathcal{P} P是患者集, M \mathcal{M} M是药物集。 E p m \mathcal{E}_{pm} Epm是边集。如果患者 p i p_i pi服用药物 m j m_j mj,则它们之间存在边 e i j e_{ij} eij,否则不存在。患者 p i p_i pi与药物 m j m_j mj之间边的权重 w i j w_{ij} wij定义为患者 p i p_i pi服用药物 m j m_j mj的总次数。
定义3(患者 - 疾病二分图):患者 - 疾病二分图表示为 G p d = ( P ∪ D , E p d ) G_{pd} = (\mathcal{P} \cup \mathcal{D}, \mathcal{E}_{pd}) Gpd=(P∪D,Epd),其中 P \mathcal{P} P是患者集, D \mathcal{D} D是疾病集。 E p d \mathcal{E}_{pd} Epd是边集。如果患者 p i p_i pi被诊断患有疾病 d j d_j dj,则它们之间存在边 e i j e_{ij} eij,否则不存在。当边 e i j e_{ij} eij存在时,权重 w i j w_{ij} wij设置为1。
图2通过从MIMIC - III构建患者 - 疾病、患者 - 药物二分图,并将它们与医学知识图谱、ICD - 9本体和DrugBank相链接,展示了一个异质图。最后,我们正式将安全药物推荐问题定义如下。
问题1(安全药物推荐):给定患者 p p p及其诊断数据集 D p \mathcal{D}_p Dp,为每个 d ∈ D p d \in \mathcal{D}_p d∈Dp推荐安全药物就是预测从 p p p到药物数据集 M \mathcal{M} M的边。输出是具有最小药物相互作用的药物集 M p \mathcal{M}_p Mp。
2.2. Model Description and Optimization
在本节中,我们提出嵌入学习方法,将异质图编码到潜在空间及其优化方法。
医学知识图谱嵌入医学知识图谱 G = ( N , R ) G = (\mathcal{N}, \mathcal{R}) G=(N,R)是一个多关系图,其中实体 N \mathcal{N} N和关系 R \mathcal{R} R可以是不同类型。对于三元组 ( h , r , t ) ∈ G (h, r, t) \in G (h,r,t)∈G,我们使用粗体字母 h \mathbf{h} h、 r \mathbf{r} r、 t \mathbf{t} t来表示 h h h、 r r r、 t t t的相应嵌入表示。已经提出了大量的图嵌入方法来将多关系图编码到连续向量空间中。基于平移的模型[10, 11, 12]将每个 ( h , r , t ) (h, r, t) (h,r,t)中的关系 r r r视为低维空间中从 h h h到 t t t的平移,即 h + r − t \mathbf{h} + \mathbf{r} - \mathbf{t} h+r−t,并且比传统模型表现得更加高效。TransR[12]是一种先进的基于平移的嵌入方法。它通过特定关系的矩阵将实体和关系表示在不同的向量空间中,以获得更好的图表示。
考虑到上述原因,我们设置实体嵌入 h \mathbf{h} h、 t ∈ R k \mathbf{t} \in \mathbb{R}^k t∈Rk和关系嵌入 r ∈ R d \mathbf{r} \in \mathbb{R}^d r∈Rd。并且我们设置一个投影矩阵 H r ∈ R k × d \mathbf{H}_r \in \mathbb{R}^{k \times d} Hr∈Rk×d,它将实体从实体空间投影到关系空间。我们定义实体之间的平移并得到能量函数 z ( h , r , t ) z(h, r, t) z(h,r,t)为:
z ( h , r , t ) = b − ∥ h H r + r − t H r ∥ L 1 / L 2 ( 1 ) z(\mathbf{h}, \mathbf{r}, \mathbf{t}) = b - \|\mathbf{h}\mathbf{H}_r + \mathbf{r} - \mathbf{t}\mathbf{H}_r\|_{L1/L2} \quad (1) z(h,r,t)=b−∥hHr+r−tHr∥L1/L2(1)
其中 b b b是一个偏置常数。
然后,三元组 ( h , r , t ) (h, r, t) (h,r,t)的条件概率定义如下:
P ( h ∣ r , t ) = e x p { z ( h , r , t ) } ∑ h ^ ∈ N e x p { z ( h ^ , r , t ) } ( 2 ) P(h|r, t) = \frac{exp\{z(\mathbf{h}, \mathbf{r}, \mathbf{t})\}}{\sum_{\hat{h} \in \mathcal{N}} exp\{z(\hat{\mathbf{h}}, \mathbf{r}, \mathbf{t})\}} \quad (2) P(h∣r,t)=∑h^∈Nexp{ z(h^,r,t)}exp{ z(h,r,t)}(2)
并且 P ( t ∣ h , r ) P(t|h, r) P(t∣h,r)、 P ( r ∣ h , t ) P(r|h, t)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











