









Leave No Patient Behind: Enhancing Medication Recommendation for Rare Disease Patients
ABSTRACT
1. 研究背景
药物推荐系统的重要性:药物推荐系统在医疗保健领域受到了广泛关注,它能够根据患者的临床信息提供量身定制且有效的药物组合。
2. 现有问题
公平性问题:现有方法通常存在公平性问题,对于常见疾病患者的推荐往往比罕见病患者更准确。
3. 提出的方法
模型名称:本文提出了一种名为 Robust and Accurate REcommendations for Medication(RAREMed)的新模型。
模型原理:
预训练 - 微调范式:利用预训练 - 微调学习范式来提高罕见病的推荐准确性。
Transformer 编码器:RAREMed 采用具有统一输入序列方法的 Transformer 编码器,用于捕捉疾病和医疗程序代码之间的复杂关系
自监督预训练任务:引入两个自监督预训练任务,即序列匹配预测(Sequence Matching Prediction,SMP)和自我重建(Self Re - construction,SR),以学习专门的药物需求和临床代码之间的相互关系。
4. 实验结果
在两个真实世界数据集上的实验结果表明,RAREMed 能够为罕见病和常见疾病患者提供准确的药物组合,从而缓解药物推荐系统中的不公平问题。
5. 代码获取
该模型的实现可以通过https://github.com/zzzhUSTC2016/RAREMed获取。
这篇论文主要聚焦于解决药物推荐系统在罕见病患者和常见疾病患者之间存在的不公平问题,提出了一种创新的模型并通过实验验证了其有效性。
KEYWORDS
Medication recommendation(药物推荐); Electronic health record(电子健康记录); Fairness(公平性); Rare disease(罕见病)
1. INTRODUCTION
背景与动机
药物推荐系统的重要性日益凸显,因为它可以帮助减少用药错误和不良药物相互作用,对患者健康有积极影响。
目前的药物推荐方法主要集中在利用患者当前和以往的临床信息来提高推荐的准确性。
问题提出
现有方法存在公平性问题,因为电子健康记录中的临床代码分布高度偏态—EHR是患者就诊期间疾病、手术、药物和其他临床数据的数字汇编。如图1(a)所示,一小部分代码具有高流行率,而长尾部分则包含两个真实世界EHR数据集中低发生率的疾病。因此,如图1(b)所示,最常见组别的患者相比最罕见组别的患者,获得的推荐准确性要高得多。导致常见疾病患者得到的推荐比罕见病患者更准确。
这种不公平性会影响药物推荐系统的可靠性和实用性,因此需要解决。
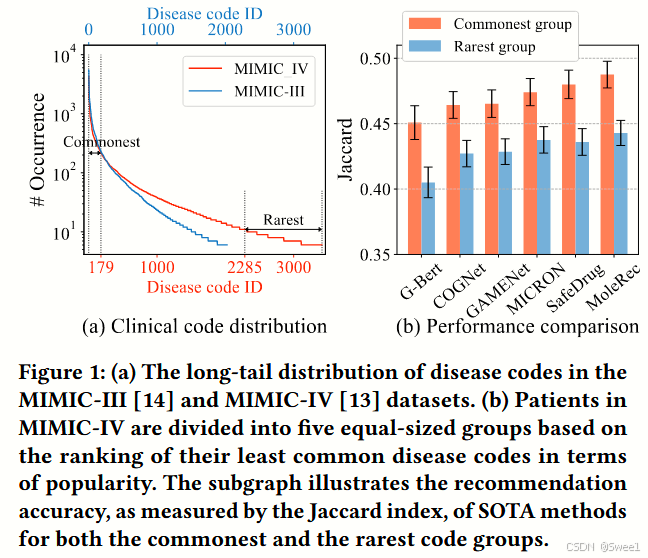
(a)展示了 MIMIC - III 和 MIMIC - IV 数据集中疾病代码的长尾分布。
(b)MIMIC - IV 中的患者根据其最不常见疾病代码的流行度排名被分成五组,每组人数相同。子图展示了通过杰卡德指数(Jaccard index)衡量的最先进方法(SOTA methods)在最常见和最罕见疾病代码组中的推荐准确性。
Jaccard 值用于衡量两个集合的相似度。在这个图表中,可能是用于衡量算法预测结果与实际结果的相似程度。Jaccard 值越高,表示算法的表现越好。
研究目标
关键目标是提高对罕见病患者的药物推荐预测准确性,以促进药物推荐的公平性.然而,对罕见病进行准确的药物推荐存在诸多困难:
- 稀缺的高质量数据
问题描述:由于罕见病本身发病率极低,电子健康记录(EHR)中与罕见病相关的临床数据非常匮乏。这种高质量数据的稀缺严重阻碍了对罕见病药物推荐模式的准确识别。 - 复杂的疾病 / 治疗关联
问题描述:与常见疾病不同,罕见病通常表现为症状和临床事件的复杂组合,这使得明确可靠的疾病关联变得困难。此外,疾病与治疗程序之间的复杂关系也使合适的药物选择变得模糊 —— 某些治疗方法可能在多种病情下通用,但适用性会因疾病严重程度而异。 - 定制化的药物需求
问题描述:罕见病的非典型病理生理学通常需要更精准靶向的药物干预。另一方面,罕见病患者往往有更复杂的治疗方案,这就需要定制化的药物推荐。
然而,在公平用药推荐中实施预训练-微调整带来了挑战,并将这些挑战总结为两个关键问题:
如何构建一个能充分捕捉患者临床信息的表达性编码器?这个编码器需要能够处理罕见病的复杂性,确保药物推荐是基于对患者病情的全面理解。在药物推荐系统中,患者的临床信息是至关重要的输入数据。由于罕见病本身的复杂性和多样性,传统的编码器可能无法有效捕捉这些信息。因此,需要设计一种能够充分理解和处理罕见病相关临床数据的编码器,以确保药物推荐的准确性和可靠性。
如何设计最佳的预训练目标来学习罕见病的专门药物需求以及疾病、诊疗过程和药物之间的相互关系?在预训练 - 微调的框架下,预训练目标的设计直接影响模型对罕见病的学习效果。罕见病通常具有独特的药物需求,并且其与诊疗过程和其他药物之间的关系可能非常复杂。因此,需要设计出能够有效学习这些特殊需求和关系的预训练目标,以便模型在微调阶段能够更好地为罕见病患者提供准确的药物推荐。
作者在研究工作中的主要贡献:
1.解决药物推荐中的不公平问题
据作者所知,这是第一项解决药物推荐中不公平问题的研究。在药物推荐中,患有罕见病的患者往往无法获得准确的推荐。
2.提出 RAREMED 模型
作者提出了一种新颖的药物推荐模型,称为 RAREMED。该模型结合了预训练技术,用于学习针对罕见病的稳健表示,从而提高药物推荐的准确性并减少不公平现象。
3.实验验证
在两个基准数据集上进行了广泛的实验,结果表明 RAREMED 优于一系列现有最先进的方法。
代码开源,作者将发布源代码,以促进未来的研究。
2.RELATED WORKS
主要讨论了药物推荐相关的研究工作,具体内容如下:
- 药物推荐方法的分类
药物推荐方法大致可分为两类:纵向(longitudinal)方法和基于实例(instance - based)的方法。 - 纵向方法
利用患者的纵向医疗历史:例如 Choi 等人 [6] 采用了一种两级时间注意力机制。
单访数据预训练和多访数据微调:例如 Shang 等人 [28] 在单访数据上预训练他们的模型,并在多访数据上进行微调。
图增强记忆模块和 DDI 图:Shang 等人 [29] 加入了图增强记忆模块和药物 - 药物相互作用(DDI)图来减少不良药物 - 药物相互作用。
考虑药物分子结构:Yang 等人 [39] 考虑了药物分子结构用于药物安全。
复制 - 预测机制:Wu 等人 [37] 引入了复制 - 预测机制。
基于残差的循环网络:Yang 等人 [38] 提出了基于残差的循环网络。
解决推荐偏差的因果模型:Sun 等人 [31] 提出了一个因果模型来解决推荐偏差。
分子子结构感知注意力方法:Yang 等人 [41] 利用了分子子结构感知注意力方法。
细粒度药物推荐方法:Bhoi 等人 [3] 提出了细粒度药物推荐方法。 - 基于实例的方法
关注患者当前的医疗状况:例如 Zhang 等人 [44] 利用基于疾病代码的循环神经网络(RNN)模型。Wang 等人 [34] 采用深度 Q 学习来捕捉药物之间的相关性和不良相互作用。 - 现有方法的局限性
许多纵向方法严重依赖历史记录,这使得它们不太适合单访患者,或者在这种情况下表现出较低的准确性。
基于实例的方法可能无法充分捕捉患者特定的信息,可能导致准确性降低。
这些方法存在一个共同的问题,即公平性。与罕见病患者相比,常见疾病患者往往能得到更准确的药物预测,这种差异削弱了药物推荐系统的整体性能、可靠性和实用性。3.PROBLEM FORMULATION
公式化表述,具体如下:
电子健康记录(Electronic Health Record, EHR)

患者记录(Record of patient)

药物 - 药物相互作用(Drug - Drug Interaction, DDI)图
药物推荐问题(Medication Recommendation Problem)

公平药物推荐问题(Fair Medication Recommendation Problem)
除了关注整体准确性外,还强调药物推荐的公平性,即为患有常见疾病和罕见疾病的患者都提供准确的推荐。
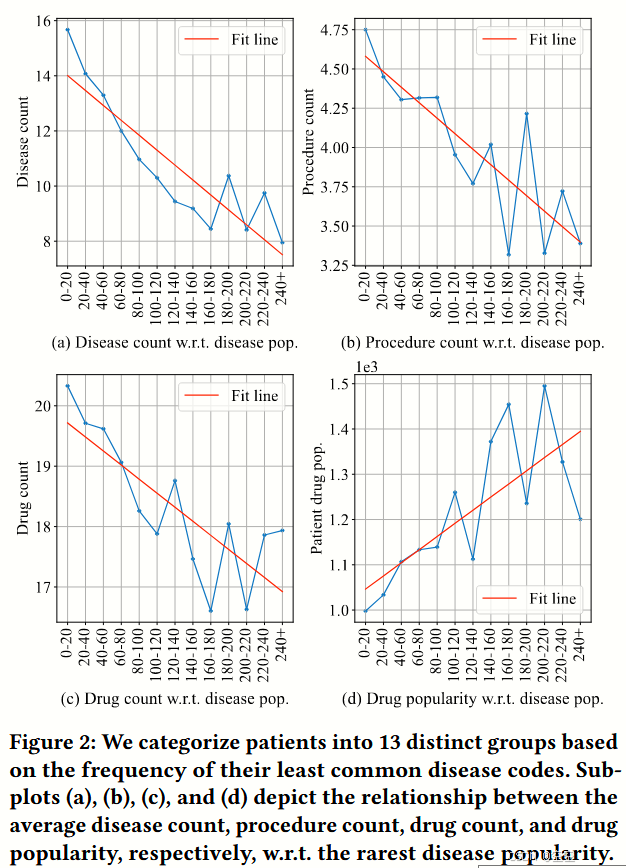
图 2:我们根据患者最不常见疾病代码的频率将患者分为 13 个不同的组。子图 (a)、(b)、© 和 (d) 分别描述了平均疾病数量、诊疗程序数量、药物数量和药物流行度与最罕见疾病流行度之间的关系。
4.PROFILE OF RARE DISEASE PATIENTS
这部分内容主要是对罕见病患者的特征进行分析,具体如下:
研究方法
在这部分内容中,作者使用真实世界的电子健康记录(EHR)数据集 MIMIC - IV 对罕见病患者进行实证分析。具体而言,作者根据患者最罕见疾病代码的流行度将患者分为 13 组,并计算每组的各种指标。
观察结果
观察 1:
内容:图 2 (a) 和 2 (b) 中的数据清楚地显示了疾病数量和诊疗程序数量与患者疾病流行度之间呈负相关。
解释:这表明随着患者疾病的罕见程度增加,他们的临床状况变得更加复杂。因此,罕见病患者的临床状况呈现出更为复杂的组合。
观察 2:
内容:图 2 (c) 和 2 (d) 表明患有更罕见疾病的患者往往有更多的处方药,但这些药物的流行度较低。
解释:这意味着罕见病患者需要更具针对性的药物选择,从而导致更复杂的治疗方案。
总结
作者的分析强调了罕见病患者在临床状况和治疗方案方面的复杂性增加。这些发现突显了对更先进技术(如表达性编码器和预训练技术)的需求,以有效应对罕见病患者面临的独特挑战。
5.OUR METHOD
作者提到他们的 RAREMED 模型框架如图 3 所示。
编码器描述:首先,他们将详细描述编码器(encoder)。这个编码器是专门为有效建模患者临床信息而设计的。
预训练技术:接着,他们将深入探讨如何利用预训练技术来增强输入临床代码的表示。通过这种方式,确保对患有常见疾病和罕见疾病的患者都能提供公平的推荐。
微调过程:最后,作者将详细阐述预训练模型针对药物推荐任务的微调过程。
5.1 Patient Representation
1.背景与动机
在药物推荐的背景下,全面表征患者的临床状况至关重要。传统方法通常使用疾病和诊疗程序代码来表征患者信息,但这些方法存在局限性。例如,有些方法会忽略某些疾病 [28, 44],而其他方法则将疾病和诊疗程序视为独立元素,没有考虑它们之间的复杂关联 [29, 37 - 39, 41],导致模型在捕捉数据复杂性方面表达能力较弱。
2.方法描述
为了解决这些问题,作者提出将疾病和诊疗程序代码作为一个统一序列,并利用 Transformer 编码器生成患者临床状况的全面表征。

3.嵌入层增强
为了增强标准标记嵌入层,作者引入了两种额外的嵌入:段嵌入(segment embedding)和相关性嵌入(relevance embedding)。
段嵌入用于区分输入代码的两类,即疾病和诊疗程序,使模型能够区分不同类型的医疗信息。
相关性嵌入用于捕捉不同疾病和诊疗程序的不同重要性。作者根据输入代码对患者临床状况的相关性对其进行排序,并引入两个可学习的相关性嵌入矩阵
e
i
d
e^d_i
eid和
e
j
p
e^p_j
ejp,分别表示第种
i
i
i疾病和第
j
j
j种诊疗程序代码的相关性嵌入
4.Transformer 编码器处理
最后,Transformer 编码器处理嵌入后的输入序列,产生最终的患者表征
r
r
r:

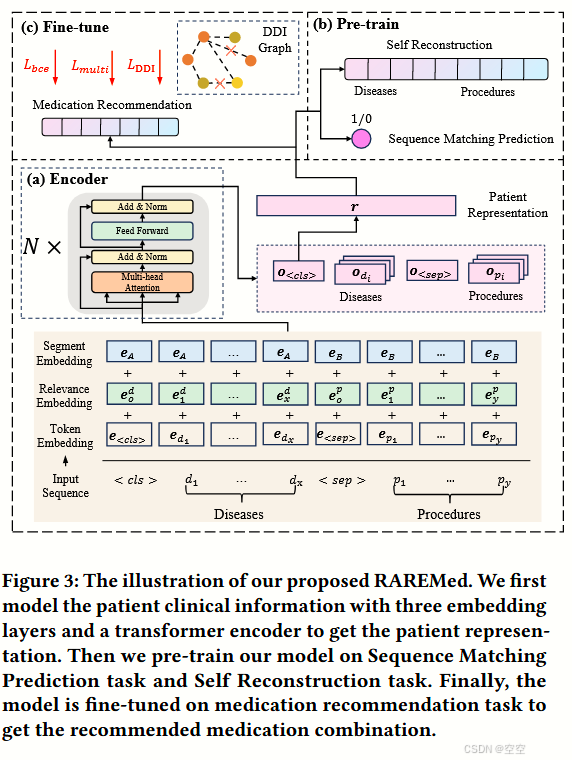
图 3:我们提出的 RAREMED 模型的示意图。我们首先用三层嵌入层和一个 Transformer 编码器对患者临床信息进行建模,以获得患者表征。然后,我们在序列匹配预测任务和自我重建任务上对我们的模型进行预训练。最后,在药物推荐任务上对模型进行微调,以获得推荐的药物组合。
5.2 Pre-training
- 预训练任务的目的
为了增强临床代码的表示,尤其是针对罕见病相关的临床代码,作者引入了两个自监督预训练任务用于患者编码器。这些任务旨在利用临床代码内的固有模式和关系,使模型能够更好地捕捉各种临床状况的细微差别和复杂性。通过在这些任务上进行预训练,目标是促进获取能够更有效地捕捉各种临床状况(包括罕见病情况)复杂性的上下文表示。 - Task 1:序列匹配预测(Sequence Matching Prediction, SMP)
目标:该任务的目标是更有效地捕捉疾病和诊疗程序代码之间错综复杂的关联。具体而言,旨在训练模型辨别疾病和诊疗程序序列是否属于同一患者。这一任务对于 RAREMED 更好地理解不同临床代码之间的上下文依赖关系并提高其捕捉患者临床状况内在联系的能力至关重要。
实现方法:为实现这一目标,对于每个输入序列对 ( d i , p i ) (d_i,p_i) (di,pi)通过随机将疾病 d i d_i di或 p i p_i pi诊疗程序序列替换为来自不同患者的相应样本,创建一个非配对示例。随后,使用二元交叉熵(Binary Cross - Entropy, BCE)损失训练模型,以区分配对和非配对输入:
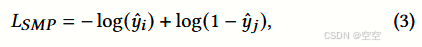

3.Task2:自我重建(Self Reconstruction,SR)。
考虑到该领域中定制化的药物需求,患者表征保留输入序列中所有成分的知识是至关重要的,特别是罕见临床代码。在这个任务中,训练 RAREMED 从建模的患者表征 r r r中重建输入临床代码序列。这有助于 RAREMED 捕捉并保留临床代码中的关键信息,确保全面表征患者的临床状况。
重建损失(Reconstruction Loss)
损失函数定义:重建损失用 L S L_S LS R _R R表示,其定义如下:

5.3 Fine-tune and Inference
1.在对 RAREMED 进行两项任务的预训练后,对模型进行微调以实现准确和公平的药物推荐。为了预测药物,集成了一个多标签分类层,并将患者表征作为输入。
具体公式为:

2.微调目标函数





6.EXPERIMENTS
RQ1(研究问题 1):
问题:所提出的 RAREMED 方法与现有的药物推荐方法相比,性能如何?
解释:作者将比较 RAREMED 与其他现有药物推荐方法的性能,以评估 RAREMED 的优势。
RQ2(研究问题 2):
问题:RAREMED 是否能有效减轻药物推荐中的不公平现象?
解释:作者将研究 RAREMED 是否能够解决药物推荐中存在的不公平问题,例如对罕见病患者的不公平对待。
RQ3(研究问题 3):
问题:RAREMED 的各个组成部分如何影响其在准确性和公平性方面的性能?
解释:作者将分析 RAREMED 模型中各个组件对模型整体准确性和公平性的影响,以了解每个组件的重要性。
RQ4(研究问题 4):
问题:哪些影响因素(例如 DDI 图)会显著影响 RAREMED 的推荐性能?
解释:作者将探讨哪些因素会对 RAREMED 的推荐性能产生显著影响,例如药物 - 药物相互作用(DDI)图等。
6.1 Experimental Setup
数据集(Datasets)
数据来源:使用了来自两个真实电子健康记录(EHR)数据集的数据,即 MIMIC - III 和 MIMIC - IV,以及从 TWOSIDES 数据库中提取的药物 - 药物相互作用(DDI)数据。
数据处理:按照之前的研究工作,对数据集进行了处理,并将数据随机分为训练集、验证集和测试集,比例为 4:1:1。处理后数据集的统计信息在表 1 中详细列出。
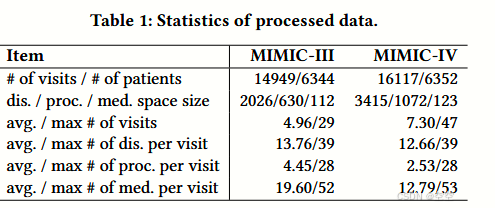
这些统计数据可以帮助研究人员了解两个数据集在规模、多样性和复杂性方面的差异,从而在进行医疗相关研究时选择合适的数据集。
评估协议(Evaluation Protocol)
评估指标:使用广泛接受的指标来评估所有方法的整体性能,包括 Jaccard 系数、精确率 - 召回率曲线下面积(PRAUC)、F1 分数、DDI 率,以及推荐药物的平均数量(#MED),从而对推荐性能进行全面评估。
Jaccard 系数(Jaccard coefficient):用于衡量预测药物集合与实际药物集合的交集与并集的比例,公式为:
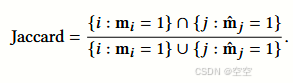
精确率 - 召回率曲线下面积(PRAUC):通过计算不同召回率下的精确率,得到曲线下面积,公式为: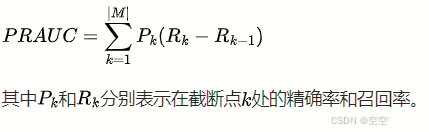
F1 分数(F1 - score):结合精确率和召回率,公式为:

DDI 率(DDI rate):用于衡量推荐药物组合中药物 - 药物相互作用的比例。
推荐药物的平均数量(#MED):表示推荐给患者的药物的平均数量。
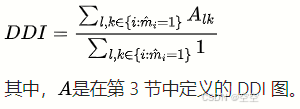

Compared Methods.

除了上述提到的药物推荐方法外,我们还实现了一个专门用于组间比较中公平推荐的基线方法:
重平衡方法(Rebalancing)
目的:解决数据不平衡的问题,以实现公平推荐。
方法细节:
使用重采样技术(resampling technique)[9, 15]。
具体操作:
计算每个疾病代码的逆倾向得分(Inverse Propensity Score, IPS)[27, 40]。
根据患者最罕见疾病的 IPS 得分,为每个患者分配一个权重分数。
在每个训练周期,从训练数据中进行有放回的随机采样,选择某个患者的概率与其分配的患者权重成正比。
实验设置:在没有预训练的 RAREMED 上进行该方法的实验。
在研究中没有评估 4SDrug、DrugRec 和 REFINE 这几种方法。原因是这些方法依赖于额外的症状信息(在参考文献 [31, 32] 中提到),或者无法获取其源代码(参考文献 [3])。
Implementation Details.
超参数确定:所有模型的超参数是根据它们在验证集上的表现来确定的。
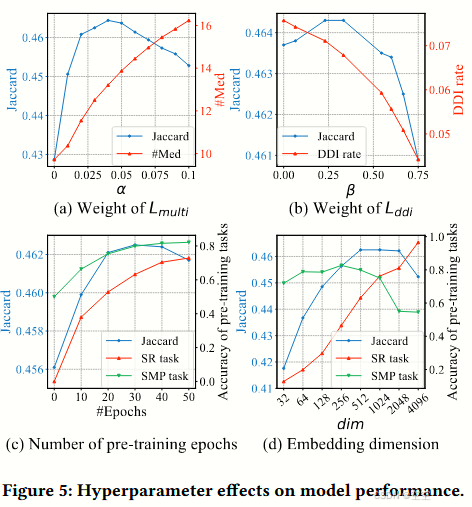
预训练过程:RAREMED 在训练集上按顺序进行预训练,首先在序列匹配预测(SMP)任务上进行,然后在自我重建(SP)任务上进行,每个任务都进行 30 个 epochs。
模型架构:模型中的 Transformer 编码器由 3 层组成,每层有 4 个注意力头,嵌入维度设置为 512。
损失函数权重:损失函数中的权重参数和分别设置为 0.03 和 0.7。
优化器:使用 AdamW 优化器(参考文献 [20])进行训练,学习率为
1
e
−
5
1e-5
1e−5,权重衰减为 0.1。
6.2 Overall Performance Comparison (RQ1)
实验设置
单访问设置(Single - visit setting):将每次访问视为一个独立的患者,不考虑历史记录。
多访问设置(Multi - visit setting):一个患者可能有多次访问,在为第二次及后续访问推荐药物时可以使用历史记录。这种设置是为了与纵向方法 [29, 37 - 39, 41] 进行公平比较。
观察结果
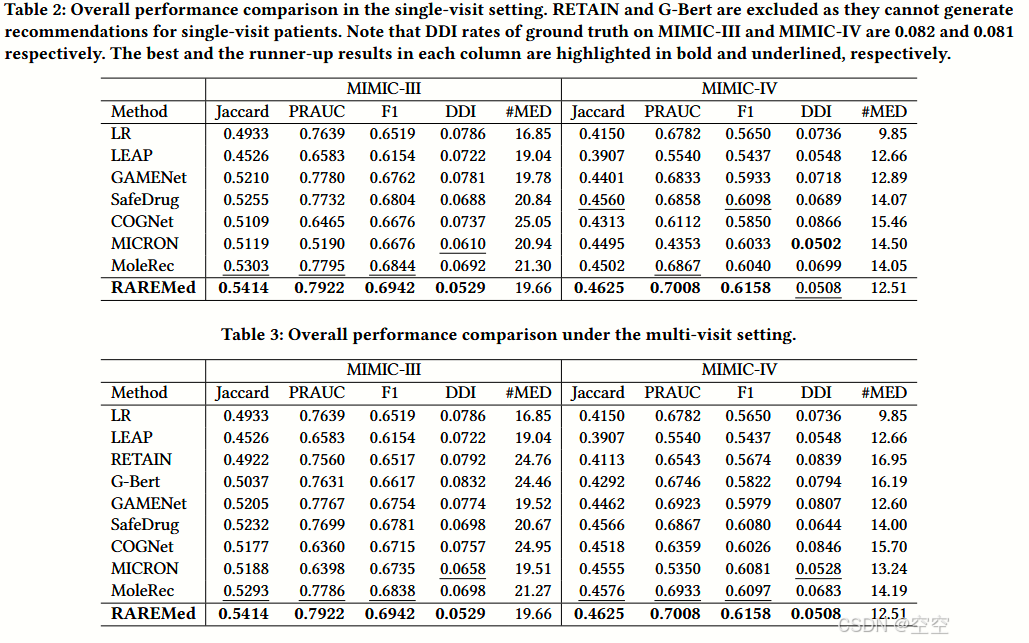
基线比较(Baseline Comparison)
LR 和 RETAIN:它们原本不是为药物推荐任务设计的,表现较差。LR 忽略了临床代码之间的相互作用,而 RETAIN 未能充分捕捉当前患者的状况。
LEAP 和 G - Bert:由于没有考虑诊疗程序序列,在这个领域表现不佳。
COGNet 和 MICRON:虽然以特定方式利用了历史信息,但在单访问设置下性能显著下降。
GAMENet、SafeDrug 和 MoleRec:通过整合外部知识(如电子健康记录图和药物分子结构),取得了较好的性能。但有趣的是,在使用 MIMIC - III 的多访问设置下,这三种方法的表现比单访问设置更差,突显了利用历史信息的复杂性。
RAREMED 的准确性(Accuracy of RAREMed)
RAREMed 在准确性方面超越了所有基线方法,在 MIMIC - III 和 MIMIC - IV 数据集上都表现出更高的 Jaccard 系数、F1 分数和精确率 - 召回率曲线下面积(PRAUC)。这种优势不仅在单访问场景(表 2)中可见,在多访问场景(表 3)中也同样存在。值得注意的是,RAREMED 在不依赖历史记录的情况下实现了这种改进,这突显了药物推荐框架的有效性,这可归因于表达性编码器的精心设计和所采用的预训练任务的有效性。
RAREMED 的安全性(Security of RAREMed)
与真实水平和基线方法相比,RAREMED 确保了最低的药物 - 药物相互作用(DDI)率(除少数例外情况)。这展示了该系统在准确性和安全性之间有效平衡的能力,这一话题将在 6.5 节中进一步探讨。
表 2:单次访问设置中的整体性能比较。由于 RETAIN 和 G - Bert 无法为单次访问患者生成推荐,因此未将它们纳入比较。请注意,在 MIMIC - III 和 MIMIC - IV 上的真实数据的药物 - 药物相互作用(DDI)比率分别为 0.082 和 0.081。每列中最佳结果和次佳结果分别用粗体和下划线突出显示。
表 3:多访问设置下的整体性能比较。
6.3 Group-wise Performance Comparison (RQ2)
检查模型在不同疾病流行程度患者群体中的性能。通过图 4 展示了 RAREMED 和基线方法的性能,得出以下观察结果:
基线方法产生不公平推荐(Baseline Methods Yield Unfair Recommendations)
传统的药物推荐方法在疾病代码频率降低时,准确性会显著下降,如图 4 (a) 所示。
这导致不同群体间 Jaccard 系数的标准差较高,如图 4 (b) 所示。
例如,G - Bert 虽然利用了预训练技术,但在罕见病患者中难以达到足够的准确性,可能是因为在预训练期间忽略了诊疗程序代码,无法全面捕捉患者的临床信息。
此外,重平衡(Rebalancing)方法虽然旨在解决公平性问题,但在公平性和整体性能方面仍不如 RAREMED。
RAREMED 有效解决公平性问题(RAREMED Effectively Addresses Fairness Concerns)
如图 4 (a) 所示,RAREMED 在罕见病患者中表现出优越的性能,同时对常见疾病患者也保持了有效性。
并且,RAREMED 在不同患者群体间的表现差异较小,如图 4 (b) 所示。这表明 RAREMED 在获取稳健的表征方面具有优势,特别是对于罕见临床代码,并且能够为罕见病患者提供公平的药物推荐。
预训练在有偏差数据集中展示出有效性(Pre - training Demonstrates Effectiveness on Biased Datasets)
图 4 © 和 (d) 中的结果表明,预训练策略在常见和罕见群体上都有积极影响。
在 MIMIC - III 数据集中,疾病分布较为倾斜,预训练策略在 30 个预训练周期后持续提升各群体的性能。
在 MIMIC - IV 数据集中,疾病分布更加有偏差且更具挑战性,RAREMED 显著提升了最罕见群体的性能,有效减轻了不公平性。在这种更有偏差的数据集中,整体准确性的大幅提升也很显著。
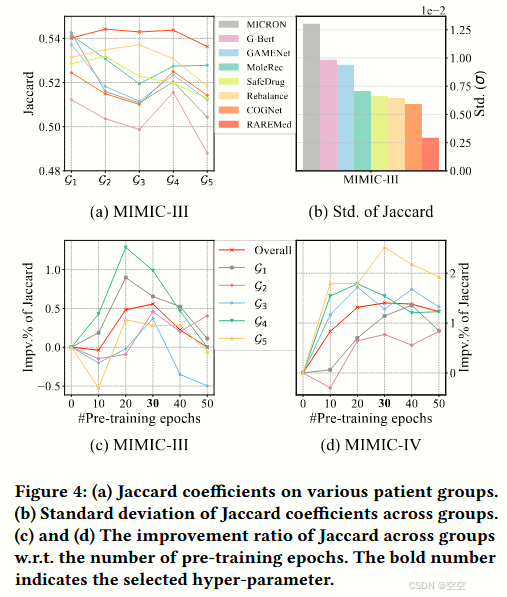
图 4:(a) 不同患者组的杰卡德系数。
(b) 各患者组间杰卡德系数的标准差。
© 和 (d) 杰卡德系数相对于预训练轮数在各组间的提升比率。加粗数字表示所选取的超参数。
6.4 Ablation Study (RQ3)
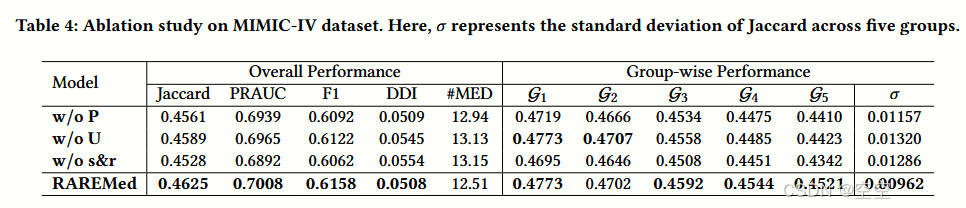
对 RAREMED 模型中各个组件的有效性进行评估,通过消融研究(ablation study)来实现,具体如下:
消融模型
“w/o P”:移除两个预训练任务,导致编码器和嵌入层的参数随机初始化。
“w/o U”:禁用统一编码器,分别学习疾病和诊疗程序的两个编码器,然后连接输出。此设置保留了两个预训练任务。
“w/o s&r”:禁用段嵌入和相关性嵌入层,患者表征仅依赖于标记嵌入。
观察结果(基于 MIMIC - IV 数据集,文中提到省略 MIMIC - III 的结果,因为结论相同)
“w/o P”
正如预期的那样,“w/o P” 变体性能下降,突显了预训练任务的重要性。
RAREMED 在所有五组中都优于 “w/o P”,这表明预训练策略不仅增强了对罕见病的性能,还保留了原始模型对其他疾病的有效性。
RAREMED 的性能提升归因于通过预训练阶段获得的增强编码器,使其能够掌握复杂的疾病 / 诊疗程序关联并生成更全面的患者表征。
“w/o U”
RAREMED 优于 “w/o U” 变体,特别是在公平性方面,进一步强调了捕捉和理解疾病与诊疗程序之间关联对于公平药物推荐的重要性。
“w/o s&r”
RAREMED 也优于 “w/o s&r” 变体。
值得注意的是,“w/o s&r” 变体在不同患者群体中的性能波动显著。
这些结果突显了段嵌入和相关性嵌入层在捕捉疾病和诊疗程序之间复杂关系(特别是对于罕见病)中的关键作用。
6.5 Hyperparameter Studies (RQ4)
这部分内容主要探讨了超参数对 RAREMED 在 MIMIC - IV 数据集上有效性的影响,具体如下:





7 CONCLUSION
在本文中,我们提出了 RAREMED,这是一种新颖的药物推荐模型,旨在解决药物推荐系统中的公平性问题。RAREMED 通过专注于提高罕见病患者的推荐准确性,利用两个自监督预训练任务来学习特定的药物需求和相互关系。该模型还采用统一的输入序列方法来捕捉疾病和诊疗程序代码之间的复杂关系。在真实数据集上的实验结果证明了 RAREMED 在为罕见病和常见病患者提供准确药物推荐方面的有效性,从而减轻了不公平性。
在未来的研究中,我们打算进一步探索利用患者的历史记录和其他临床信息,如人口统计学数据、实验室数据、病历记录和影像资料,以提高药物推荐的准确性。此外,在预训练阶段整合更多外部知识,并探索跨不同电子健康记录(EHR)数据集的迁移学习也是很有前景的进一步发展方向。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











