




 本文介绍了如何利用Python的Requests库分别进行百度翻译API的POST请求和豆瓣电影排行榜数据的GET请求。对于百度翻译,重点在于理解POST请求中的FromData参数;而对于豆瓣电影排行榜,由于数据在二次请求中,我们需要关注XHR筛选出所需数据,并设置合适的User-Agent进行反爬处理。
本文介绍了如何利用Python的Requests库分别进行百度翻译API的POST请求和豆瓣电影排行榜数据的GET请求。对于百度翻译,重点在于理解POST请求中的FromData参数;而对于豆瓣电影排行榜,由于数据在二次请求中,我们需要关注XHR筛选出所需数据,并设置合适的User-Agent进行反爬处理。
一、使用Requests获取百度翻译的结果
在地址栏搜索百度翻译打开,然后把 .com后面的参数全部删掉回车,按下 F12 打开抓包工具 ,变成如下页面:
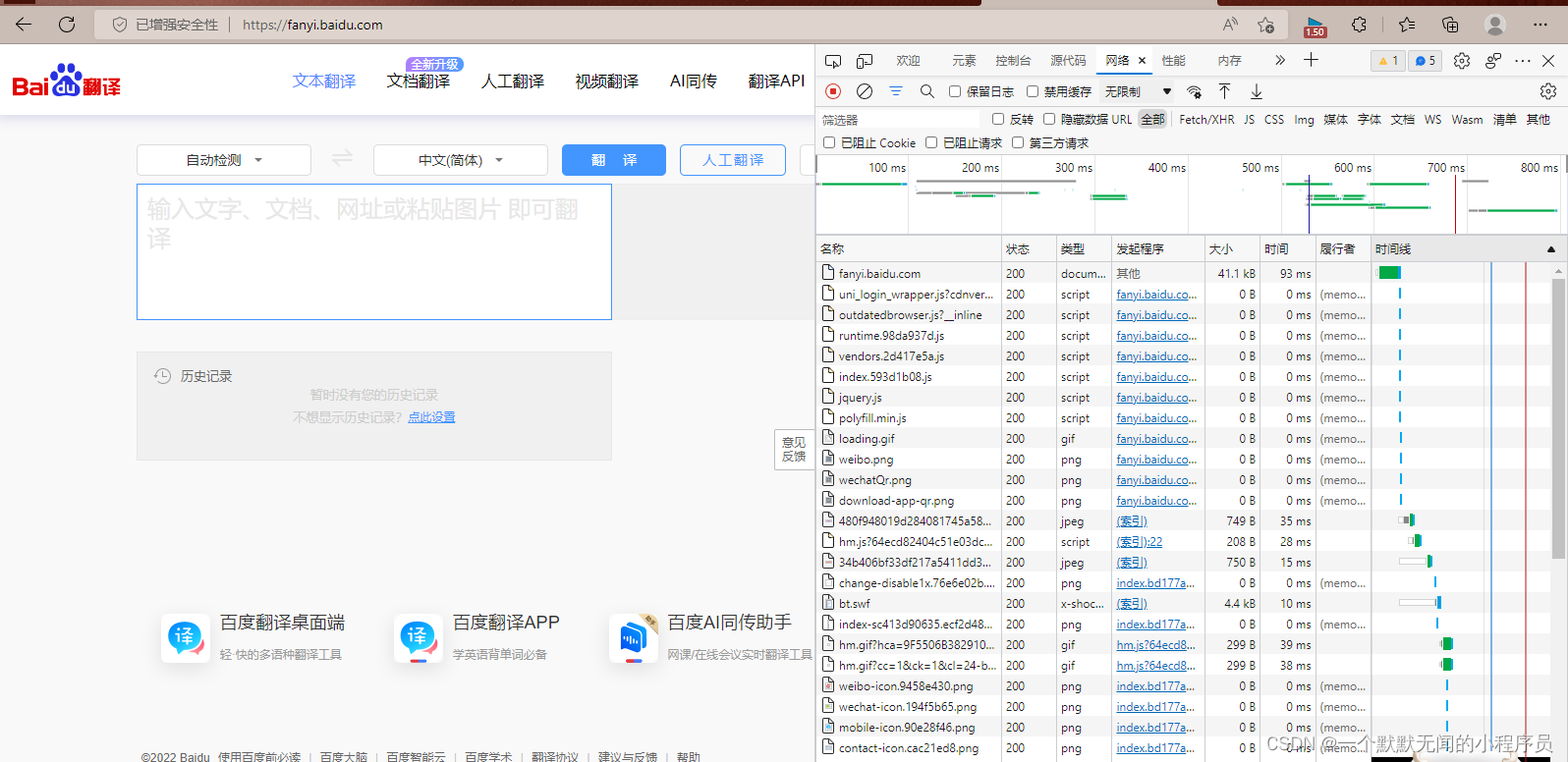
接着在翻译栏搜索 cat (注意要把输入法切换成英文,不然还是抓不到),打开抓包工具中的 sug ,切换到预览界面,就可以看到我们相关翻译结果。
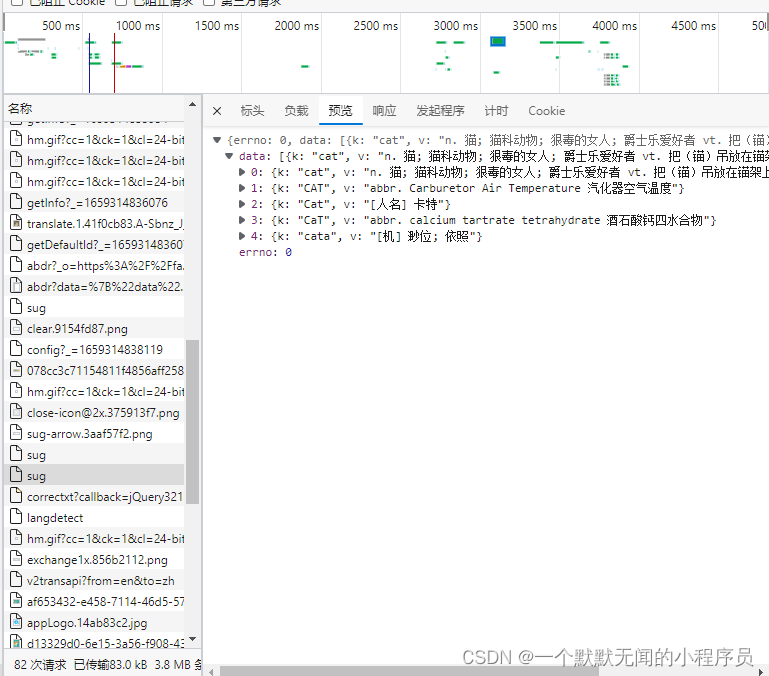
并且我们可以看到该网页使用的请求方式是 POST ,区别于 GET 请求方式的 Query String Parameters,POST发送的参数为 From Data,即我们要搜索的内容。发送 POST 请求,发送的数据必须放在字典中,通过data参数进行传递。

代码和上节的比较类似,也很简单,就不做具体分析了。
import requests
url = "https://fanyi.baidu.com/sug"
s = input("输入你要翻译的英文单词")
dat = {
"kw":s
}
# 发送post请求,发送的数据必须放在字典中,通过data参数进行传递
resp = requests.post(url, data=dat)
print(resp.json()) # 将服务器返回的内容直接处理成json() =>dict
运行结果如下:

二、爬取豆瓣电影排行榜数据
在地址栏搜索豆瓣电影,打开豆瓣电影排行榜剧情分类,按下 F12 打开抓包工具。
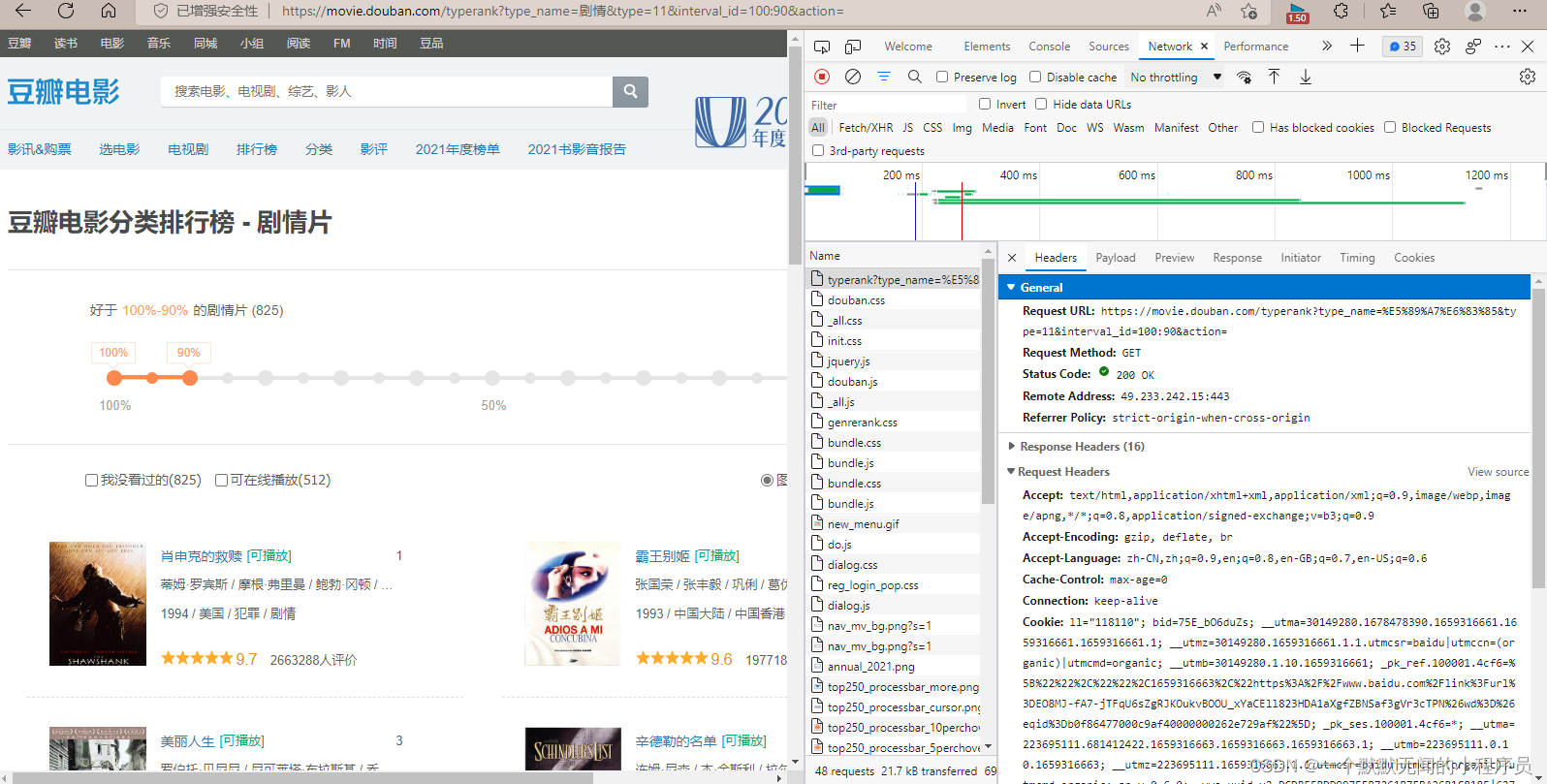
因为豆瓣电影排行榜的网页是使用的客户端渲染,数据是第二次请求的,所以我们在预览界面只能看到它的框架,而看不到具体数据。在我们的抓包工具中,有一个叫 XHR ,它可以帮我们做一定的筛选
,可以筛选出第二次请求的数据。我们可以看到筛选出来的三项中最后一项包含数据最多,是我们需要的,接下来我们便将这些数据爬取下来。
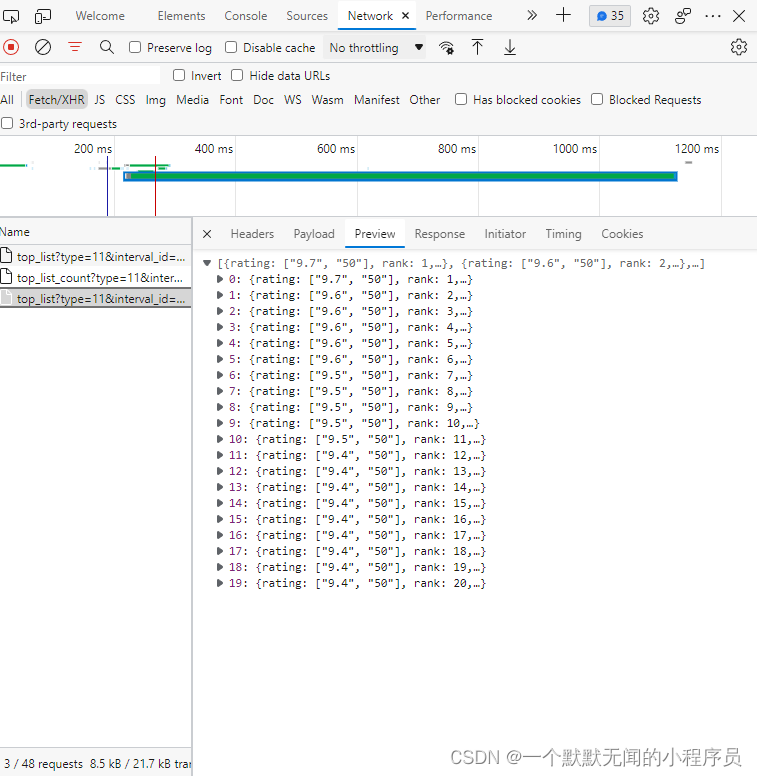
打开 Headers 界面,可以看到与前面的 URL 不同,该网页的 URL 是一长串,在?前面的是它的 URL ,?后面的是它的参数。

往下划,我们可以看到在 Query String Parameters中,参数已经被打包整理好了。
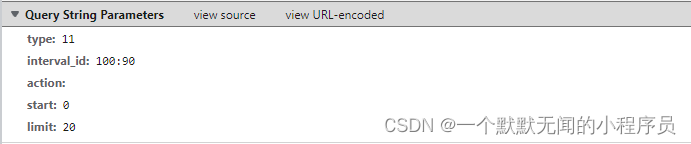
因此我们可以把这些参数打包放在一个字典里,避免 URL 过于冗长。(注意相关参数一定要用双引号括起来)
同样我们也要进行一个小小的反爬处理,即将 headers 的内容装填成 User-Agent 。
代码如下:
import requests
url = "https://movie.douban.com/j/chart/top_list"
# 重新封装参数
param = {
"type": "24",
"interval_id": "100:90",
"action": "",
"start": "0",
"limit": "20"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.7062 SLBChan/30"
}
resp = requests.get(url=url, params=param, headers=headers)
print(resp.json())


















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











