







一、MySQL
1.1 MySql 体系结构
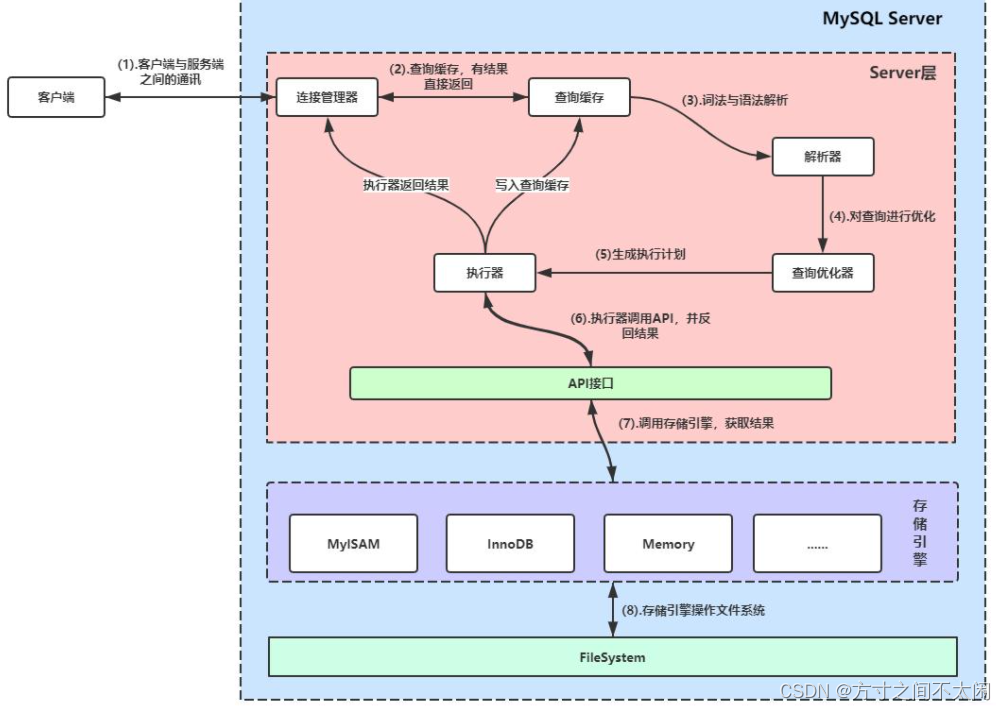
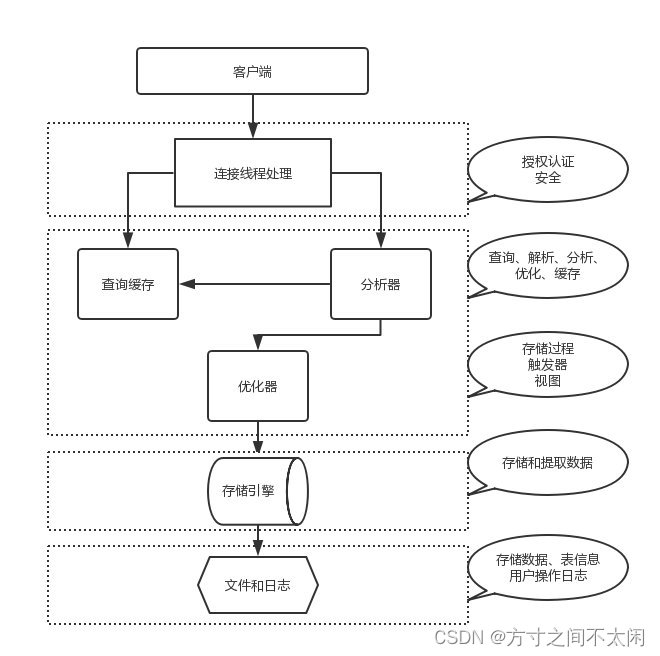
MySQL 架构总共四层,在上图中以虚线作为划分。
1. 最上层的服务并不是 MySQL 独有的,大多数给予网络的客户端/服务器的工具或者服务都有类似的架构。比如:连接处理、授权认证、安全等。
2. 第二层的架构包括大多数的 MySQL 的核心服务。包括:查询解析、分析、优化、缓存以及所有的内置函数(例如:日期、时间、数学和加密函数)。同时,所有的跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。
3. 第三层包含了存储引擎。存储引擎负责 MySQL 中数据的存储和提取。服务器通过 API 和存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明化。存储引擎 API 包含十几个底层函数,用于执行“开始一个事务”等操作。但存储引擎一般不会去解析 SQL(InnoDB 会解析外键定义,因为其本身没有实现该功能),不同存储引擎之间也不会相互通信,而只是简单的响应上层的服务器请求。
4. 第四层包含了文件系统,所有的表结构和数据以及用户操作的日志最终还是以文件的形式存储在硬盘上。
1.1.1 SQL 语句的执行流程
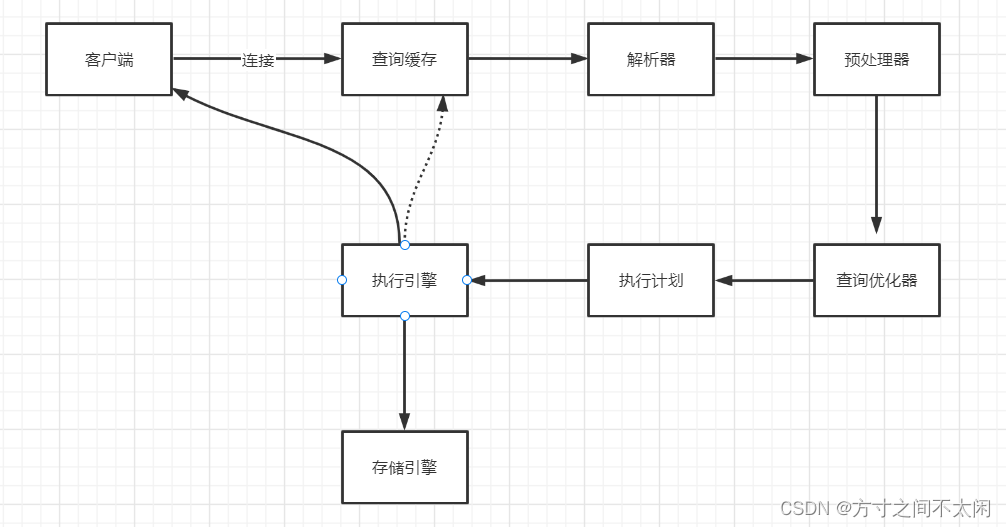
1. 建立连接
连接数默认 151 最大 10000。
2. 查询缓存
默认关闭 8.0 删除 比较鸡肋,因为缓存触发条件苛刻,eg:查询语句完全一样;数据库有数据更新缓存会清空。
3. 解析器
词法解析 将 sql 打散成一个一个的词。
语法解析 对 sql 进行语法检验;同时将词法解析成的词语 按照语法规则生成特定的数据结构 ----解析树。
4. 预处理器
检查生成的解析树,处理解析器无法解析的语义,比如表名、列名是否存在,检查名字和别名保证没有歧义 同时会生成新的解析树。
5. 查询优化器
一条 Sql 语句可以有很多种执行方式,但是返回的结果是一样的。查询优化器的目的就是基于解析树生成不同的解析计划,从中选择一个最优的执行计划;MYSQL
里面使用的是基于开销的优化器,那种执行计划开销最小就是用哪种。
比如:多表关联查询,基准表的选择;多个索引可以使用时候,选择哪个索引;
6. 执行计划
优化器优化解析树会得到另一个数据结构的数据-----查询执行计划使用 EXPLAIN 可以查看。
7. 执行引擎
使用执行计划操作存储引擎,通过存储引擎提供的 API 完成,得到结果最后返回给客户端;
8. 存储引擎
存储数据的形式。
MYISM 适用只读的场景 支持表锁、记录数据行数、插入和查询较快。
INNODB 支持表锁、行锁、外键、事务;支持读写并发,写不阻塞读(MVCC);特殊的索引存放,可以减少 IO,提升查询效率。
MEMORY 适用临时表 数据存在内存中,读写快;数据库崩溃或者宕机,数据消失。
1.1.2 一条更新 SQL 的执行
1. 建立连接,事务开启,查询缓存(可跳过,默认不开启),然后通过解析器词法解析,语法分析,预处理等生成解析树,然后通过查询优化器获得一个开销最小的执行计划,然后通过执行引擎调用 API 接口操作存储引擎获取数据,返回查询结果给 server 的执行器;
2. server 的执行器修改数据页中的一行数据;
3. 记录修改日志到 undo log
4. 记录日志到 redo log
5. 调用存储引擎接口,记录数据页到 buffer pool 中
6. 事务提交;
修改数据的时候会先写入缓冲区的数据页中,因此缓冲区的数据页与磁盘中的数据出现了数据不一致的现象,此时的数据页被称为脏页;将脏页数据更新到磁盘的过程称为刷脏;
1.2 MySQL 存储引擎
1.2.1 存储引擎
MySQL 中的数据用各种不同的技术存储在文件(或者内存)中。
这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。
通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。
例如,如果研究大量的临时数据,你也许需要使用内存存储引擎。内存存储引擎能够在内存中存储所有的表格数据。
这些不同的技术以及配套的相关功能在 MySQL 中被称作存储引擎(也称作表类型)。
MySQL 默认配置了许多不同的存储引擎,可以预先设置或者在 MySQL 服务器中启用。你可以选择适用于服务器、数据库和表格的存储引擎,以便在选择如何存储你的信息、如何检索这些信息以及你需要你的数据结合什么性能和功能的时候为你提供最大的灵活性。
选择如何存储和检索你的数据的这种灵活性是 MySQL 为什么如此受欢迎的主要原因。其它数据库系统 (包括大多数商业选择)仅支持一种类型的数据存储 。
1.2.2 MySQL 支持的存储引擎
MySQL5.6 支持的存储引擎包括:
1. InnoDB
2. MyISAM
3. MEMORY
4. CSV
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











