







一、初识 IO
1.1 什么是 IO 流
I/O 实际上是 input 和 output,也就是输入和输出。而流其实是一种抽象的概念,它表示的是数据的无结构化传递。
1.2 IO 流的作用
就是输入流(读数据),O 就是输出流(写数据)。当我们需要从硬盘,内存或者网络中读写数据时,数据的传输量可能很大,而我们的内存和带宽有限,无法一次性获取大数据量时,就可以通过 IO 流来解决问题。而流,就像河流中的水一样,缓缓地流入大海。
1.3 IO 流的分类
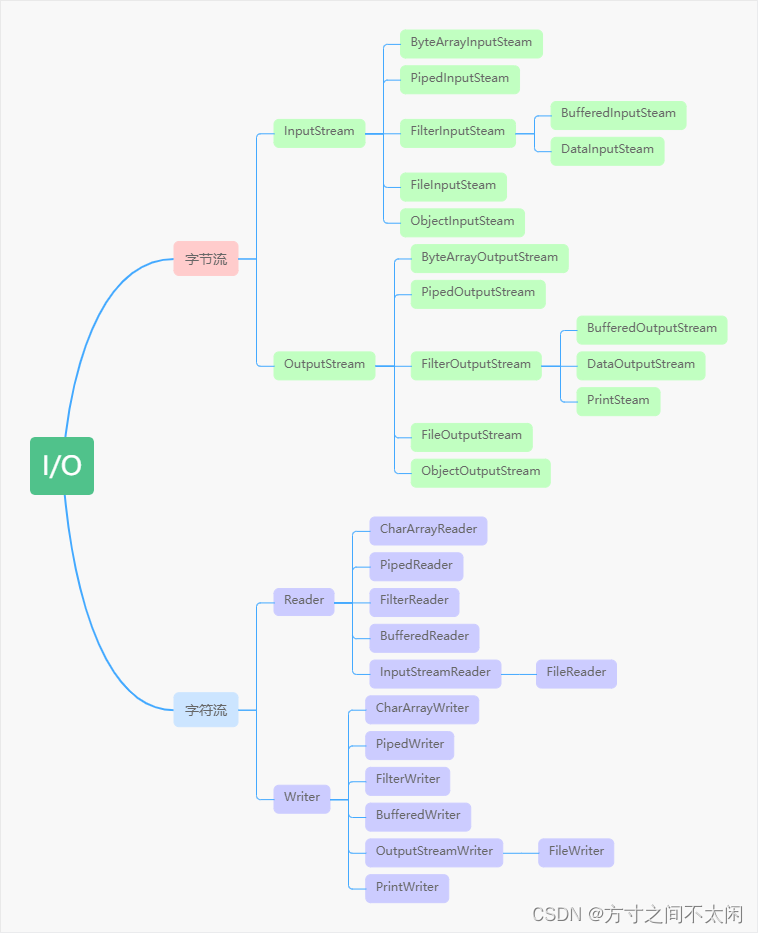
- 从传输数据类型分为:字节流和字符流。
- 从传输方向分为:输入流和输出流。
- 从 IO 操作对象划分:
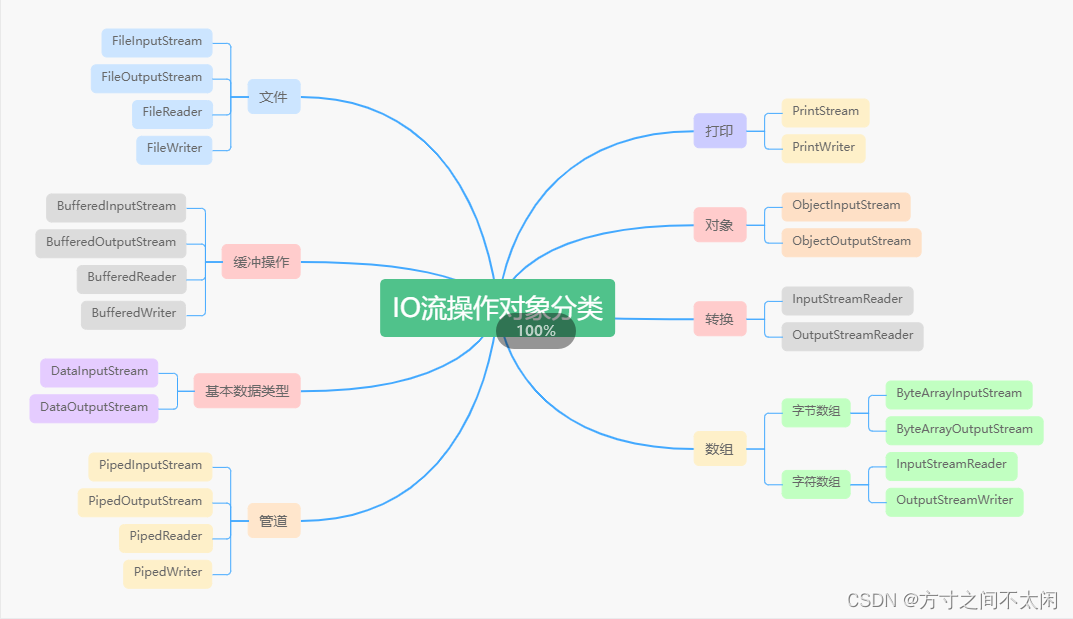
1.4 IO 流实战应用
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class FileInputStreamDemo {
public static void main(String[] args) {
try {
FileInputStream is = new FileInputStream("E:/test.txt");
int i = 0;
i = is.read();
System.out.println((char)i);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果:
J
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class FileInputStreamDemo {
public static void main(String[] args) {
try {
FileInputStream is = new FileInputStream("E:/test.txt");
int len = 0;
byte bur[] = new byte[1024];
while((len = is.read(bur)) != -1) {
System.out.println(new String(bur, 0, len));
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果:
Java IO 流
Hello World!
二、深入分析 Java 中的 IO 流
2.1 IO 流的数据来源
- 硬盘
import java.io.FileInputStream;
public class FileInputStreamDemo {
public static void main(String[] args) throws Exception {
FileInputStream is = new FileInputStream("E:/test.txt");
int len = 0;
byte bur[] = new byte[1024];
while((len = is.read(bur)) != -1) {
System.out.println(new String(bur, 0, len));
}
}
}
- 内存
import java.io.FileInputStream;
public class FileInputStreamDemo {
public static void main(String[] args) throws IOException {
String str = "Java IO 流";
ByteArrayInputStream is = new ByteArrayInputStream(str.getBytes());
int len = 0;
byte bur[] = new byte[1024];
while((len = is.read(bur)) != -1) {
System.out.println(new String(bur, 0, len));
}
}
}
- 键盘
import java.io.FileInputStream;
public class FileInputStreamDemo
public static void main(String[] args) throws IOException {
InputStream is = System.in;
int len = 0;
byte bur[] = new byte[1024];
while((len = is.read(bur)) != -1) {
System.out.println(new String(bur, 0, len));
}
}
}
- 网络
服务器端
import java.io.*;
import java.net.*;
public class Server {
public static void main(String[] args) {
try {
ServerSocket ss = new ServerSocket(8888);
System.out.println("[启动服务器......]");
Socket s = ss.accept();
System.out.println("[客服端:]" + s.getInetAddress().getHostAddress() + " 已连接到服务器");
BufferedReader br = new BufferedReader(new InputStreamReader(s.getInputStream()));
// 读取客户端发送来的消息
String msg = br.readLine();
System.out.println("[客户端:]" + msg);
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(s.getOutputStream()));
bw.write(msg + "\n");
bw.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}
客服端
import java.io.*;
import java.net.Socket;
public class Client {
public static void main(String[] args) {
try {
Socket s = new Socket("127.0.0.1", 8888);
// 构建IO
InputStream is = s.getInputStream();
OutputStream os = s.getOutputStream();
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(os));
// 向服务器端发送一条消息
bw.write("测试客户端和服务器端通信,服务器收到消息返回到客户端\n");
bw.flush();
// 读取服务器返回的消息
BufferedReader br = new BufferedReader(new InputStreamReader(is));
String msg = br.readLine();
System.out.println("[服务器:]" + msg);
} catch (IOException e) {
e.printStackTrace();
}
}
}
服务器端执行结果:
[启动服务器......]
[客服端:]127.0.0.1 已连接到服务器
[客户端:]测试客户端和服务器端通信,服务器收到消息返回到客户端
客服端执行结果:
[服务器:]测试客户端和服务器端通信,服务器收到消息返回到客户端
2.2 本地磁盘文件操作之 File 类
File 类是 Java 中为文件进行创建、删除、重命名、移动等操作而设计的一个类。它是属于 Java.io包下的类。
2.2.1 File 类基本操作
// 通过给定的父抽象路径名和子路径名字符串创建一个新的 File 实例。
File(File parent, String child);
// 通过将给定路径名字符串转换成抽象路径名来创建一个新 File 实例。
File(String pathname);
// 根据 parent 路径名字符串和 child 路径名字符串创建一个新 File 实例。
File(String parent, String child);
// 通过将给定的 file: URI 转换成一个抽象路径名来创建一个新的 File 实例。
File(URI uri);
遍历目录
import java.io.File;
public class FileUtil {
public static void main(String[] args) {
showDir(1, new File("D:\\Java"));
}
static void showDir(int indent, File file) {
for (int i = 0; i < indent; i++) {
System.out.print('-');
}
System.out.println(file.getName());
if(file.isDirectory()) {
File[] files = file.listFiles();
for (int i = 0; i < files.length; i++) {
showDir(indent + 4, files[i]);
}
}
}
}
2.3 文件的字节输入输出流
import java.io.*;
public class InputStreamDemo {
public static void main(String[] args) throws Exception {
File file = new File("E:\\gupao_logo.png");
FileInputStream fileInputStream = new FileInputStream(file);
FileOutputStream fileOutputStream = new FileOutputStream("E:\\gupao_logo_cp.png");
int len = 0;
byte[] buffer = new byte[1024];
while((len=fileInputStream.read(buffer)) != -1 ) {
fileOutputStream.write(buffer, 0, len);
}
fileInputStream.close();
fileOutputStream.close();
}
}
2.4 基于内存的字节输入输出流
import java.io.*;
public class MemoryDemo {
static String str = "hello world!";
public static void main(String[] args) {
// 从内存中读取数据
ByteArrayInputStream inputStream = new ByteArrayInputStream(str.getBytes());
// 写入到内存中
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
int len = 0;
while((len = inputStream.read()) != -1) {
char c = (char)len;
outputStream.write(Character.toUpperCase(c));
}
System.out.println(outputStream.toString());
}
}
2.5 基于缓存流的输入输出
import java.io.*;
public class BufferedDemo {
public static void main(String[] args) {
try {
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("E:\\test.txt"));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("E:\\tst.txt"));
int len = 0;
byte[] bytes = new byte[1024];
while((len = bufferedInputStream.read(bytes)) != -1) {
System.out.println(new String(bytes, 0, len));
bufferedOutputStream.write(bytes, 0, len);
bufferedOutputStream.flush();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}2.6 flush 方法
flush()这个东西,其实在很久以前的网络传输中就有了,那个时候为了效率,服务器和客户端传输数据的时候不会每产生一段数据就传一段数据,而是会建一个缓冲区,在缓冲区满之后再往客户端传输数据。有时候会有这样的问题,当数据不足以填充缓冲区,而又需要往客户端传数据,为了解决这个问题,就有了 flush 的概念,将缓冲区的数据强迫发送。
如果把 flush 换成 close 是否可行呢?
答案是可以的。
public class BufferedOutputStream extends FilterOutputStream {
......
}
BufferedOutputStream 没有实现 close()方法,所以会直接调用 FilterOutputStream 的 close(),而 FilterOutputStream 的 close()方法会调用 flush()来输出缓冲区数据。
实际开发中关于 IO 操作的,都强调最后要调用 close()方法。
2.7 序列化和反序列化
2.7.1 序列化与反序列化的概念
- Java 序列化是指:将对象转化成一个字节序列(二进制数据)的过程。
- 将序列化对象写入文件之后,可以从文件中读取出来,并且对它进行反序列化。
- Java 反序列化是指:将一个对象的字节序列恢复成 Java 对象的过程。
- 一个平台中序列化的对象,可以在另一个平台中进行反序列化,因为这个过程是在 JVM 中
独立完成的,可以依赖于 Java 的可移植性。
2.7.2 核心类与关键字
- ObjectOutputStream:IO 类,包含序列化对象的方法,writeObject()
- ObjectInputStream:IO 类,包含反序列化对象的方法,readObject()
- 上面两个 IO 流类是高层次的数据库,需要借助文件流进行序列化与反序列化操作。
- Serializable ,接口,是一个标志性接口,标识可以在 JVM 中进行序列化,JVM 会为该类自动生成一个序列化版本号。参与序列化与反序列化的类必须实现 Serializable 接口。
- serialVersionUID,类属性,序列化版本号,用于给 JVM 区别同名类,没有提供版本号,JVM会默认提供序列化版本号。
- transient,关键字,当序列化时,不希望某些属性参与,则可以使用这个关键字标注该属性。
2.7.3 序列化与反序列化的过程
- 内存中的数据信息被拆分成一小块一小块的部分,为每个小块设置编号,然后存放到硬盘文件中,也就是将 Java 对象的状态保存下来存储到文件中的过程就叫做序列化。
- 将硬盘中保存了 Java 对象状态的字节序列按照编号组装成对象恢复到内存中,这个过程称为反序列化。
2.7.4 应用示例
参与序列化和反序列化的 Java 类
public class Student implements Serializable {
private String name;
private int age;
// 以下省略有参构造、无参构造、set、get、toString
}
> 参与序列化和反序列化的类必须实现 Serializable 接口。
序列化操作
public static void main(String[] args) throws Exception {
// 创建 Java 对象
Student student = new Student("张三",22);
// 对象输出流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("student"));
// 使用 writeObject 序列化对象
oos.writeObject(student);
// 刷新
oos.flush();
// 关闭流
oos.close();
}
> 序列化后的二进制文件会被保存到文件输出流指定的路径。
反序列化操作
public static void main(String[] args) throws Exception {
// 对象输入流
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("student"));
// 使用 readObject() 反序列化
Object obj = ois.readObject();
// 使用对象
System.out.println(obj);
// 关闭流
ois.close();
}
> 反序列化需要借助文件输入流读取指定路径的二进制文件。
2.7.5 序列化版本号的作用 serialVersionUID
- JVM 首先会通过类名来区分 Java 类,类名不同,则不是同一个类。当类名相同时,JVM 就会通过序列化版本号来区分 Java 类,如果序列化版本号相同就为同一个类,序列化版本号不同就为不同的类。
- 在序列化一个对象时,如果没有指定序列化版本号,后期对该类的源码进行修改并重新编译后,会导致修改前后的序列化版本号不一致,因为 JVM 会提供一个新的序列化版本号给该类对象。
- 此 时 再 用 以 往 的 反 序 列 化 代 码 去 反 序 列 化 该 类 的 对 象 , 就 会 抛 出 异 常java.io.InvalidClassException ,所以序列化一个类时最好指定一个序列化版本号,或者永远不修改此类。
public class Student implements Serializable {
private static final Long serialVersionUID = 1L;
}
- 由 JVM 提供序列化版本号的好处是,同名却不同功能的类,会有两个不同的序列化版本号,JVM 可以通过序列化版本号加以区分,缺点是一旦修改源码,会重新提供序列化版本号,导致修改前后的序列化版本号不一致,进行反序列化时会出现运行出现异常。
- 由 开发人员 手动提供序列化版本号的好处是,当修改了被序列化类的源码后,以往写的反序列化代码依然可以使用,如 JDK 中的 String 类。以便后期进行增强和维护不会影响使用。
2.7.6 transient 关键字
- 这个关键字表示游离的,不参与序列化的。
- 在序列化一个对象时,如果不希望某个属性参加序列化,可以使用 `transient` 修饰该属性。
- 被该关键字修饰的属性不会参与到序列化中。
public class Student implements Serializable {
private static final Long serialVersionUID = 1L;
private String name;
private transient int age;
}
> 如上类,在序列化时就不会保存 age 属性,在反序列化时就不能会付出该属性,默认恢复成 null 或 0 ,由属性类型决定。
2.7.7 序列化的好处及应用场景
- 序列化会将内存中对象的状态转换成二进制文件保存到磁盘当中,当再次使用时会从磁盘中读取该二进制文件,将 Java 对象的状态恢复到内存中。
- 当你想把内存中的对象保存到磁盘文件或数据库中时可以使用序列化。
- 当你想在网络传输中传送 Java 对象时,可以使用序列化。
- 当你想通过 RMI 传输对象时,可以使用序列化。
2.7.8 序列化注意事项
- 序列化只会保存对象的属性状态,不会保存对象中的方法。
- 父类实现了 Serializable 接口,则其子类也自动实例化了该接口,也就是说子类不用显式实现 Serializable 接口也能参与序列化和反序列化。
- 一个对象 A 的实例变量引用了其他对象 B,在 A 对象实例化的过程中 ,也会序列化 B ,前提是 A、B 两个类都实现了 Serializable 接口。
- 当一个类实现 Serializable 接口时,最好手动指定一个序列化版本号(serialVersionUID),避免修改源代码后导致反序列化出现异常。
- 当一个类对象会被多次重复使用,且一般不会对其属性做修改,就可以对其进行序列化。
例如数据库操作中的实体类。
2.8 Java IO 流原理
1. I/O 是 Input 和 Output 的缩写,I/O 技术是非常实用的技术,用于处理数据传输。如:读写文件,网络通讯等。
2. Java 程序中,对于数据的输入/输出操作以流(Stream)的方式进行。
3. java.io 包下提供了各种”流“类和接口,用以获取不同种类的数据,并通过方法输入或输出数据。
4. 输入 Input:读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中。
5. 输出 Output:将程序(内存)数据输出到磁盘、光盘等存储设备中。
三、网络通信协议
3.1 网络通信协议
网络通信协议是一种网络通用语言,为连接不同操作系统和不同硬件体系结构的互联网络引提供通信支持,是一种网络通用语言。
常见的网络通信协议有:TCP/IP 协议、IPX/SPX 协议、NetBEUI 协议等。
3.2 OSI 开放系统互联(Open System Interconnection)
开放式系统互联是把网络通信的工作分为 7 层,分别是物理层,数据链路层,网络层,传输层,会话层,表示层和应用层。
- 第 1 层 是物理层(也即 OSI 模型中的第一层)
物理层实际上就是布线、光纤、网卡和其它用来把两台网络通信设备连接在一起的东西。主要功能是确保二进制数字信号 0 和 1 在物理媒体上的正确传输,物理媒介也叫传输媒介。
物理层协议由机械特性、电气特性、功能特性和规程特性 4 个部分组成。物理层的常用标准是 EIA-232-D,俗称“232 接口”。
物理层数据处理的基本单位是比特。
- 第 2 层 是数据链路层(Data Link Layer)
主要负责在相邻节点间的链路上无差错地传送信息帧。数据链路层的协议主要有面向比特的链路层协议。
- 第 3 层 是网络层(Network Layer)
在计算机网络中进行通信的两个计算机之间可能会经过很多个数据链路,也可能还要经过很多通信子网。
主要负责网络中两台主机之间的数据交换。网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。网络层将数据链路层提供的帧组成数据包,包中封装有网络层包头,其中含有逻辑地址信息- -源站点和目的站点地址的网络地址。地址解析和路由是 3 层的重要目的。
- 第 4 层 是传输层(Transport Layer)。
第 4 层的数据单元也称作数据包(packets)。TCP 的数据单元称为段(segments)而 UDP 协议的数据单元称为“数据报(datagrams)”。这个层负责获取全部信息,因此,它必须跟踪数据单元碎片、乱序到达的数据包和其它在传输过程中可能发生的危险。
第 4 层也提供端对端的通信管理**。像 TCP 等一些协议非常善于保证通信的可靠性。有些协议并不在乎一些数据包是否丢失,UDP 协议就是一个主要例子。
- 第 5 层 是会话层( Session Layer)
这一层也可以称为会晤层或对话层,在会话层及以上的高层次中,数据传送的单位不再另外命名,统称为报文。会话层不参与具体的传输,它提供包括访问验证和会话管理在内的建立和维护应用之间通信的机制。如服务器验证用户登录便是由会话层完成的。
- 第 6 层 是表示层(Presentation Layer)
这一层主要解决用户信息的语法表示问题。它将欲交换的数据从适合于某一用户的抽象语法,转换为适合于 OSI 系统内部使用的传送语法。即提供格式化的表示和转换数据服务。数据的压缩和解压缩, 加密和解密等工作都由表示层负责。
- 第 7 层 是应用层(Application Layer)
是专门用于应用程序的。应用层确定进程之间通信的性质以满足用户需要以及提供网络与用户应用软件之间的接口服务。如果你的程序需要一种具体格式的数据,你可以发明一些你希望能够把数据发送到目的地的格式,并且创建一个第 7 层协议。SMTP、DNS(域名系统)和 FTP 文本传输协议都是 7 层协议。
3.3 TCP/IP 协议
但由于 OSI 定义的太过复杂而错过了时间节点,让 TCP/IP 协议成为了计算机网络通信的事实标准。
在今天的基于 TCP/IP 的互联网诞生之前,能够使用接口通信处理实现互联互通的电脑并不多,而且大部分电脑之间信息的交换并不兼容。后来在 1974 年 12 月,Bob Kahn 和 Vinton G.Cerf 带领的团队首先制定出了通过详细定义的 TCP/IP 协议标准。当时作了一个试验,将信息包通过点对点的卫星网络,再通过陆地电缆,再通过卫星网络,再由地面传输,贯串欧洲和美国,经过各种电脑系统,全程 9.4 万公里竟然没有丢失一个数据位,远距离的可靠数据传输证明了 TCP/IP 协议的成功。1983 年 1 月 1 日,运行较长时期曾被人们习惯了的 NCP 被停止使用,TCP/IP 协议作为因特网上所有主机间的共同协议,从此以后被作为一种必须遵守的规则被肯定和应用。
“TCP/IP”是很多协议很多协议组成的一个协议集合。我们把这集合统称为 TCP/IP 协议族,简称为 TCP/IP 协议。
对于 TCP/IP 协议族按层次分别分为以下 4 层:应用层、传输层、网络层和数据链路层。通过下图我们可以了解 TCP/IP 协议结构并对比了解学习 TCP/IP 四层参考模型和 OSI 七层参考模型,因为 TCP/IP 太过简单,我们也会使用模型化的 TCP/IP 五层模型来描述计算机网络。
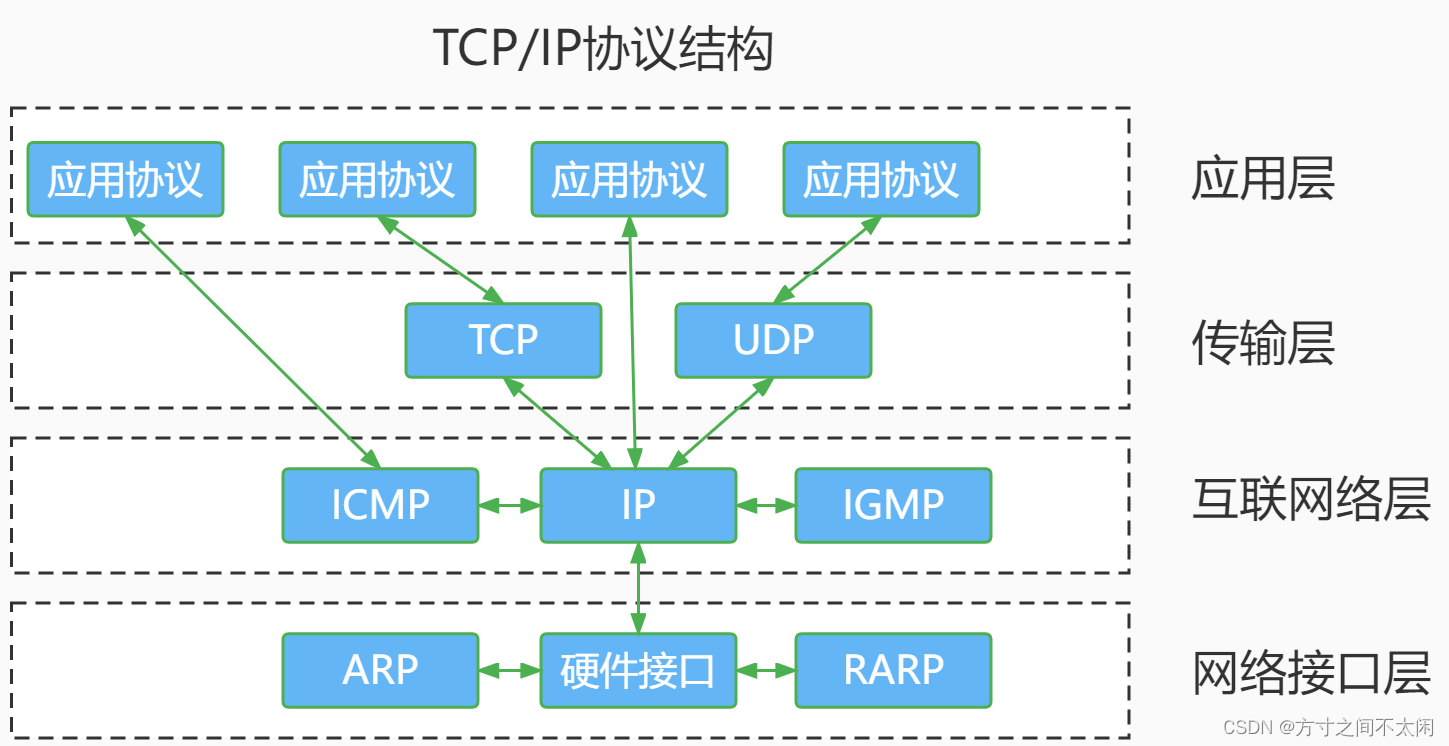
应用层
如何通过应用进程间的交互来完成特定的网络应用。应用层协议定义的是应用进程间的通信和交互规则。不同的网络有不同的协议:
| 端口号 | 名称 | 说明 |
| ------- | -------- | --------------------------------------------- |
| 20 | ftp-data | FTP 数据端口 |
| 21 | ftp | 文件传输协议(FTP)控制端口 |
| 22 | ssh | 安全 shell(SSH)远程登陆 |
| 23 | telnet | telnet 远程登陆服务 |
| 25 | smtp | 简单邮件传输协议 SMTP |
| 53 | dns | 域名服务 |
| 69 | tftp | 简单文件传输协议 |
| 80 | http | 用于万维网(WWW)服务的超文本传输协议(HTTP) |
| 123 | ntp | 网络时间协议 |
| 161/162 | snmp | 简单网络管理协议 |
| 443 | https | 安全超文本传输协议 |
| 1433 | mysql | mysql 数据库服务程序默认端口 |
| 8080 | tomcat | Java 服务器程序默认端口 |
端口号是固定好的,端口号的范围是 0~65535,其中 1-1024 是被规定好的端口,监听该范围端口的程序必须以 root 权限运行。从 1025-65535 端口被称为动态端口,可用来建立与其他主机的会话,也可以由用户自定义用途,所以在写服务器程序时,一般使用该范围内的端口应尽量避免一些知名的端口或当前系统正在使用的端口,具体怎么直到当前主机上运行了那些服务器程序并监听了哪些端口可以用 sudo netstat -tlnp 命令查看。
传输层
像两台主机中进程之间的通信提供通用的数据传输服务,起始各层的协议都是直接或间接的服务于主机与主机之间的通信,传输层就是进程与进程之间互相通信的协议,目前被人们所熟知的两个重要协议:
TCP(传输控制)协议
提供面向连接的可靠的数据传输,传输单位为报文段(segment)。
- TCP 是点对点的连接,一条 TCP 连接只能连接两个端点;
- TCP 需要进行“三次握手”建立连接,通信结束后要使用“四次挥手”断开连接;
- TCP 提供可靠传输,无差错,不丢失,不重复,按顺序传输,但是其开销较大,传输速度较慢;
- TCP 提供全双工通信,允许通信双方任何时候都能发送数据,发送方设有发送缓存,接收方设有接收缓存。
UDP(用户数据报)协议
提供面向无连接的、不可靠不稳定的数据传输。
- UDP 是无连接的,发送数据之前不需要建立连接,减少了开销和延时;
- UDP 是面向报文的,对 IP 数据报只做简单封装,(8字节 UDP 报头)减少包头开销;
- UDP 没有阻塞机制,宁愿阻塞时丢弃数据不传也不阻塞造成延时;
- UDP 支持一对一、一对多、多对一、多对多通信。
网络层
网络层最需要的协议就是 IP 协议,在 TCP/IP 协议族中,所有的协议数据都依附于 IP 数据包格式传输,IP 协议提供不可靠、无连接的数据传输服务,就是说 IP 协议不能保证数据能否成功到达目的地,只提供传输服务,传输出错的可能性较大,无连接是指 IP 协议对数据包的处理是独立的。这意味着接收方不一定会按照发送顺序接收数据包。
IP 地址版本
常见的 IP 地址目前有 IPv4和 IPv6两个版本,当前广泛应用的是 IPv4,但是 IPv4已经几乎被消耗殆尽,下一阶段可能会进行版本升级至 IPv6,一般情况下我们所使用的是 IP v4。
IP 地址对应于 TCP/IP 协议的网络层,是 TCP、IP 协议中很重要的一层协议。
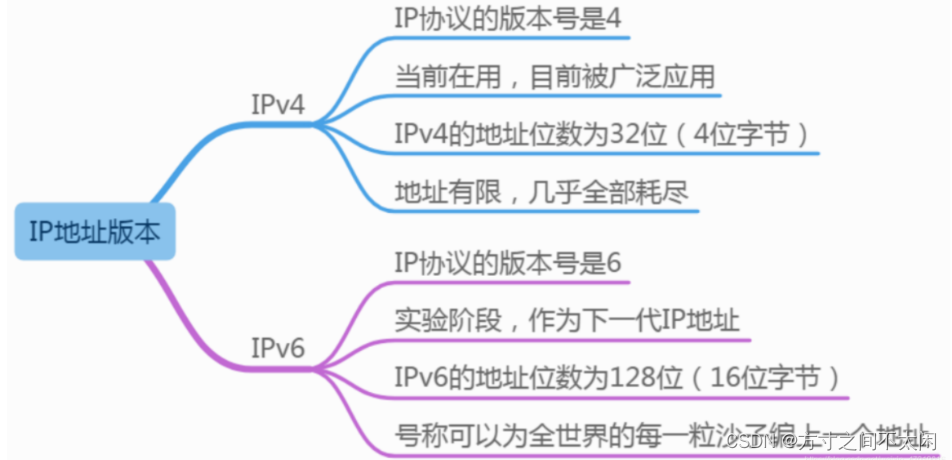
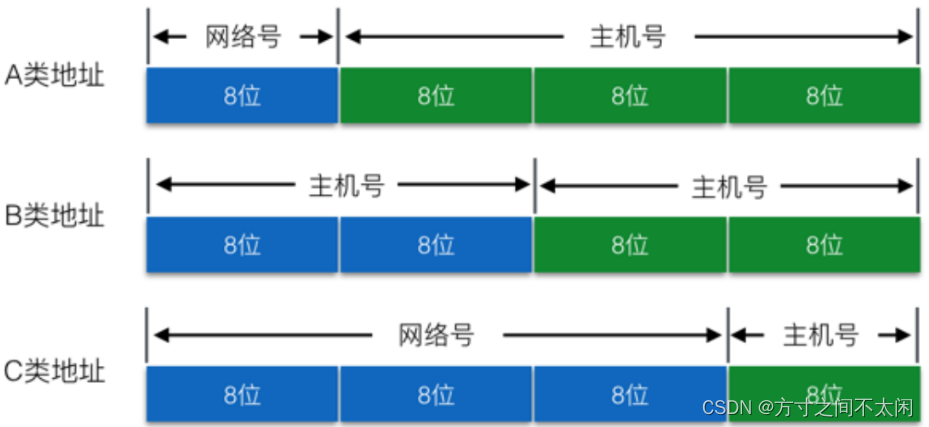
IP 地址分类
A 类地址网络号占1个字节主机号占3个字节
B 类地址网络号占2个字节主机号占2个字节
C 类地址网络号占3个字节主机号占1个字节
D 类地址是组播地址
E 类地址是实验地址(保留)
| 地址分类 | 网络号范围 | IP 地址范围 | 私有地址范围 | 保留地址 | 可容纳主机号容量 |
| -------- | ---------------------- | ------------------------ | -------- -- |--------- | ------------- |
| A 类 地 址 | 1.0.0.0-127.0.0.0 | 1.0.0.0-127.255.255.255 |192.0.0.0-223.255.255.255 | 127.X.X.X 是保留地址,用作循环测试 |2^24-2=16777214 |
| B 类地址 | 128.0.0.0-191.255.0.0 | 128.0.0.0-191.255.255.255 | 172.31.255.255 | 169.254.X.X 是保留地址,191.255.255.255 是广播地址 | 2^16-2=65534 |
| C 类地址 | 192.0.0.0-223.255.255.0 | 192.0.0.0-223.255.255.255 | 192.168.255.255| | 2^8-2=25 |
数据链路层
计算机网络是由主机、路由器和连接他们的链路组成,从源主机发送到目的主机的分组必须在一段一段的链路上传送,数据链路层的任务就是将分组从链路的一段传送到另一端,我们将数据链路层传送的数据单元称为“帧”,帧里面不仅有数据,还包含一些控制信息:控制信息使得接收端能够知道一个帧从哪个比特开始到那个比特结束,也可以用于接收端检测所受到的帧中有没有错误信息。
数据链路层的任务就是在相邻结点之间的链路上传送以帧为单位的数据。
物理层
物理层是计算机体系结构中的最底层。完成计算机中最基础的任务,就是在传输媒体上传送比特流,把数据链路层中帧的每个比特从一个结点通过传输媒体传送到下一个结点,物理层传送单位是比特。
四、NIO
4.1 阻塞和非阻塞
同步:同步是指一个进程在执行某个请求的时候,如果该请求需要一段时间才能返回信息,那么这个进程会一直等待下去,直到收到返回信息才继续执行下去。
异步:异步是指进程不需要一直等待下去,而是继续执行下面的操作,不管其他进程的状态,当有信息返回的时候会通知进程进行处理,这样就可以提高执行的效率了,即异步是我们发出的一个请求,该请求会在后台自动发出并获取数据,然后对数据进行处理,在此过程中,我们可以继续做其他操作,不管它怎么发出请求,不关心它怎么处理数据。
阻塞:为了完成一个功能,发起一个调用,如果不具备条件的话则一直等待,直到具备条件则完成。
非阻塞:为了完成一个功能,发起一个调用,具备条件直接输出,不具备条件直接报错返回。区别:其实就相当于在捕捉一个子进程退出的时候,阻塞则会一直等待,直到这个子进程退出,返回对应的值,而非阻塞,如果刚好捕捉到子进程的退出则直接输出,如果没有捕捉到,也不进行等待,直接输出报错!
4.2 NIO
Java NIO(New IO)是从 Java 1.4 版本开始引入的一个新的 IO API,可以替代标准的 Java IO API。NIO 与原来的 IO 有同样的作用和目的,但是使用方式完全不同,NIO 支持面向缓冲区的、基于通道的 IO 操作。NIO 将以更加高效的方式进行文件的读写操作。
NIO 与 IO 的区别
| IO | NIO |
| :-----------------------: | :---------------------------: |
| 面向流(Stream Oriented) | 面向缓冲区(Buffer Oriented) |
| 阻塞 IO(Blocking IO) | 非阻塞 IO(Non Blocking IO) |
| | 选择器(Selectors) |
通道和缓冲区
Java NIO 系统的核心在于:通道(Channel)和缓冲区(Buffer)。通道表示打开到 IO 设备(例如:文件、套接字)的连接。若需要使用 NIO 系统,需要获取用于连接 IO 设备的通道以及用于容纳数据的缓冲区。然后操作缓冲区,对数据进行处理。简而言之,Channel负责传输,Buffer 负责存储。
传统 IO 流
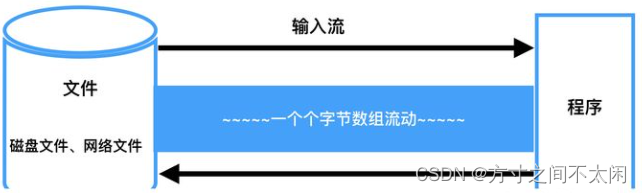
对上图说明一下:
①我们需要把磁盘文件或者网络文件中的数据读取到程序中来,我们需要建立一个用于传输数据的管道,原来我们传输数据面对的直接就是管道里面一个个字节数据的流动(我们弄了一个 byte 数组,来回进行数据传递),所以说原来的 IO 它面对的就是管道里面的一个数据流动,所以我们说原来的 IO 是面向流的。
②我们说传统的 IO 还有一个特点就是,它是单向的。解释一下就是:如果说我们想把目标地点的数据读取到程序中来,我们需要建立一个管道,这个管道我们称为输入流。相应的,如果如果我们程序中有数据想要写到目标地点去,我们也得再建立一个管道,这个管道我们称为输出流。所以我们说传统的 IO 流是单向的。
NIO
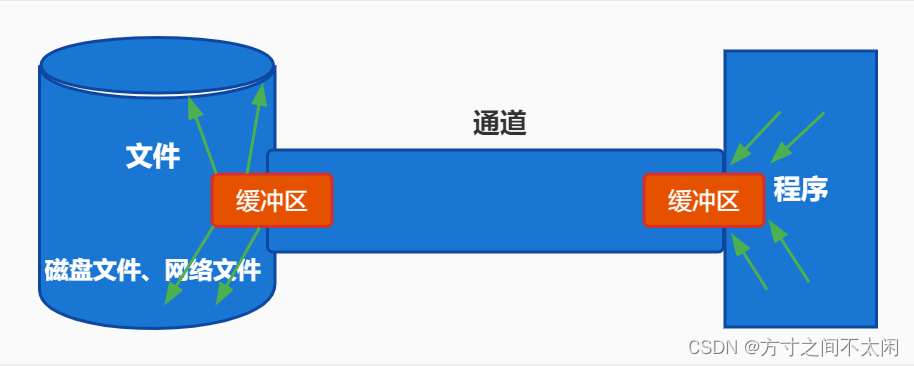
解释一下上图:
①我们说只要是 IO ,那么就是为了完成数据传输的。
②即便你用 NIO ,它也是为了数据传输,所以你要想完成数据传输,你也得建立一个用于传输数据的通道,这个通道你不能把它理解为之前的水流了,但是你可以把它理解为铁路,铁路本身是不能完成运输的,铁路要想完成运输它必须依赖火车,说白了这个通道就是为了连接目标地点和源地点。所以注意通道本身不能传输数据,要想传输数据必须要有缓冲区,这个缓冲区你就可以完全把它理解为火车,比如说你现在想把程序中的数据写到文件中,那么你就可以把数据都写到缓冲区,然后缓冲区通过通道进行传输,最后再把数据从缓冲区拿出来写到文件中,你想把文件中的数据传数到程序中,也是一个道理,把数据写到缓冲区,缓冲区通过通道进行传输,到程序中把数据拿出来。所以我们说原来的 IO 单向的现在的缓冲区是双向的,这种传输数据的方式也叫面向缓冲区。总结一下,就是通道只负责连接,缓冲区才负责存储数据。
缓冲区的数据存取
缓冲区(Buffer):一个用于特定基本数据类型的容器。由 java.nio 包定义的,所有缓冲区都是 Buffer 抽象类的子类。
缓冲区的类型
缓冲区(Buffer):在 Java NIO 中负责数据的存取。缓冲区就是数组。用于存储不同类型的数据。根据数据类型的不同(boolean 除外),提供了相应类型的缓冲区:
> ByteBuffer
> CharBuffer
> ShortBuffer
> IntBuffer
> LongBuffer
> FloatBuffer
> DoubleBuffer
上述缓冲区管理方式几乎一致,都是通过 allocate() 来获取缓冲区。
缓冲区存取数据的两个核心方法
- put():存入数据到缓冲区中。
- get():获取缓冲区中的数据。
缓冲区中的四个核心属性
- capacity: 容量,表示缓冲区中最大存储数据的容量。一旦声明不能更改。
- limit: 界限,表示缓冲区中可以操作数据的大小。(limit 后的数据不能进行读写)
- position: 位置,表示缓冲区中正在操作数据的位置。
- mark: 标记,表示记录当前 position 的位置。可以通过 reset() 恢复到 mark 的位置。
- 案例
public class TestBuffer {
public static void test1() {
String str = "abcde";
//分配一个指定大小的缓冲区
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
System.out.println("---------allocate-----------");
System.out.println(byteBuffer.capacity()); //1024
System.out.println(byteBuffer.limit()); //1024
System.out.println(byteBuffer.position()); //0
//利用 put() 存入数据到缓冲区中
byteBuffer.put(str.getBytes());
System.out.println("---------put-----------");
System.out.println(byteBuffer.capacity()); //1024
System.out.println(byteBuffer.limit()); //1024
System.out.println(byteBuffer.position()); //5
//切换到读数据模式
byteBuffer.flip();
System.out.println("---------flip-----------");
System.out.println(byteBuffer.capacity()); //1024
System.out.println(byteBuffer.limit()); //5,limit 表示可以操作数据的大小,只有 5 个字节的数据给你读,所以可操作数据大小是 5
System.out.println(byteBuffer.position()); //0,读数据要从第 0 个位置开始读
//利用 get() 读取缓冲区中的数据
byte[] dst = new byte[byteBuffer.limit()];
byteBuffer.get(dst);
System.out.println(new String(dst,0,dst.length));
System.out.println("---------get-----------");
System.out.println(byteBuffer.capacity()); //1024
System.out.println(byteBuffer.limit()); //5,可以读取数据的大小依然是 5 个
System.out.println(byteBuffer.position()); //5,读完之后位置变到了第 5 个
//rewind() 可重复读
byteBuffer.rewind(); //这个方法调用完后,又变成了读模式
System.out.println("---------rewind-----------");
System.out.println(byteBuffer.capacity()); //1024
System.out.println(byteBuffer.limit()); //5
System.out.println(byteBuffer.position()); //0
//clear() 清空缓冲区,虽然缓冲区被清空了,但是缓冲区中的数据依然存在,只是出于"被遗忘"状态。意思其实是,缓冲区中的界限、位置等信息都被置为最初的状态了,所以你无法再根据这些信息找到原来的数据了,原来数据就出于"被遗忘"状态
byteBuffer.clear();
System.out.println("---------clear-----------");
System.out.println(byteBuffer.capacity()); //1024
System.out.println(byteBuffer.limit()); //1024
System.out.println(byteBuffer.position()); //0
}
public static void test2() {
String str = "abcde";
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
byteBuffer.put(str.getBytes());
byteBuffer.flip();
byte[] bytearray = new byte[byteBuffer.limit()];
byteBuffer.get(bytearray,0,2);
System.out.println(new String(bytearray,0,2)); //结果是 ab
System.out.println(byteBuffer.position()); //结果是 2
//标记一下当前 position 的位置
byteBuffer.mark();
byteBuffer.get(bytearray,2,2);
System.out.println(new String(bytearray,2,2));
System.out.println(byteBuffer.position()); //结果是 4
//reset() 恢复到 mark 的位置
byteBuffer.reset();
System.out.println(byteBuffer.position()); //结果是 2
//判断缓冲区中是否还有剩余数据
if (byteBuffer.hasRemaining()) {
//获取缓冲区中可以操作的数量
System.out.println(byteBuffer.remaining()); //结果是 3,上面 position 是从 2 开始的
}
}
public static void main(String[] args) {
// test1();
test2();
}
}
直接缓冲区与非直接缓冲区
非直接缓冲区
通过 allocate() 方法分配缓冲区,将缓冲区建立在 JVM 的内存之中。
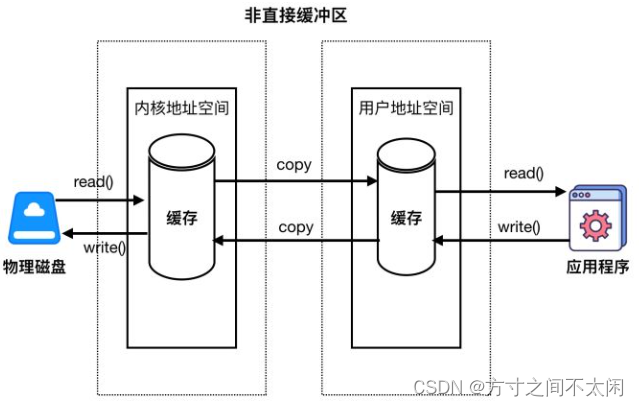
对上图的解释:
应用程序和磁盘之间想要传输数据,是没有办法直接进行传输的。操作系统出于安全的考虑,会经过上图几个步骤。例如,我应用程序想从磁盘中读取一个数据,这时候我应用程序向操作系统发起一个读请求,那么首先磁盘中的数据会被读取到内核地址空间中,然后会把内核地址空间中的数据拷贝到用户地址空间中(其实就是 JVM 内存中),最后再把这个数据读取到应用程序中来。
同样,如果我应用程序有数据想要写到磁盘中去,那么它会首先把这个数据写入到用户地址空间中去,然后把数据拷贝到内核地址空间,最后再把这个数据写入到磁盘中去。
直接缓冲区
通过 allocateDirect() 方法分配缓冲区,将缓冲区建立在物理内存之中。
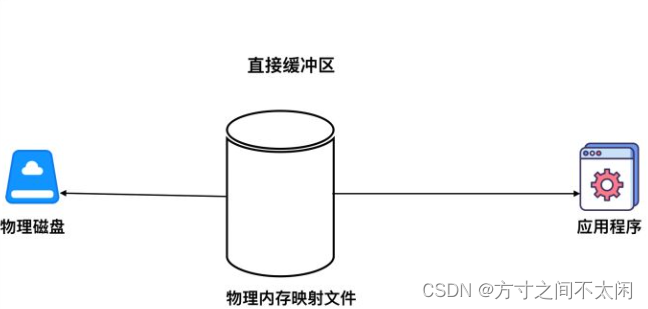
对上图解释:
> 直接用物理内存作为缓冲区,读写数据直接通过物理内存进行。
代码案例:
public static void test3() {
// 分配直接缓冲区
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024);
// 判断是直接缓冲区还是非直接缓冲区
System.out.println(byteBuffer.isDirect());
}
注:字节缓冲区是直接缓冲区还是非直接缓冲区可通过调用其 isDirect() 方法来确定。
通道
通道(channel):由 java.nio.channels 包定义的。Channel 表示 IO 源与目标打开的连接。Channel 类似于传统的流,只不过 Channel 本身不能直接访问数据,Channel 只能与 Buffer 进行交互。
通道用于源节点与目标节点的连接。在 Java NIO 中负责缓冲区中数据的传输。Channel 本身不存储数据,因此需要配合缓冲区进行传输。
主要实现类
java.nio.channels.Channel 包下:
- FileChannel
- SocketChannel
- ServerSocketChannel
- DatagramChannel
获取通道
Java 针对支持通道的类提供了 getChannel() 方法。
本地 IO:
FileInputStream/FileOutputStream
RandomAccessFile
网络 IO:
Socket
ServerSocket
DatagramSocket
以上几个类都可以通过调用 getChannel() 方法获取通道
- 在 JDK1.7 中的 NIO.2 针对各个通道提供了静态方法 open()。
- 在 JDK1.7 中的 NIO.2 的 Files 工具类的 newByteChannel() 方法。
通道数据传输和内存映射文件。
使用通道完成文件的复制(非直接缓冲区)。
public static void test1() throws Exception {
// 利用通道完成文件的复制(非直接缓冲区)
FileInputStream fis = new FileInputStream("a.txt");
FileOutputStream fos = new FileOutputStream("b.txt");
// 获取通道
FileChannel fisChannel = fis.getChannel();
FileChannel foschannel = fos.getChannel();
// 通道没有办法传输数据,必须依赖缓冲区
// 分配指定大小的缓冲区
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
// 将通道中的数据存入缓冲区中
while (fisChannel.read(byteBuffer) != -1) { // fisChannel 中的数据读到 byteBuffer 缓冲区中
byteBuffer.flip(); // 切换成读数据模式
// 将缓冲区中的数据写入通道
foschannel.write(byteBuffer);
byteBuffer.clear(); // 清空缓冲区
}
foschannel.close();
fisChannel.close();
fos.close();
fis.close();
}
使用直接缓冲区完成文件的复制(内存映射文件)。
方式一:
public static void test2() throws Exception {
// 使用直接缓冲区完成文件的复制(内存映射文件)
/**
* 使用 open 方法来获取通道
* 需要两个参数
* 参数1:Path 是 JDK1.7 以后给我们提供的一个类,代表文件路径
* 参数2:Option 就是针对这个文件想要做什么样的操作
* --StandardOpenOption.READ :读模式
* --StandardOpenOption.WRITE :写模式
* --StandardOpenOption.CREATE :如果文件不存在就创建,存在就覆盖
*/
FileChannel inChannel = FileChannel.open(Paths.get("a.txt"), StandardOpenOption.READ);
FileChannel outChannel = FileChannel.open(Paths.get("c.txt"), StandardOpenOption.WRITE,
StandardOpenOption.READ, StandardOpenOption.CREATE);
/**
* 内存映射文件
* 这种方式缓冲区是直接建立在物理内存之上的
* 所以我们就不需要通道了
*/
MappedByteBuffer inMapped = inChannel.map(FileChannel.MapMode.READ_ONLY, 0, inChannel.size());
MappedByteBuffer outMapped = outChannel.map(FileChannel.MapMode.READ_WRITE, 0, inChannel.size());
// 直接对缓冲区进行数据的读写操作
byte[] dst = new byte[inMapped.limit()];
inMapped.get(dst); // 把数据读取到 dst 这个字节数组中去
outMapped.put(dst); // 把字节数组中的数据写出去
inChannel.close();
outChannel.close();
}
方式二:
public static void test3() throws Exception {
/**
* 通道之间的数据传输(直接缓冲区的方式)
* transferFrom
* transferTo
*/
FileChannel inChannel = FileChannel.open(Paths.get("a.txt"), StandardOpenOption.READ);
FileChannel outChannel = FileChannel.open(Paths.get("d.txt"), StandardOpenOption.READ, StandardOpenOption.WRITE,
StandardOpenOption.CREATE);
inChannel.transferTo(0, inChannel.size(), outChannel);
// 或者可以使用下面这种方式
//outChannel.transferFrom(inChannel, 0, inChannel.size());
inChannel.close();
outChannel.close();
}
分散读取与聚集写入
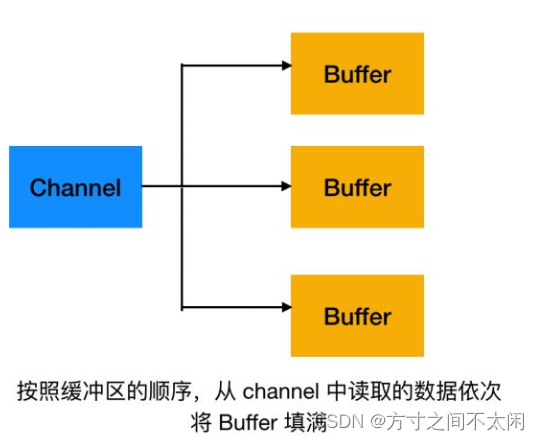
分散(Scatter)和聚集(Gather)
分散读取(Scattering Reads)是指从 Channel 中读取的数据 "分散" 到多个 Buffer 中。
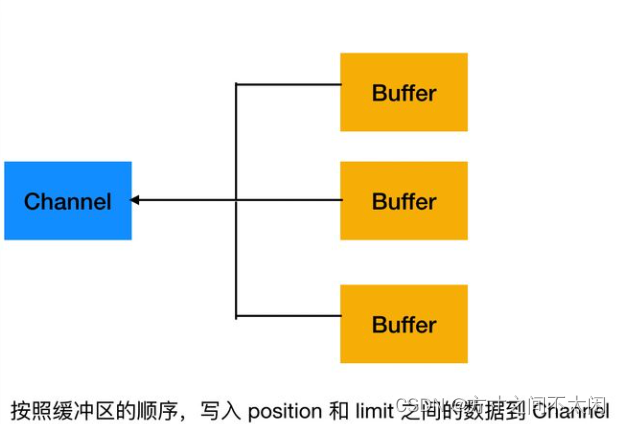
聚集写入(Gathering Writes)是指将多个 Buffer 中的数据 "聚集" 到 Channel。
代码案例:
public static void test4() throws Exception {
RandomAccessFile raf = new RandomAccessFile("a.txt", "rw");
// 获取通道
FileChannel channel = raf.getChannel();
// 分配指定大小缓冲区
ByteBuffer buf1 = ByteBuffer.allocate(2);
ByteBuffer buf2 = ByteBuffer.allocate(1024);
// 分散读取
ByteBuffer[] bufs = {buf1, buf2};
channel.read(bufs); // 参数需要一个数组
for (ByteBuffer byteBuffer : bufs) {
byteBuffer.flip(); // 切换到读模式
}
System.out.println(new String(bufs[0].array(), 0, bufs[0].limit())); // 打印 he
System.out.println(new String(bufs[1].array(), 0, bufs[1].limit())); // 打印 llo
// 聚集写入
RandomAccessFile raf2 = new RandomAccessFile("e.txt","rw");
// 获取通道
FileChannel channel2 = raf2.getChannel();
channel2.write(bufs); // 把 bufs 里面的几个缓冲区聚集到 channel2 这个通道中,聚集到通道中,也就是到了 e.txt 文件中
channel2.close();
}五、面试题
1. Java 中有几种类型的流?
字符流和字节流。
字节流继承 inputStream 和 OutputStream
字符流继承自 InputSteamReader 和 OutputStreamWriter
2. 字节流和字符流哪个好?怎么选择?
大多数情况下使用字节流会更好,因为大多数时候 IO 操作都是直接操作磁盘文件,所以这些流在传输时都是以字节的方式进行的(图片等都是按字节存储的);
如果对于操作需要通过 IO 在内存中频繁处理字符串的情况使用字符流会好些,因为字符流具备缓冲区,提高了性能。
3. 什么是缓冲区?有什么作用?
缓冲区就是一段特殊的内存区域,很多情况下当程序需要频繁地操作一个资源(如文件或数据库)则性能会很低,所以为了提升性能就可以将一部分数据暂时读写到缓存区,以后直接从此区域中读写数据即可,这样就显著提升了性。
对于 Java 字符流的操作都是在缓冲区操作的,所以如果我们想在字符流操作中主动将缓冲区刷新到文件则可以使用 flush() 方法操作。
4. 字符流和字节流有什么区别?
字符流和字节流的使用非常相似,但是实际上字节流的操作不会经过缓冲区(内存)而是直接操作文本本身的,而字符流的操作会先经过缓冲区(内存)然后通过缓冲区再操作文件。
5. 什么是 Java 序列化,如何实现 Java 序列化?
序列化就是一种用来处理对象流的机制,将对象的内容进行流化。可以对流化后的对象进行读写操作,可以将流化后的对象传输于网络之间。序列化是为了解决在对象流读写操作时所引发的问题。
序列化的实现:将需要被序列化的类实现 Serialize 接口,没有需要实现的方法,此接口只是为了标注对象可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个 ObjectOutputStream(对象流)对象,再使用 ObjectOutputStream 对象的 write(Object obj)方法就可以将参数 obj 的对象写出。
6. PrintStream、BufferedWriter、PrintWriter 的比较?
PrintStream 类的输出功能非常强大,通常如果需要输出文本内容,都应该将输出流包装成PrintStream 后进行输出。它还提供其他两项功能。与其他输出流不同,PrintStream 永远不会抛出 IOException;而是,异常情况仅设置可通过 checkError 方法测试的内部标志。另外,为了自动刷新,可以创建一个 PrintStream。
BufferedWriter:将文本写入字符输出流,缓冲各个字符从而提供单个字符,数组和字符串的高效写入。通过 write()方法可以将获取到的字符输出,然后通过 newLine()进行换行操作。BufferedWriter 中的字符流必须通过调用 flush 方法才能将其刷出去。并且 BufferedWriter 只能对字符流进行操作。如果要对字节流操作,则使用 BufferedInputStream PrintWriter 的 println 方法自动添加换行,不会抛异常,若关心异常,需要调用 checkError 方法看是否有异常发生,PrintWriter 构造方法可指定参数,实现自动刷新缓存(autoflush)。
7. BufferedReader 属于哪种流,它主要是用来做什么的,它里面有那些经典的方法?
属于处理流中的缓冲流,可以将读取的内容存在内存里面,有`readLine()`方法,它用来读取一行。
8. 什么是节点流,什么是处理流,它们各有什么用处,处理流的创建有什么特征?
节点流:直接与数据源相连,用于输入或者输出;
处理流:在节点流的基础上对之进行加工,进行一些功能的扩展;
处理流的构造器必须要 传入节点流的子类。
9. 流一般需要不需要关闭,如果关闭的话在用什么方法,一般要在那个代码块里面关闭比较好,处理流是怎么关闭的,如果有多个流互相调用传入是怎么关闭的?
流一旦打开就必须关闭,使用 close 方法;
放入 finally 语句块中(finally 语句一定会执行);
调用的处理流就关闭处理流;
多个流互相调用只关闭最外层的流。
10. InputStream 里的 read()返回的是什么,read(byte[] data)是什么意思,返回的是什么值?
返回的是所读取的字节的 int 型(范围 0-255);
read(byte [ ] data)将读取的字节储存在这个数组。返回的就是传入数组参数个数。
11. OutputStream 里面的 write()是什么意思,write(byte b[], int off, int len)这个方法里面的三个参数分别是什么意思?
write 将指定字节传入数据源。
Byte b[ ]是 byte 数组。
b[off]是传入的第一个字符、b[off+len-1]是传入的最后的一个字符 、len 是实际长度。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











