







题目描述如图:

最先想到的本来应该是使用mysql自带的窗口函数,肯定是很优雅的,但是我是初学者,对这个还不熟悉。
所以,一开始先做个分步计算,首先是降序查分数表,然后就是查分数前有多少个元素,根据排名要求确定去不去重和分数之间的比较条件,
降序查分数表:
select a.Score as Score
from Scores a
order by a.Score desc
查排名,作为子查询放在select后面
(select count(distinct b.Score) from Scores b where b.Score >= a.Score) as 'Rank'
检测结果:超过25?
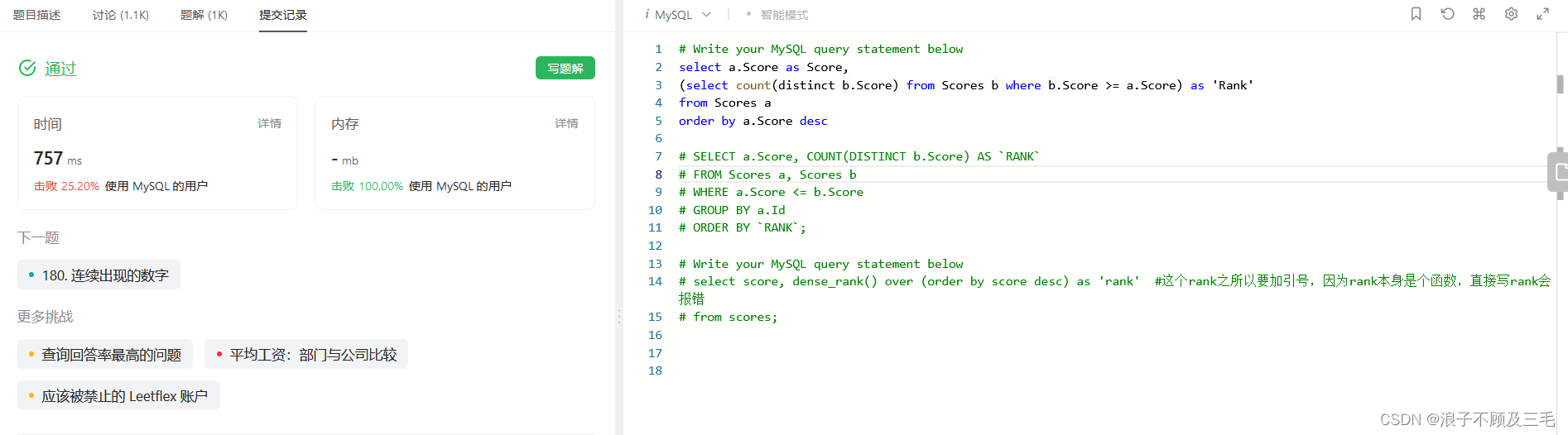
看看别人怎么写的 :
自连接:确实从代码上看优雅了不少。
SELECT a.Score, COUNT(DISTINCT b.Score) AS `RANK`
FROM Scores a, Scores b
WHERE a.Score <= b.Score
GROUP BY a.Id
ORDER BY `RANK`;
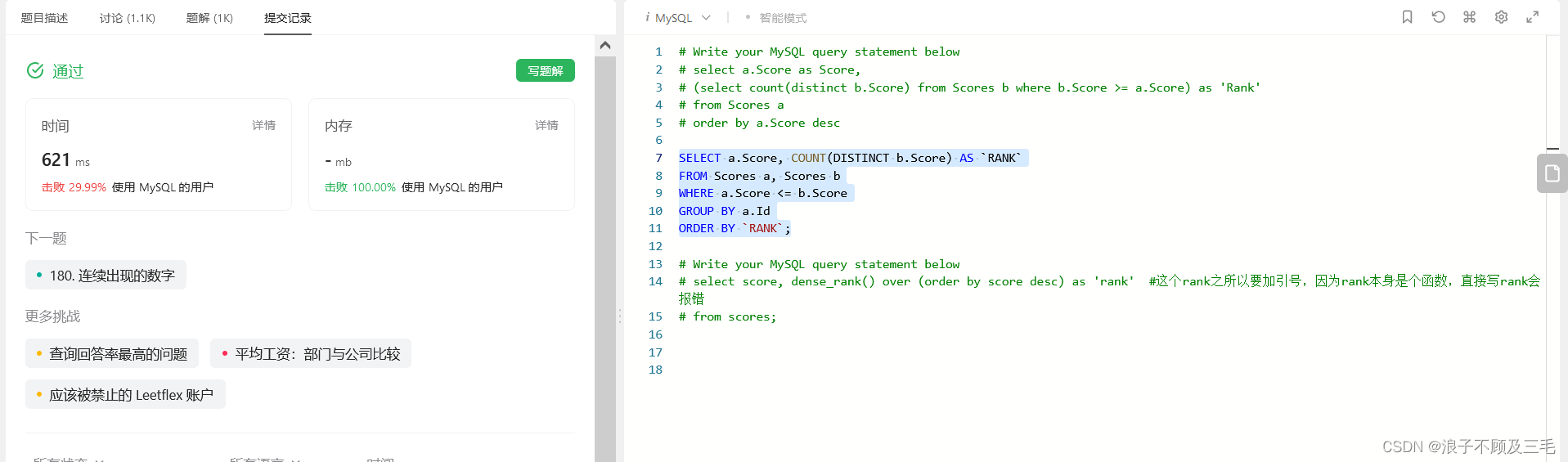
但是本质是一样的,所以只击败了29%。
最后,直接调用mysql大佬们封装好的rank排名系列的窗口函数之dense_rank(),效果牛的!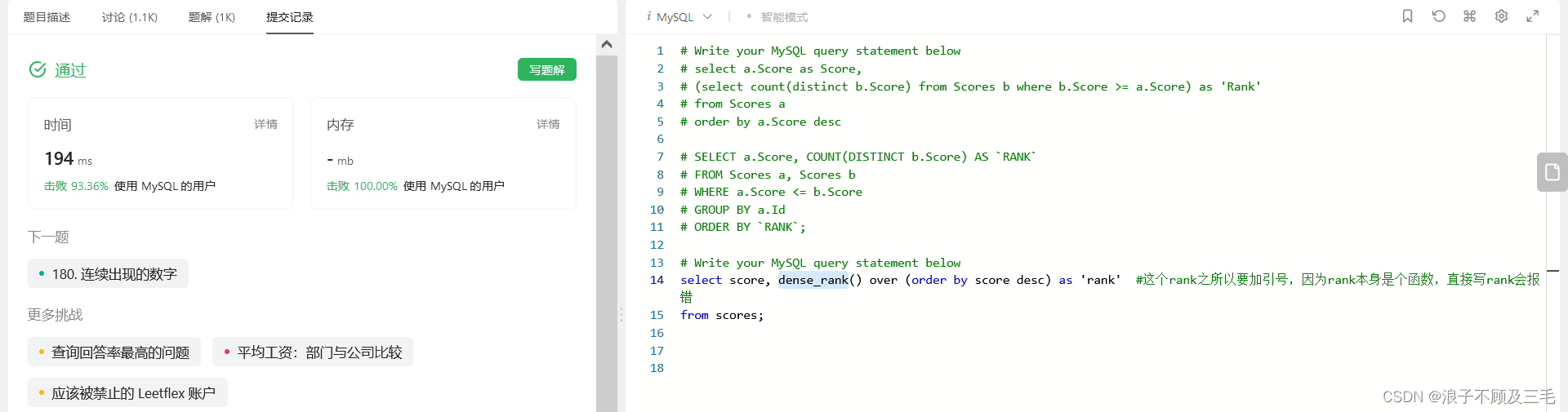
select score, dense_rank() over (order by score desc) as 'rank' #这个rank之所以要加引号,因为rank本身是个函数,直接写rank会报错
from scores;
所以,我学到了什么,首先要关注相关新技术,新技术很明显是一些最佳实践,一件事你只要觉得麻烦但是问题有比较具体,那你就要相信大佬们在优雅这方面的追求。就比如这个排名问题,挺典型的sql问题,肯定有相关优化,直接找,效果杠杠的!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











