



query到doc这种文本到文本的召回,通常就是各种双塔召回,再排序的过程.谷歌这篇论文<Transformer Memory as a Differentiable Search Index>却偏不.这篇论文提出了Differentiable Search Index(DSI)的方法,直接就把docid编码到了模型中,output直接就是docid,不需要像以往那样还要建立docid到向量的索引再ANN召回.这样在结果上显著优于双塔.
模型框架
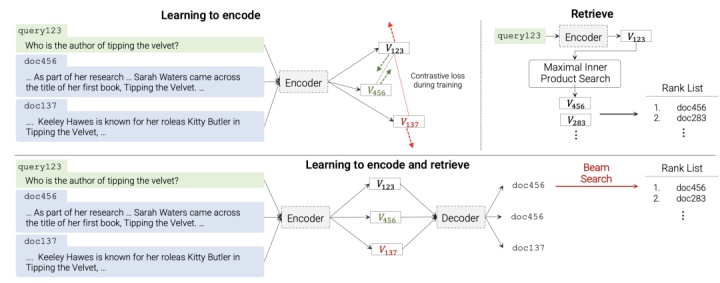
上图就是对比了传统双塔召回和本文的DSI召回,我们可以看到DSI是一个Encoder,Decoder的流程,通过Beam Search可以直接得到docid的list.
模型细节
索引策略:
- Inputs2Target: Seq2Seq任务,把doc的tokens翻译成docid. (论文最终采用).
- Target2Inputs: 上面方法反转下,用docid翻译成tokens.
- Bidirection: co-training 上述两种方式,使用一个前缀让模型知道是什么方向.
- span corruption: 直接把docid和tokens拼在一起,好处是方便做预训练.
Doc表达策略:
- Direct Index: 使用doc前L个tokens表示该doc (论文最终采用).
- Set Index: 先去重,去停用词,然后按照类似direct index的方式操作.
- Inverted Index: 多次采样连续的k个tokens表示该doc.
召回中docid的表达:
最简单的就是一个doc给定一个任意不重复的int值,这样我们就可以直接用softmax去学tokens和docid embedding直接的关系:
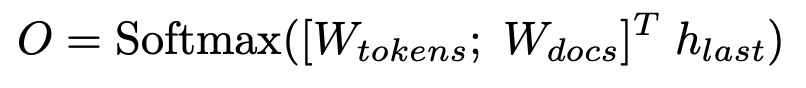
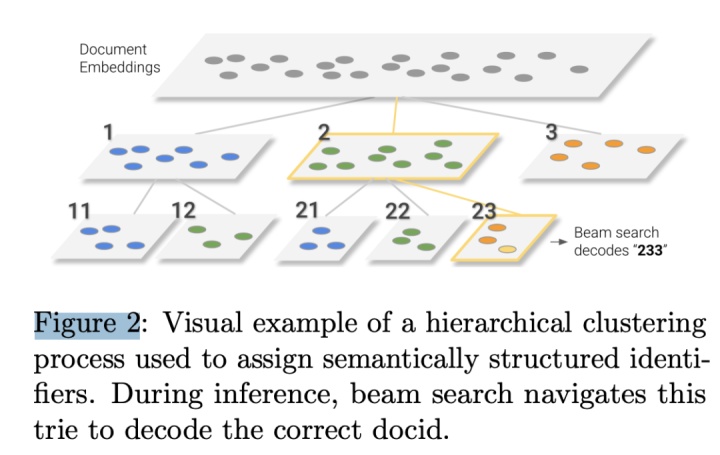
论文使用的是Semantically Structured Identifiers,这种方法认为docid不能任意给个int值然后lookup让模型学embedding,docid需要包含语义信息.除了这点,该方法还必须在decoding的时候检索性能要好.所以该方法是给定所有doc集合,先聚成10个类,每个doc第一位就是0~9,每个类都必须包含不超过c个的doc,不然就重复聚类操作.论文聚类算法用的kmeans,doc embedding用的是8层的小bert, c设置为100.

训练过程就是2步,第一步先让seq2seq学会记忆tokens到docid的映射,第二步就是fine-tuning到我们有label的query2doc任务上去.
实验
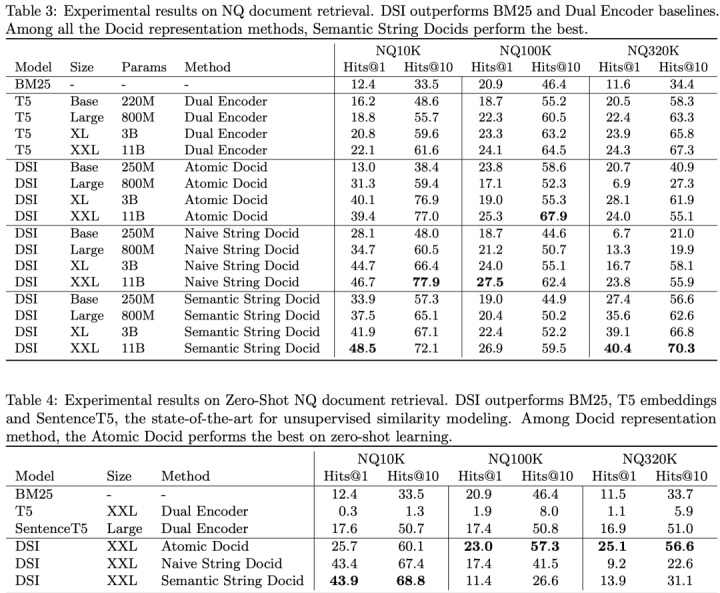

- Transformer Memory as a Differentiable Search Index https://arxiv.org/pdf/2202.06991.pdf


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









