







前言:大佬写博客给别人看,菜鸟写博客给自己看,我是菜鸟。
一、冯偌伊曼体系
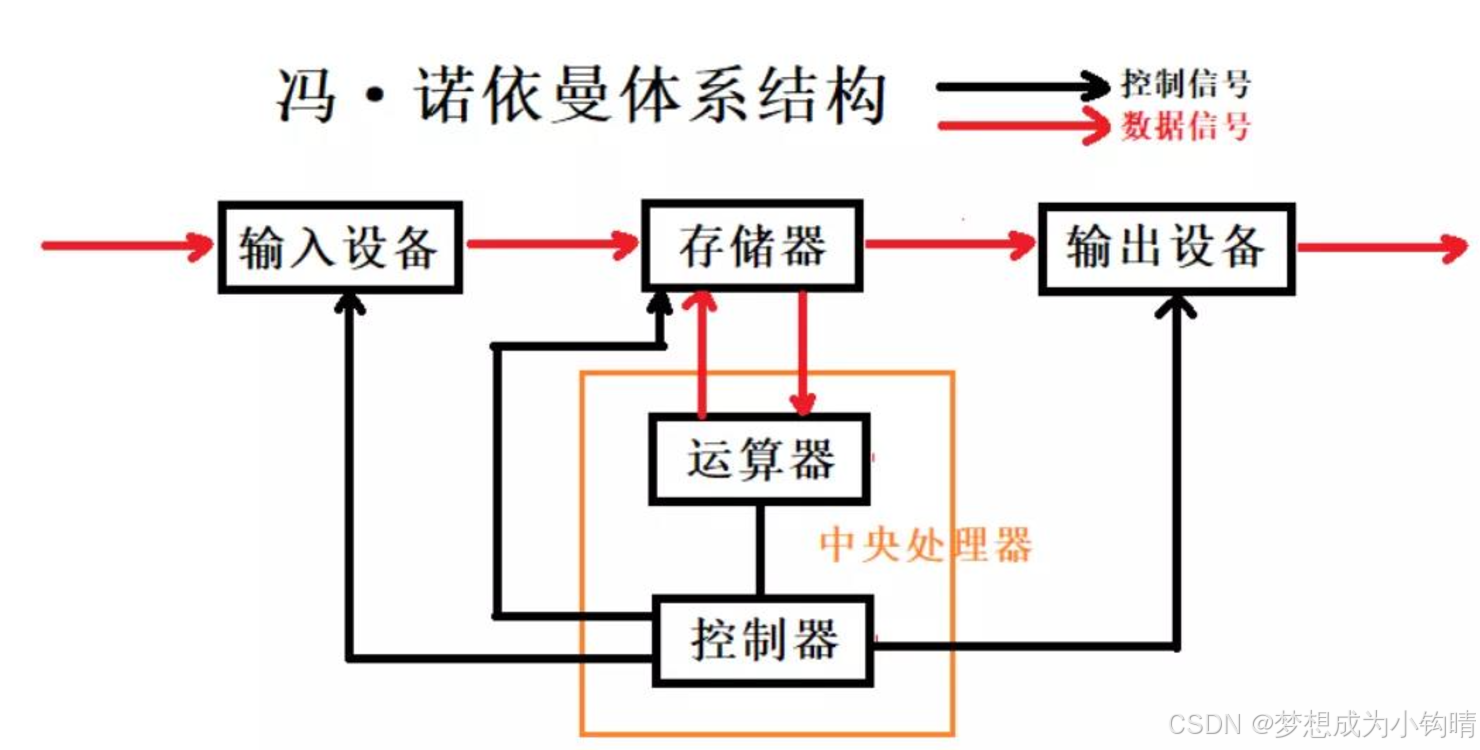
图一:
在初识操作系统之前,我们需要对计算机的硬件组成做一定的了解。本篇优先对数据信号做初步分析,暂时不考虑控制信号(操作系统是前人花了几十年时间研究出来的,不是短短几句话就能说清楚的)。
需要了解的几个概念(博主我而言):
👉:输入设备 -> 键盘、鼠标、扫描仪、写板、磁盘、网卡
👉:中央处理器(CPU) -> 运算器和控制器等
👉:输出单元 -> 显示器、打印机、网卡、磁盘
注:磁盘 -> 外存 存储器 -> 内存
问:为什么程序必须要先加载到内存中?为什么不直接交付给运算器处理,再有运算器交付给输出设备?
答:先说明后者,确实可以这么做,但是成本会很大,因为输入输出设备和cpu之间的输入输出速度不匹配,因此需要花更大的代价去匹配。
再说明前者,为了能使计算机家用,就得解决成本问题,存储器(内存)的出现使得输入输出设备和cpu之间的运算关系相匹配,让计算机以更低廉的价格走向普通用户。
总结:
1、硬件上的结构决定了软件该如何编写。
2、不同计算机之间的通信可以抽象成两个冯·偌伊曼结构体系之间的通信
二、操作系统(Operator System)
操作系统包括:
内核:进程管理、内存管理、文件管理、驱动管理
其他程序
操作系统设计的目的:
• 对下,与硬件交互,管理所有的软硬件资源• 对上,为用户程序(应用程序)提供⼀个良好的执行环境
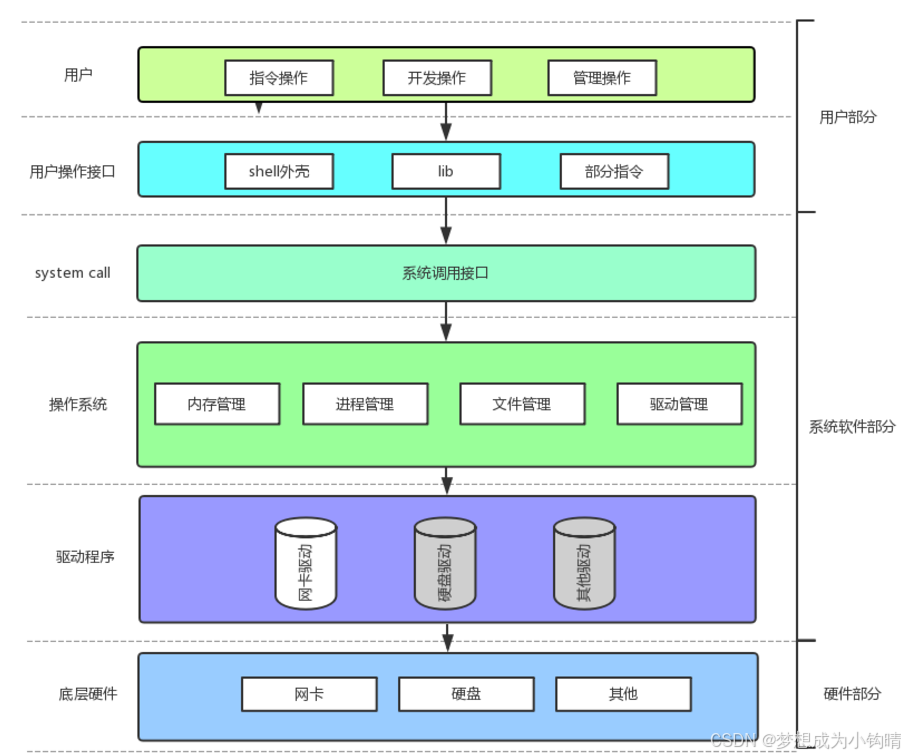
shell:命令解释器(command interpreter)
👉:将使用者的命令翻译给核心处理
👉:将核心的处理结果翻译给使用者
注:其中bash是命令解释器之一,每当用户登录服务器时,操作系统会给每一个用户分配bash
概念补充说明:
我们所写的程序最终形成可执行程序后,都要通过系统调用接口去访问操作系统内部,再经过驱动程序,最终输出到对应的硬件上。比如打印一个"hello world"需经过系统调用接口,访问操作系统,操作系统进行驱动管理,再经驱动程序,最终打印到硬件上(显示器)。
问:操作系统是如何对底层硬件进行控制的?
答:首先可以明确一点的是,操作系统并非直接对底层硬件进行控制,而是先对底层硬件的属性进行描述,例如可以创建一个结构体,将数据存储起来,再定义一个高效的数据结构将结构体存储到数据结构中(组织起来)进行管理,这样操作系统就能够通过对数据结构的增删查改而间接控制底层硬件,就好比校长不需要跟学生见面,只需知道一个学生的所有信息,就可以对学生进行管理。
简言之:操作系统用结构体描述硬件属性/信息,再用高效的数据结构将结构体存储(组织)起来。
三、进程
前面提到操作系统分为:进程管理、内存管理、文件管理、驱动管理;本篇先谈进程管理
进程的概念:
课本上说:
进程是一个程序的执行实例或是正在执行的程序等;实际上:进程 = 内核数据结构对象 + 自己的代码和数据;
更准确的说:进程 = PCB(task_struct) + 自己的代码和数据;
注:PCB中有内存指针能够帮助找到对应的代码和数据
PCB:进程控制块
前面我们提到,操作系统用结构体描述硬件属性/信息,再用高效的数据结构将结构体存储(组织)起来。而进程信息就被存放再一个叫做进程控制块的数据结构当中,可以理解为进程属性的集合。Linux操作系统下的PCB是:task_struct(描述进程的结构体)
注1:当一个进程启动时,该进程的所有信息会存储在进程控制块的数据结构中,同时对应的代码还会拷贝到内存当中,因此有:进程 = PCB + 自己的代码和数据。
注2:操作系统对硬件的管理与进程相似,开机时,操作系统对硬件属性(信息)进行描述并存储到PCB中组织起来进行管理调用
有关进程的指令:
getpid():获取当前进程pid
getppid():获取当前进程父进程的pid
ps axj :查看系统中所有进程
ps axj | grep 进程名:查找特定进程
ps axj | grep -v 进程名:查找特定进程,并避免显示grep中的重名进程
ls /proc: 当前正在运行的进程
ls/proc/pid -dl :查找对应进程的位置,注:进程结束就找不到了
chdir("/相应路径"):更改当前进程的路径
fork():创建子进程
有关bash:命令解释器(本质也是一个子进程)
👉:每当用户登录服务器时,操作系统会给每一个用户分配bash
👉:ls pwd mkdir touch都是进程,且所有的父进程都是bash
补充1:有关进程和作业/程序
👉:一个程序/作业可以有多个进程,因此说进程和程序一一对应是错误的。
👉:程序是静态的,进程是动态的
补充2:有关抢占式多任务处理中
如果进程被抢占,那么所有cpu寄存器的内容、页表指针、程序计数器都将被保存下来。而全局变量、程序内的数据不一定(因为当前变量和数据不一定在使用)
四、进程状态
学前须知:
👉:一个CPU一般只有一个调度队列,调度队列中存放着运行着的进程
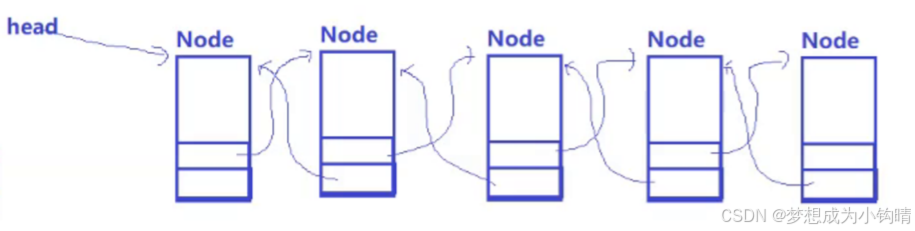
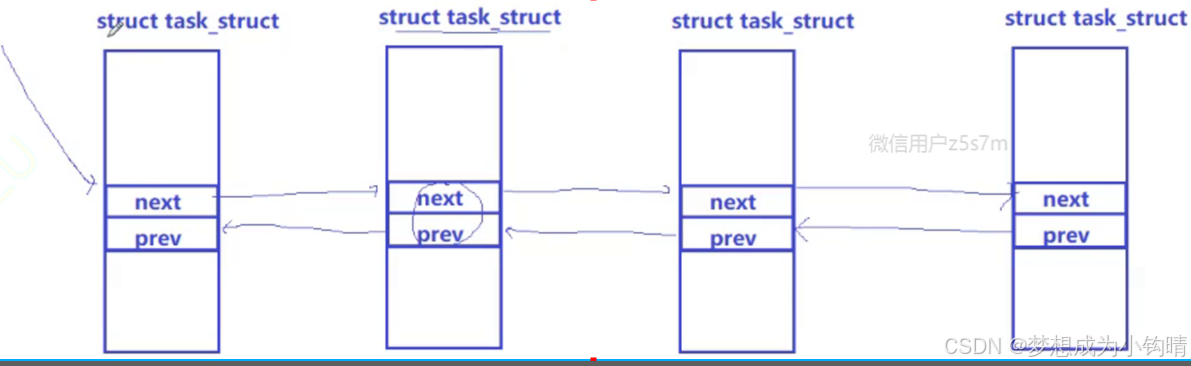
👉:PCB是一个双链表数据结构
👉:Linux内核中,PCB节点既可以是数据结构A的成员,又可以是数据结构B的成员(稍后论述)
进程状态:
1、R 运行状态(running):只要进程在调度队列中,就处在运行状态
2、S 浅睡眠状态(sleeping):也叫阻塞,是操作系统等待外部设备或者资源就绪,外部设备包含:键盘、显示器、网卡、磁盘、摄像头、话筒等,当这些外部设备被占用无法使用时,就会处于阻塞状态,系统会等待其准备就绪。再比如一串代码中的 scanf(),系统会等待键盘输入。
3、D 深睡眠状态(disk sleeping):也是一种阻塞,和浅睡眠阻塞类似,区别在于浅睡眠阻塞操作系统能够让其强制停止,而深睡眠状态不行。
补充1:阻塞状态
阻塞状态是将处于调度队列中的PCB移到等待队列中,在等待队列完成相应的任务后,再调回调度队列,本质是对数据结构的增删查改。处于阻塞的进程可以有很多,想想现实生活中,你开了很多程序,它们都等待你去输入,此时会占用内存。
补充2:阻塞挂起
当系统内存比较吃紧,会把处于等待队列中的PCB的代码和数据唤出到外设(磁盘)上,内存此时只有PCB,当需要使用时,再会把PCB对应的代码和数据换回到内存中,变成一个完整的进程。
补充3:运行挂起
当系统内存相当吃紧,会把调度队列中,处于末端的进程按阻塞挂起的方式进行处理
补充4:Linux内核节点的定义
通过以上叙述,可以发现,PCB既是调度队列中的节点、又是等待队列中的节点,但PCB本身又是一个双链表节点。
问:他是如何存储到不同数据结构当中的?
答:相较于之前学习的数据结构(通过节点指针直接指向下一个节点的地址)而言,Linux中的节点,是将节点定义为PCB中的成员之一,而节点中的节点指针指向的是下一个PCB中的节点的地址,而并非PCB本身的地址。
图一:原先的数据结构(节点指针指向下一个节点的地址)
图二:Linux中的PCB(节点指针指向的是下一个PCB中的节点地址)
问:那么操作系统如何访问PCB中其他成员变量呢?
答:通过指针偏移量来获取PCB中的其他成员。
于是有了上述认识后,就可以明白一个PCB,可以满足任何数据结构,只要通过相应的方法进行遍历和访问即可。
4、T 停止状态(stop):当系统认为进程有问题,会暂停进程让用户查看
5、t 追踪状态(tracing stop):debug时,遇到断点时,进程被暂停会处于该状态
6、Z 僵尸状态(zombie):一个子进程先于父进程退出,但是他的父进程没有接收到子进程的退出信息,这个子进程就会处于僵尸状态
有关僵尸状态的补充:
👉:如果父进程一直不管子进程,不回收,不获取子进程的退出信息,那么子进程一直处于僵尸状态,会导致内存泄露的问题
👉:普通进程退出时,内存泄露的问题就会消失,这种影响不大。但对于常驻内存的进程,比如操作系统、杀毒软件等,这些进程如果存在内存泄露的问题,那么就会比较麻烦,这也就是为什么有些系统会越用越卡。
👉:僵尸进程已经退出了,因此不会再次被kill杀死,也不会自动退出。
7、孤儿进程:父进程先退出,子进程还在,那么子进程就会被1号进程(init/systemd)领养,被领养的子进程就成为孤儿进程
有关孤儿进程的补充:
👉:被1号进程领养的进程一般会变成后台进程,ctrl+c 无法终止该进程,只能通过kill -9 pid终止
👉:之所以存在领养,是为了避免没有父进程的子进程退出后变成僵尸进程的状态。
五、进程优先级
优先级的概念:
进程得到CPU资源的先后顺序
学前须知:
👉:为什么存在优先级?
答:因为目标资源稀缺,导致要通过优先级来确认谁先谁后的问题。举一个简单的例子,学校食堂的打饭窗口有限,那么谁到食堂的同学优先级更高,而后到的优先级更低。
👉:现代操作系统是基于时间片的分时操作系统,每一个进程都有一定的执行时间,优先级可能会变化,但是变化的幅度不能太大,因为分数操作系统的优先级需要考虑公平性。
注:另一种操作系统为实时操作系统,该系统常用在工业(汽车)领域。举一个例子,在一般情况下,分时操作系统是大家和和睦睦的按优先级的顺序一个一个执行下去(也会存在插队情况,这个稍后讨论)。但是对于实时操作系统而言,有一些进程是需要强制变为最高优先级率先执行,例如自动驾驶的刹车系统,倘若前面有障碍物,那么这时刹车进程的优先级一定是最高的,如果是分时操作系统,那么就完蛋了。
Linux中常见的信息:
UID:执行者的身份
注1:当一个文件被创建时,系统会记录它的UID,当用户去执行文件中相应进程时,也会记录UID,系统会通过比对二者的UID是否相等来判断用户是否拥有该权限。
注2:我们在linux中的每一个操作,其实都是进程,我们与操作系统的交互都是通过进程来的,操作系统不认人,只认UID。
PID:该进程的代号
PPID:该进程是由哪个进程衍生而来的,即父进程
PRI:该进程可被执行的优先级,值越小,优先级越高,默认进程的优先级都是:80
NI:该进程的nice值,用于修正进程的优先级,NI∈[-20,19]。
注1:进程真实的优先级 = PRI(默认) + NI
注2:如果进程优先级设定不合理,会导致优先级低的进程长时间得不到CPU资源,进而导致“进程饥饿”
★★★并发:多个进程在一个CPU下采用进程切换的方式,在一段时间内,让多个进程都得以推进。
举一个电学生能懂的例子:呼吸灯
呼吸灯从视觉上看是灯逐渐由亮变暗的过程,但本质上是控制灯的亮暗的持续时间,一开始亮的时间久,灭的时间短→亮的时间短,灭的时间久,从而在视觉上达成呼吸灯的效果以欺骗人的眼睛。
而CPU通过高频切换不同进程,利用人的听觉视觉差,来达成多个进程同时推进的目的。
对比两个例子,不难发现,呼吸灯中,灯确实灭了,但是灭的时间太短,人眼分辨不出;CPU中的进程确实停了,但是停的时间太短,以至于人的听觉和视觉都分辨不出。
六、进程切换
学前须知:
👉:一旦一个进程占有CPU,因为时间片的存在,并不会把自己的代码运行完。
👉:CPU中,存在很多寄存器,用来处理各种信息,不同寄存器会保存当前进程的临时数据
👉:寄存器是CPU内部的临时空间
👉:寄存器 != 寄存器里的数据,寄存器是空间,空间只有一个;而数据是内容,内容是可以改变的。
★★★进程切换(简化版):这个过程由调度器完成
假设现在有两个进程A、B,进程A正在运行中,进程B尚未执行。
问:现将运行进程B,那么调度器该怎么做?(只考虑两个进程间,更复杂的稍后说)
答:在将进程A切换至进程B之前,必须将进程A存储在CPU寄存器当中的上下文数据临时保存在 x 当中(之后会叙述这个x是什么),当保存完毕后,进程A会被调度器调度到另一个队列中(这个也稍后说明)。此时寄存器中有关进程A上下文的临时数据已经无用了,调度器在调度进程B时,能够将其直接覆盖。当要重新调度进程A时,进程B与先前执行一样的操作,然后进程A必须把先前保存的数据恢复到CPU当中,这样才能继续执行上次尚未完成的任务!
问题1:这个x是什么?
答:PCB,当代计算机能够通过PCB去找到TSS(任务状态段)。
注:TSS也是一个数据结构,专门保存上下文数据,为了避免PCB过大的问题。
问题2:怎么区分新的进程和已经调度过的队列?
答:PCB中有一个标记位(bool 类型),没有运行过的程序是0,只要运行过就为1。
6.1:Linux2.6内核进程O(1)调度队列——另一个队列的问题
学前须知:一个CPU拥有一个runqueue

queue[140]:
队列数组,下标就是队列的优先级,每一个队列数组中包含了多个PCB,由双链表构成。
普通优先级:100~139
实时优先级:0~99
bitmap[5]:为了能够快速查找队列。
对于32位操作系统,32*5一共对应了160个位,0~139对应了140个不同的优先级,后21个位舍弃。当我们要查找优先级为120的队列时,先通过bitmap每32位一查找,再在bitmap[4]中寻找具体属于哪个优先级。
nr_active:当前队列中有多少个进程
*active(活跃进程)和*expired(过期进程):
runqueue中会定义一个结构体,这个结构体中包含了:
1、nr_active 2、bitmap 3、queue[140]
runqueue会创建两个结构体数组:struct rqueue_elem pro_arry[2]
*active 和 *expired 分别指向 pro_arry[0] 和 pro_arry[1]
即:
struct rqueue_elem* active = &pro_arry[0]
struct rqueue_elem* expired = &pro_arry[1]
★★★进程切换(复杂版):同样是通过调度器进行完成
调度器通过 active指针 找到相应结构体位置,再访问 nr_active 成员确认当前有多少进程,若有进程存在,再通过 bitmap[5] 快速确认下标,再索引 queue(队列数组),找到目标队列,再将(双链表)队列链表头对应的 PCB 放到 current指针 中,再把 current指针 指向的代码放到cpu中执行。因为时间片的存在,该代码不会执行完,将该进程调度至 *expired 对应的结构体中并存放在相应的 queue 当中,这样 *active 中的进程会越来越少,而*expired 中的进程会越来越多,当 *active 不再有进程时,执行 swap(&active,&expired),再次循环上述过程,直至所有进程全部执行完毕。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









