







总结上篇adaboost 学习效果并不好
XGBoost简介
XGBoost(eXtreme Gradient Boosting)是一种基于Boosting的 gradient boosting framework,它使用了一种称为“树的叠加”(tree boosting)的技术来构建模型。XGBoost 是一种高效且可扩展的 gradient boosting 算法,它在许多机器学习任务中表现出色,如分类、回归和排名等。
XGBoost 的核心思想是通过构建一系列有序的决策树来逐步改进模型,每个树都尝试纠正前一个树的错误。这种方法通常可以提高模型的准确性,同时减少过拟合的风险。XGBoost 的主要特点包括:
- 支持并行和分布式计算,可以在多个 CPU 或 GPU 核心上运行,提高训练速度。
- 具有高效的内存使用策略,可以在有限的内存情况下处理大规模数据。
- 提供了许多超参数来优化模型性能,如学习率、最大深度、最小样本数等。
- 支持 L1 和 L2 正则化,可以防止过拟合和减少模型复杂度。
具体实现步骤:
- 首先,将训练数据分为多个块,每个块包含一个或多个样本。
- 然后,构建第一个决策树,用于预测训练数据的标签。
- 计算第一个决策树的损失函数值,并将其记录为残差(residual)。
- 构建第二个决策树,用于预测残差。这个树的目标是最小化第一个决策树的残差。
- 计算第二个决策树的损失函数值,并将其记录为新的残差。
- 重复进行决策树的构建,直到达到预设的迭代次数或残差达到满意水平。
混淆矩阵(sklearn.metrics.confusion_matrix)
混淆矩阵(confusionmatrix)也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同的侧面反映了图像分类的精度。
在人工智能中,混淆矩阵(confusionmatrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。混淆矩阵是通过将每个实测像元的位置和分类与分类图像中的相应位置和分类相比较计算的。
参数解析
- y_true: 是样本真实分类结果
- y_pred: 是样本预测分类结果
- labels:是所给出的类别,通过这个可对类别进行选择
- sample_weight : 样本权重
bug1:ValueError: Invalid classes inferred from unique values of y. Expected: [0 1 2 3], got [1 2 3 4]
表示你必须将分类标签处理一下,从0开始。解决办法很简单,在训练数据和预测数据使用标签编码器(lableEncoder)
代码如下:
from sklearn.preprocessing import LabelEncoder
leb=LabelEncoder()
y_train=leb.fit_transform(y_train)
xgb_module=xgb.XGBClassifier().fit(X_resample,y_resample.values)
pred=xgb_module.predict(X_test)
pred=leb.inverse_transform(pred)
real=y_test
print(f"混淆矩阵:{
confusion_matrix(real,pred)}")
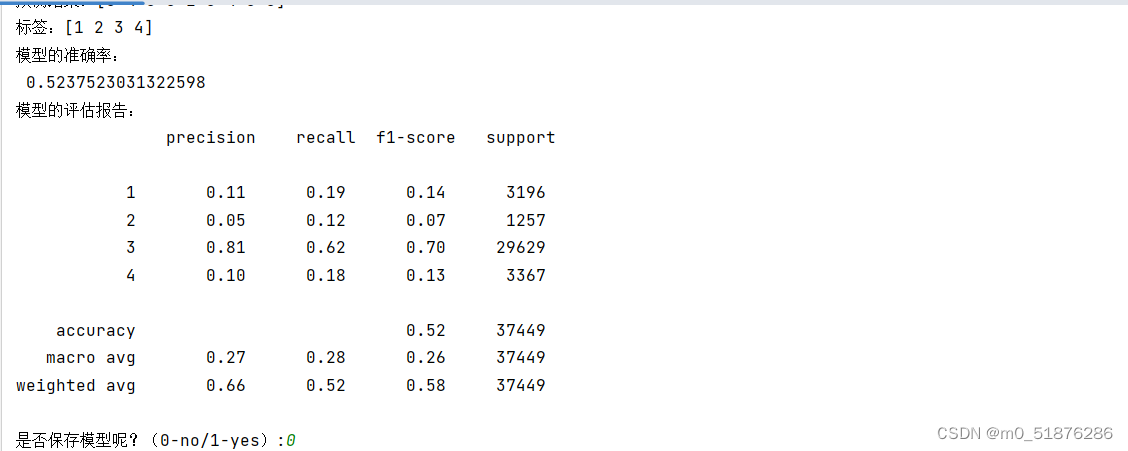
print(f"模型的预测正确率:{
accuracy_score(real,pred)}")
print(f"模型评分为:{
classification_report(real,pred)}")
bug2:ValueError: Target is multiclass but average=‘binary’. Please choose another average setting, one of [None, ‘micro’, ‘macro’, ‘weighted’].
测评模型的方法里面加一种’f1_micro’其他也可以。
代码如下:
print("开始网格法分析")
clf = GridSearchCV(xgb.XGBClassifier(booster='gbtree',eval_metric='mlogloss',num_class=4,objective='multi:softmax'), param_grid=param_dict,scoring='f1_micro', cv=2, n_jobs=-1, verbose=1)
best_result=clf.fit(X_resample, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









