







 本文详细介绍了SQL语言的结构、分类(DDL、DML、DQL、DCL),包括数据库设计、创建和操作、数据增删改查、分组查询、事务处理以及索引优化。涵盖了MySQL中关键概念和实例,帮助读者理解SQL在关系型数据库管理中的核心作用。
本文详细介绍了SQL语言的结构、分类(DDL、DML、DQL、DCL),包括数据库设计、创建和操作、数据增删改查、分组查询、事务处理以及索引优化。涵盖了MySQL中关键概念和实例,帮助读者理解SQL在关系型数据库管理中的核心作用。
SQL:结构化查询语言。一门操作关系型数据库的编程语言,定义操作所有关系型数据库的统一标准。
通用语法
1、SQL语句可以单行或多行书写,以分号结尾。
2、SQL语句可以使用空格/缩进来增强语句的可读性。
3、MySQL数据库的SQL语句不区分大小写。
4、注释:
-
单行注释:-- 注释内容 或 # 注释内容(MySQL特有)
-
多行注释: /* 注释内容 */
分类(DDL、DML、DQL、DCL)
SQL语句根据其功能被分为四大类:DDL、DML、DQL、DCL
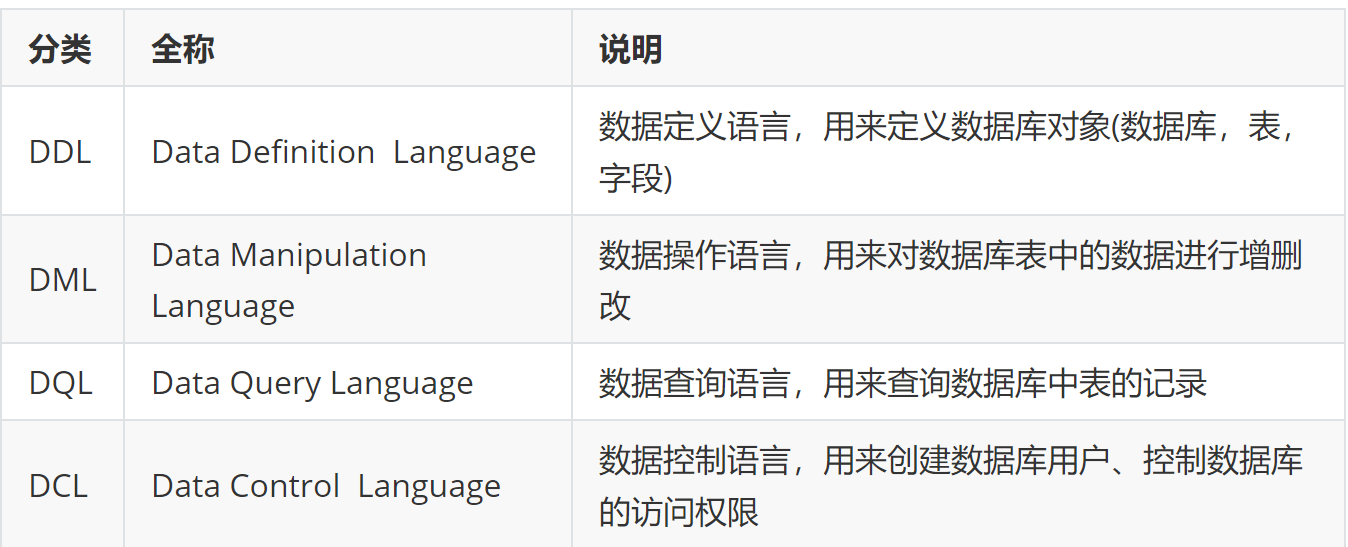
数据库设计-DDL
工作中一般都是直接基于图形化界面操作
数据库操作
-- 查询所有数据库
show databases;
-- 查询当前数据库
select database();
-- 创建数据库
create database [ if not exists ] 数据库名;
-- 使用数据库
use 数据库名 ;
-- 删除数据库
drop database [ if exists ] 数据库名 ;约束
 例子
例子
create table tb_user (
id int primary key auto_increment comment 'ID,唯一标识', #主键自动增长
username varchar(20) not null unique comment '用户名',
name varchar(10) not null comment '姓名',
age int comment '年龄',
gender char(1) default '男' comment '性别'
) comment '用户表';数据类型
MySQL中的数据类型有很多,主要分为三类:数值类型、字符串类型、日期时间类型
数值类型常用:tinyint int double
字符串类型常用:char varchar 一个不可变一个可变
日期类型常用:date datetime
数据库操作-DML
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
-
添加数据(INSERT)
-
修改数据(UPDATE)
-
删除数据(DELETE)
-
查找数据(SELECT)
增加(insert)

修改(update)

删除(delete)

查找(select)
数据库操作-DQL
单表设计
DQL英文全称是Data Query Language(数据查询语言),用来查询数据库表中的记录。
查询关键字:SELECT
去重关键字:
select distinct 字段列表 from 表名;语法:
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后条件列表
LIMIT
分页参数
分组查询:分组查询通常会使用聚合函数进行计算。
查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
select gender, count(*)
from tb_emp
group by gender; -- 按照gender字段进行分组(gender字段下相同的数据归为一组)where与having区别(面试题)
-
执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
-
判断条件不同:where不能对聚合函数进行判断,而having可以。
常用聚合函数:
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
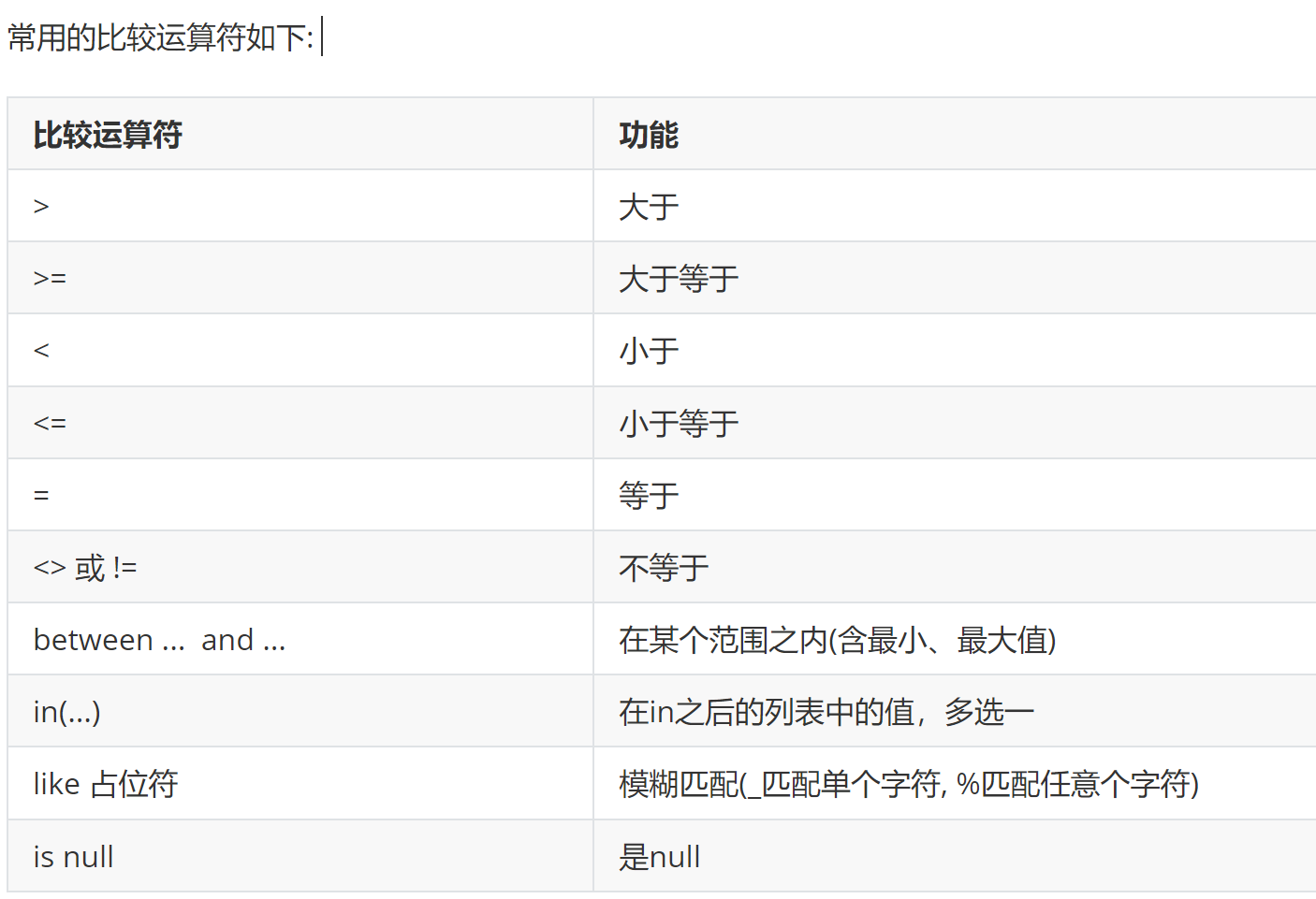
比较运算符
分页关键字:limit
起始索引 = (查询页码 - 1)* 每页显示记录数
多表设计
一对多
在多的一方设计外键(作用:保证了数据的完整性和一致性 )
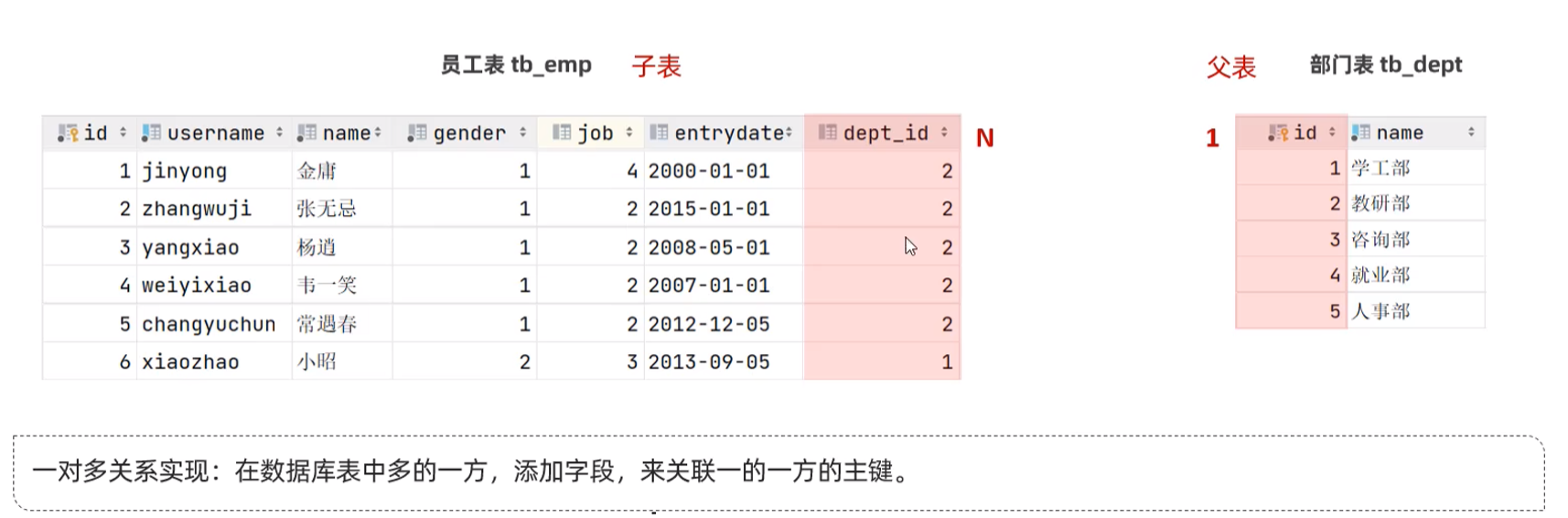
注意:在现在的企业开发中,很少会使用物理外键,都是使用逻辑外键。 甚至在一些数据库开发规范中,会明确指出禁止使用物理外键 foreign key
物理外键和逻辑外键
-
物理外键
-
概念:使用foreign key定义外键关联另外一张表。
-
缺点:
-
影响增、删、改的效率(需要检查外键关系)。
-
仅用于单节点数据库,不适用与分布式、集群场景。
-
容易引发数据库的死锁问题,消耗性能。
-
-
-
逻辑外键
-
概念:在业务层逻辑中,解决外键关联。
-
通过逻辑外键,就可以很方便的解决上述问题。
-
一对一
一对一 :在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)

多对多
一个学生可以选多门课,一门课可以被多个学生选择。
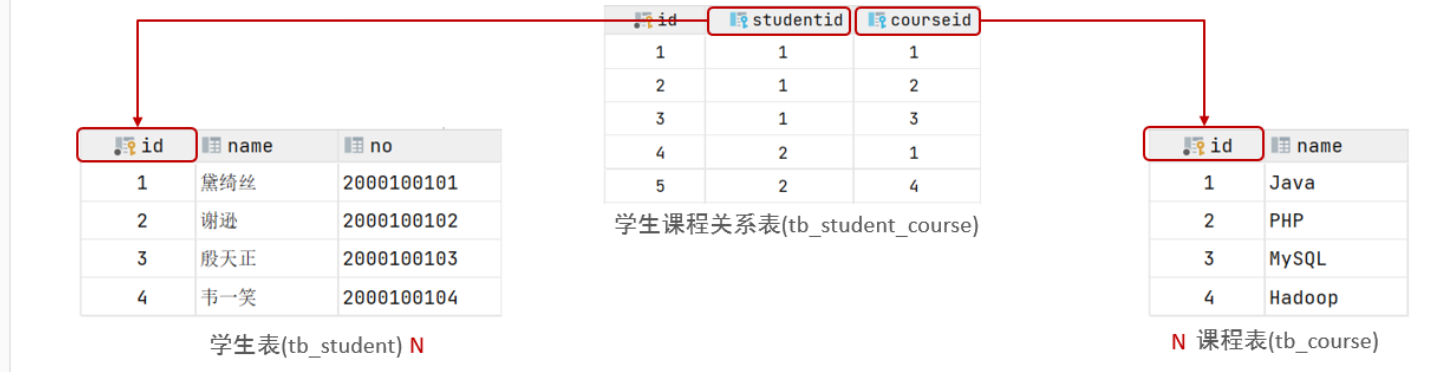

多表查询
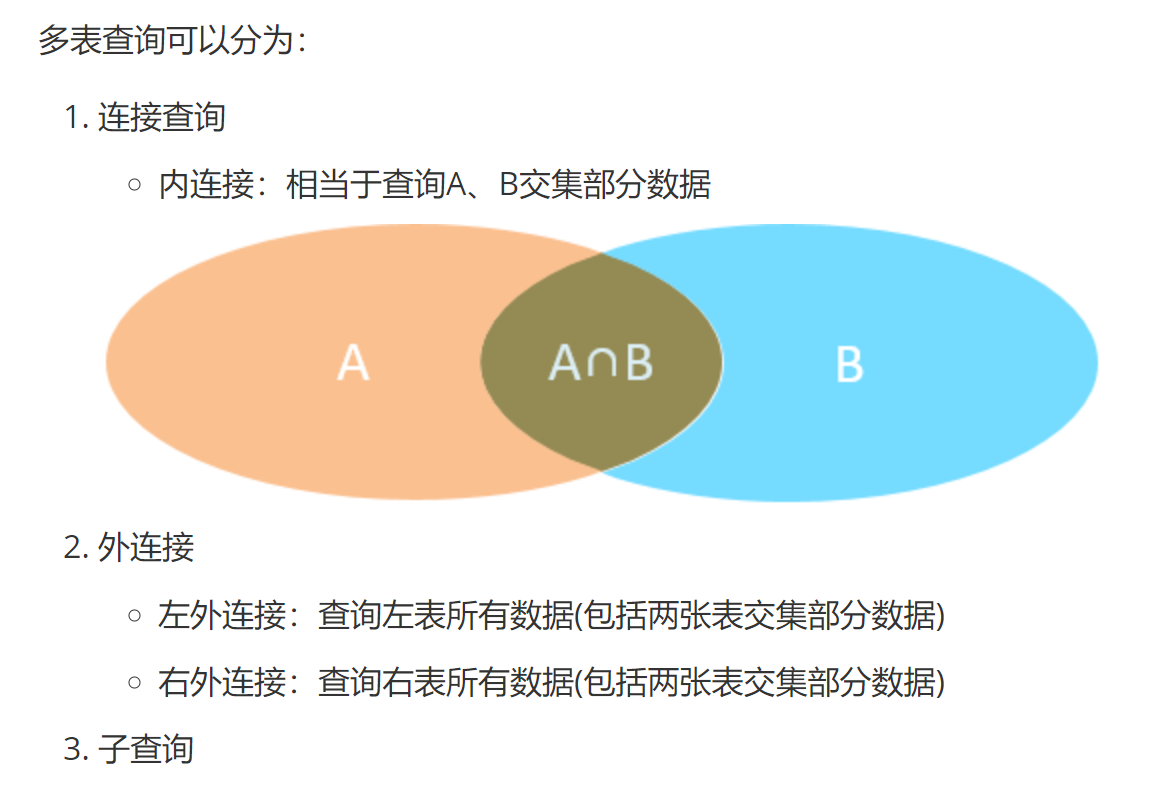
内连接
- 隐式内连接
- 显式内连接
外连接
左外连接 和 右外连接。(主要是用左外连接) 左外连接包含,左表所有数据
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;子查询
SQL语句中嵌套select语句,称为嵌套查询,又称子查询。
-
标量子查询(子查询结果为单个值[一行一列])
-
列子查询(子查询结果为一列,但可以是多行)
-
行子查询(子查询结果为一行,但可以是多列)
-
表子查询(子查询结果为多行多列[相当于子查询结果是一张表])
事务
解决数据不一致问题
事务作用:保证在一个事务中多次操作数据库表中数据时,要么全都成功,要么全都失败
-- 开启事务
start transaction ;
-- 删除学工部
delete from tb_dept where id = 1;
-- 删除学工部的员工
delete from tb_emp where dept_id = 1;
-- 提交事务 (成功时执行)
commit ;
-- 回滚事务 (出错时执行)
rollback ;四大特性:
-
原子性(Atomicity):事务是不可分割的最小单元,要么全部成功,要么全部失败。
-
一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
-
隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
-
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
事务的四大特性简称为:ACID
索引
作用:使用索引可以提高查询的效率
-- 添加索引
create index idx_sku_sn on tb_sku (sn); #在添加索引时,也需要消耗时间
-- 查询数据(使用了索引)
select * from tb_sku where sn = '100000003145008';MySQL索引结构:B+Tree(多路平衡搜索树)
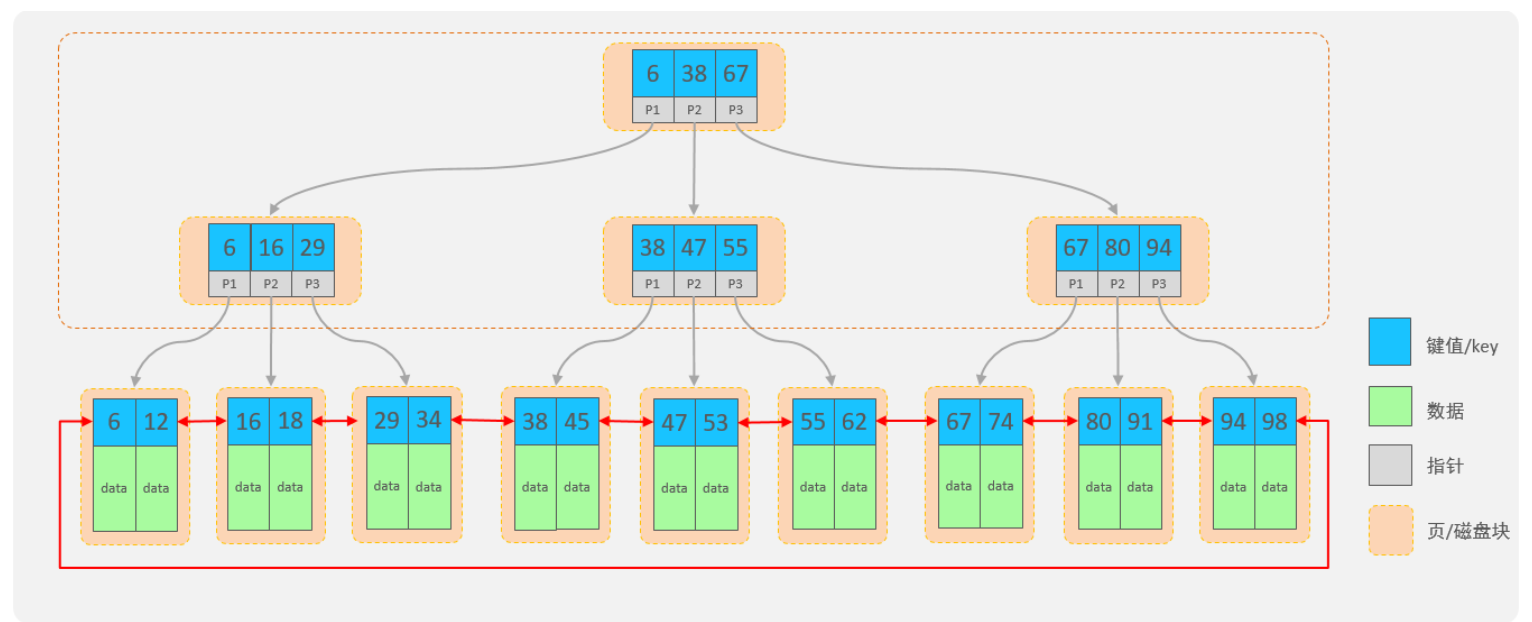
B+Tree结构:
-
每一个节点,可以存储多个key
-
节点分为:叶子节点、非叶子节点
-
叶子节点,就是最后一层子节点,所有的数据都存储在叶子节点上
-
非叶子节点,不是树结构最下面的节点,用于索引数据
-
-
为了提高范围查询效率,叶子节点形成了一个双向链表,便于数据的排序及区间范围查询
条件函数case
CASE 测试表达式
WHEN 简单表达式1 THEN 结果表达式1
WHEN 简单表达式2 THEN 结果表达式2 …
WHEN 简单表达式n THEN 结果表达式n
[ ELSE 结果表达式n+1 ]
END字符串操作
切割、截取、删除、替换
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|

















 33万+
33万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









