









近日工作中遇到某品牌电子签章系统生成的PDF文件若直接使用十六进制查看器打开,会出现转义字符被直接以ASCII编码转换为16进制字符串的问题,导致提取的文件无法匹配ASN.1格式,无法进一步对签章有效性进行检查。如下图:

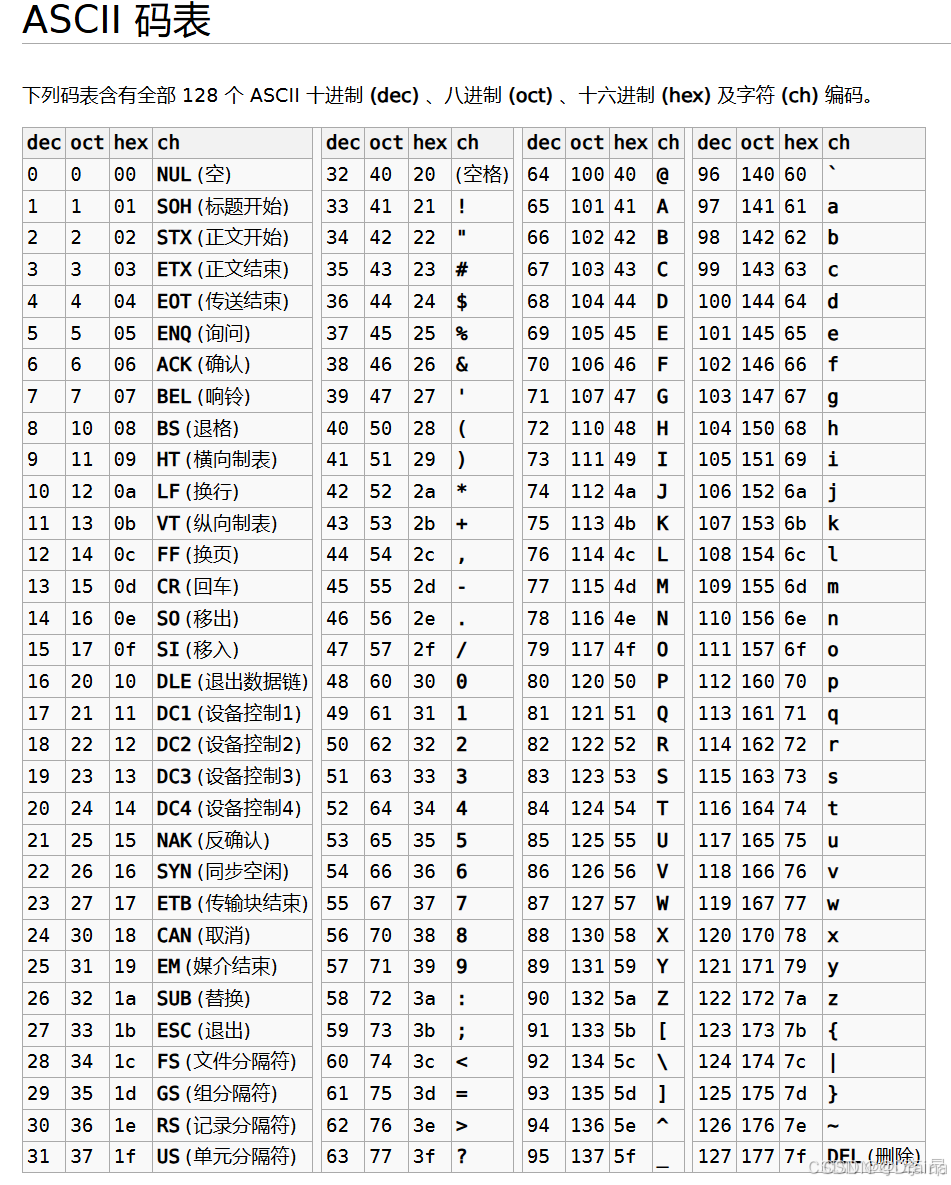
如果感觉不太理解,可以查阅ASCII码表,表中对转义字符有特定的对应编码,若直接挨个字符进行解码,就会出现一个字节被转换为两个字节且丢失原本的信息。
针对这个问题,建议通过编写脚本的方式对错误转码的十六进制字符串进行修正,只需要通过一次遍历即可。实现关键代码如下:
def process_hex_escape(input_hex):
escape_map = {
'66': '0C', # \f
'62': '08', # \b
'6E': '0A', # \n
'72': '0D', # \r
'74': '09', # \t
'5C': '5C', # \\
'76': '0B', # \v
'61': '07' # \a
}
input_hex = input_hex.upper()
result = []
i = 0
length = len(input_hex)
while i < length:
if i + 2 <= length and input_hex[i:i + 2] == '5C': #检测到5c(反斜杠)
if i + 4 <= length:
next_two = input_hex[i + 2:i + 4] #提取反斜杠后两字符
if next_two in escape_map: #若与替换表匹配
result.append(escape_map[next_two]) #向结果字符串插入替换后的字符
i += 4 #跳过5c和其之后的两字符
continue
i += 2 #未成功匹配则只跳过5c(删除单个的反斜杠)
else:
result.append(input_hex[i:i + 2] if i + 2 <= length else input_hex[i]) #没有5c则直接将原字符串两位插入结果字符串
i += 2
return ''.join(result)通过同事交流、实际操作,我们发现不通过脚本而使用文本查看工具进行批量替换是操作繁琐且容易出错的,因为这个问题替换的优先级是出现在前面的字符优先替换,替换后的字符不再参与替换。再加上存在5C5C被替换为5C的情况,若进行批量替换操作不当易出现多换结果:
如:5C5C66——>5C66
5C66——>0C
通过脚本转换后生成的16进制字符串,通过十六进制编辑器输入新文件后,即可通过ASN.1工具进行解析,开展下一步工作了。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











