









 批量归一化(BatchNormalization)是一种解决深度学习中梯度弥散问题的技术,尤其在数据分布范围较广时效果显著。它通过对数据进行标准化处理,使网络在训练时能更有效地优化参数。在前向传播中,BatchNorm计算输入的均值和标准差,并利用γ和β调整数据分布。在反向传播中,更新网络权重。提供的代码示例展示了BatchNorm层在TensorFlow中的应用及其在训练过程中的变量变化。
批量归一化(BatchNormalization)是一种解决深度学习中梯度弥散问题的技术,尤其在数据分布范围较广时效果显著。它通过对数据进行标准化处理,使网络在训练时能更有效地优化参数。在前向传播中,BatchNorm计算输入的均值和标准差,并利用γ和β调整数据分布。在反向传播中,更新网络权重。提供的代码示例展示了BatchNorm层在TensorFlow中的应用及其在训练过程中的变量变化。
提出原因
使用Sigmoid 激活函数时如果数据的分布范围较大,训练时容易出现梯度弥散现象,因此提出了Batch Normalization的方法
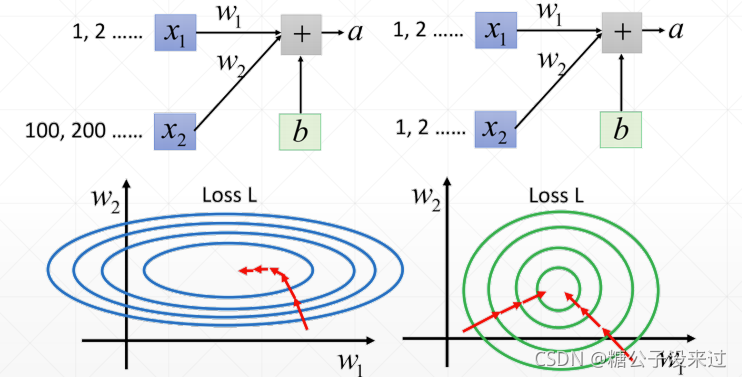
另外,从另一个角度,如果输入的数据大小差别过大,就会导致参数w在某一个方向上梯度变化不明显而另一个方向上梯度变化比较大,这个时候的网络优化的效率是比较低的。如果数据输入都是在一定范围内的话,网络优化起来效率就会比较高,就像下面李宏毅老师的图一样
Normalization

Norm
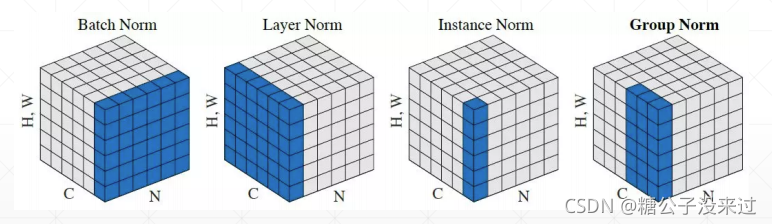
如上图所示,有很多Norm的方法,但其实只是角度不同,每次处理的数据位置不一样,原理是一样的
Batch Normalization
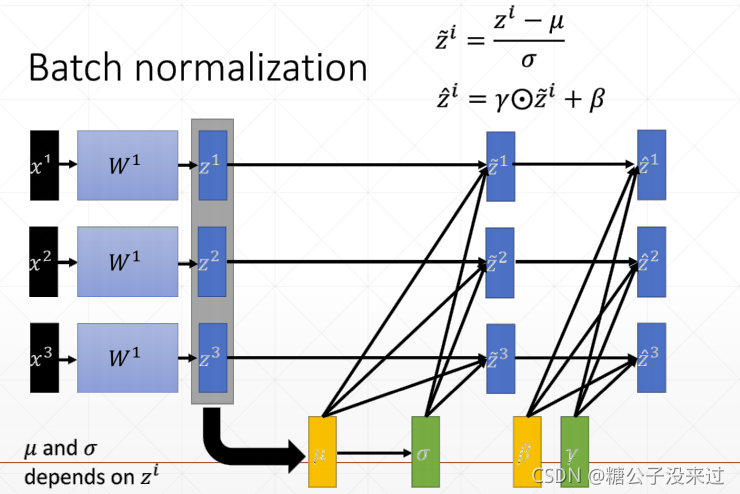
μ是均值,σ是标准差,γ和β是用来给数据一个偏置用的。比如经过μ和σ计算完后,数据符合N(0,1)正态分布,γ和β处理完,数据符合N(β, γ)分布
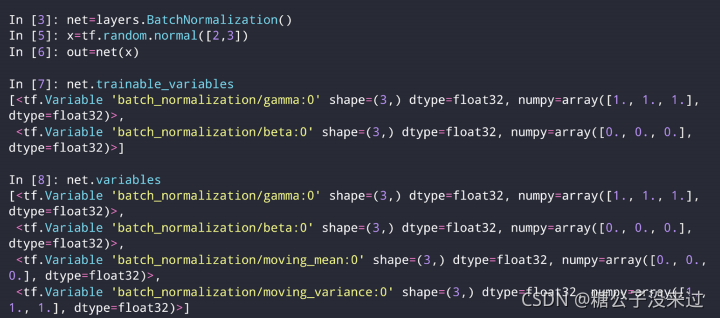
layers.BatchNormalization

算法

BatchNorm for Image

Forward update
Backward update

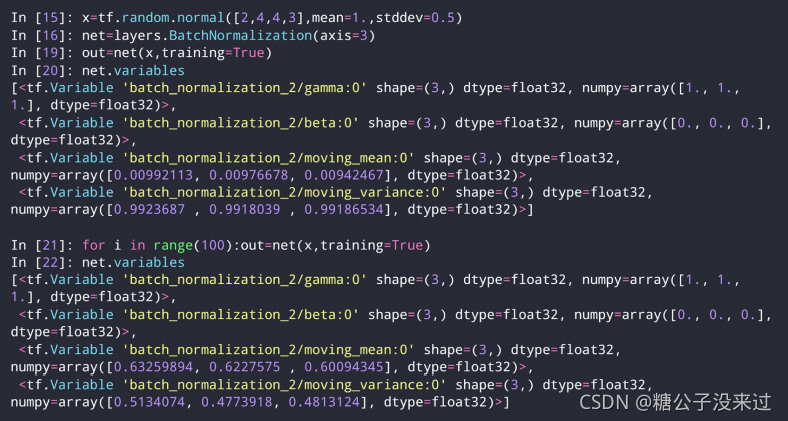
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers
# 2 images with 4x4 size, 3 channels
# we explicitly enforce the mean and stddev to N(1, 0.5)
x = tf.random.normal([2,4,4,3], mean=1.,stddev=0.5)
net = layers.BatchNormalization(axis=-1, center=True, scale=True,
trainable=True)
out = net(x)
print('forward in test mode:', net.variables)
out = net(x, training=True)
print('forward in train mode(1 step):', net.variables)
for i in range(100):
out = net(x, training=True)
print('forward in train mode(100 steps):', net.variables)
optimizer = optimizers.SGD(lr=1e-2)
for i in range(10):
with tf.GradientTape() as tape:
out = net(x, training=True)
loss = tf.reduce_mean(tf.pow(out,2)) - 1
grads = tape.gradient(loss, net.trainable_variables)
optimizer.apply_gradients(zip(grads, net.trainable_variables))
print('backward(10 steps):', net.variables)

















 900
900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









