







并行编程的操作模式
什么是操作模式
🌟并行计算:大量线程合作共同解决一个问题
⭐️操作模式:如何对数据进行操作
常见的操作模式
1.映射(Map)
-
概念:将输入的数据每个元素使用相同的操作,例如数组中每个元素+1。
-
输入与输出数据关系:一对一关系。
-
应用:图像中像素操作,信号处理中滤波等。
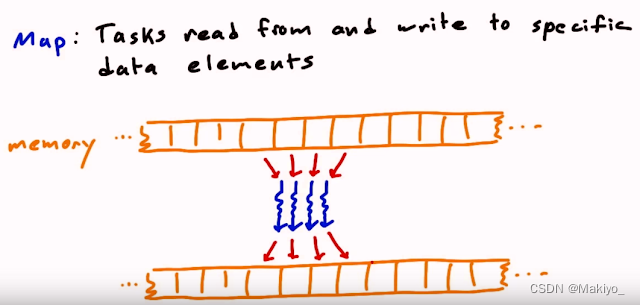
2.聚合(Gather)
-
概念:从一个输入数据中根据索引或特定条件提取特定元素,生成新的数据,例如卷积运算。
-
输入与输出数据关系:多对一关系。
-
应用:数据压缩,卷积运算等。
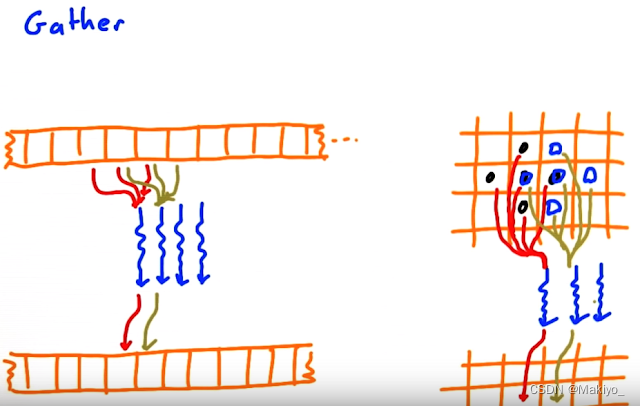
3.分散(Scatter)
-
概念:将一个输入数据分散到输出数据中特定位置,例如将数据分散到不同的数组位置。
-
输入与输出数据关系:一对多关系。
-
应用:图像渲染等。
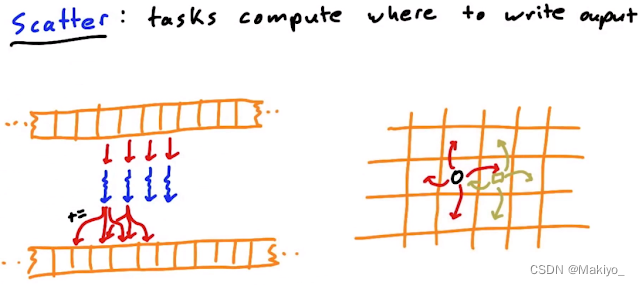
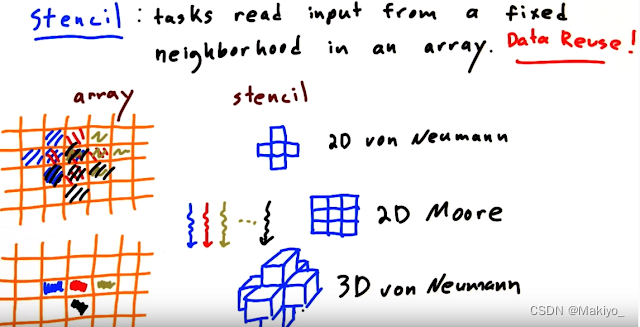
4.模板(Stencil)
-
概念:以固定的模式读取相邻的内存数值生成数据,一般是局部区域,例如图像处理中使用卷积核进行滤波
-
输入与输出数据关系:几个对一关系。
-
应用:图像处理,输入与输出数据关系:一对多关系。
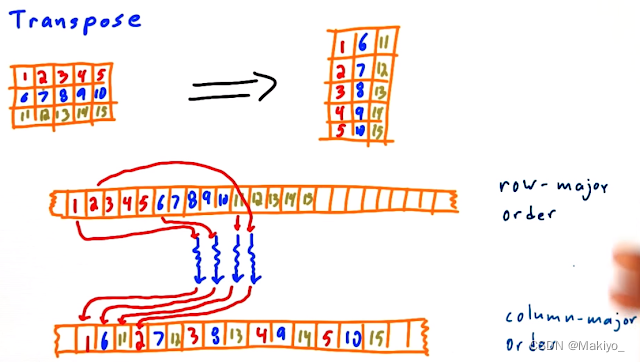
5.转置(Transpose)
-
概念:将矩阵或多维数组的行列进行互换,例如矩阵的转置,2x3转换为3x2
-
输入与输出数据关系:一对一关系。
-
应用:线性代数运算、图像处理中的旋转等。
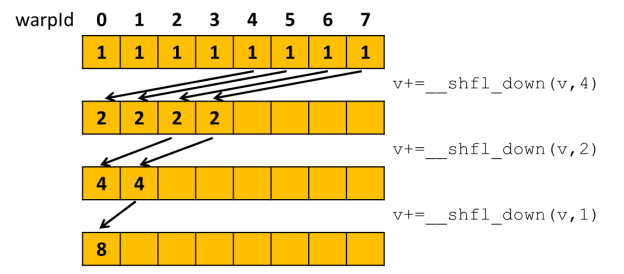
6.压缩(Reduce)
-
概念:将一个输入数据通过归约(下一章具体详解)压缩为较小规模的数据,例如对数组中所有元素求和,类似二分。
-
输入与输出数据关系:多对一关系。
-
应用:统计计算、数据聚合等。
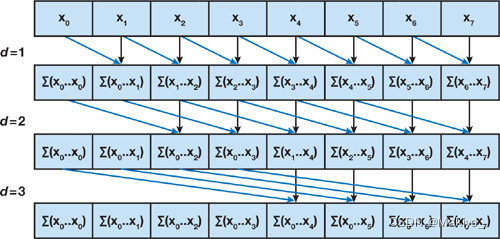
7.重排(Scan)
-
概念:对数据集进行排序或前缀扫描操作,生成前缀和,例如生成前缀和。
-
输入与输出数据关系:多对多关系。
-
应用:排序算法、并行前缀和计算等。
GPU硬件模式
线程块
⭐️Kernel核:Kernel是运行在GPU上的函数,核函数由大量并行线程执行,每个线程在GPU上执行相同的代码,但可以操作不同的数据。可以理解为 C/C++ 中的一个函数 function。
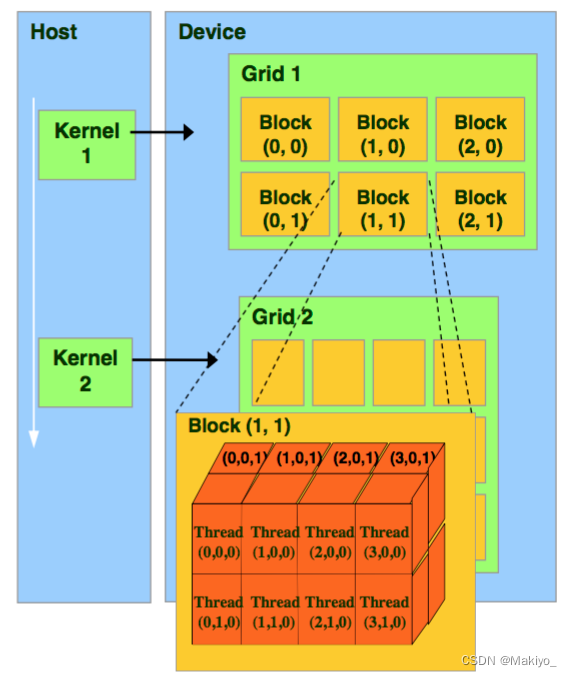
🌟Thread Blocks(Grid): group of thread blocks to solve a function
🌟Thread Block(线程块): a group of threads that cooperate to solve a (sub)problem
GPU
SM(stream multiprocessor):流式多处理器,负责并行执行大量线程。每个SM包含多个CUDA核心(CUDA Cores)、专用的寄存器、共享内存(Shared Memory)和其他支持并行计算的硬件单元。
CUDA核心(CUDA Core):每个SM包含多个CUDA核心,每个核心可以执行浮点运算、整数运算等基本运算。CUDA核心是实际执行计算任务的基本单位。
寄存器(Registers):每个SM包含大量的寄存器,用于存储线程的私有数据。寄存器的访问速度非常快,但数量有限。
本地内存(Local Memory):本地内存是每个线程私有的内存空间。每个线程都有自己的本地内存,其他线程不能直接访问。本地内存通常用于存储线程私有的变量或者无法存放在寄存器中的大型变量。
共享内存(Shared Memory):每个SM包含一块共享内存,供该SM中的所有线程块共享。共享内存的访问速度比全局内存(Global Memory)快,非常适合需要频繁访问的中间数据存储。
线程束(Warp):SM将线程组织成线程束(Warp),每个线程束通常包含32个线程。线程束内的线程同步执行相同的指令,但可以操作不同的数据。
调度和执行:SM采用硬件调度器来管理和调度线程束的执行。当一个线程束因数据依赖或内存访问延迟而阻塞时,调度器可以切换到另一个线程束继续执行,以提高计算资源的利用率。
内存访问和通信:SM内的线程可以通过共享内存进行快速通信。不同SM之间的线程不能直接共享内存,但可以通过全局内存进行通信。
线程块和网格的分配:在执行内核函数时,网格中的线程块被分配到可用的SM上执行。每个SM可以同时处理多个线程块,具体数量取决于线程块的资源需求和SM的资源容量。
GPU: 每个 GPU 有若干个 SM ,最少有 1 个,目前 16 个算大的,每个 SM 并行而独立运行。
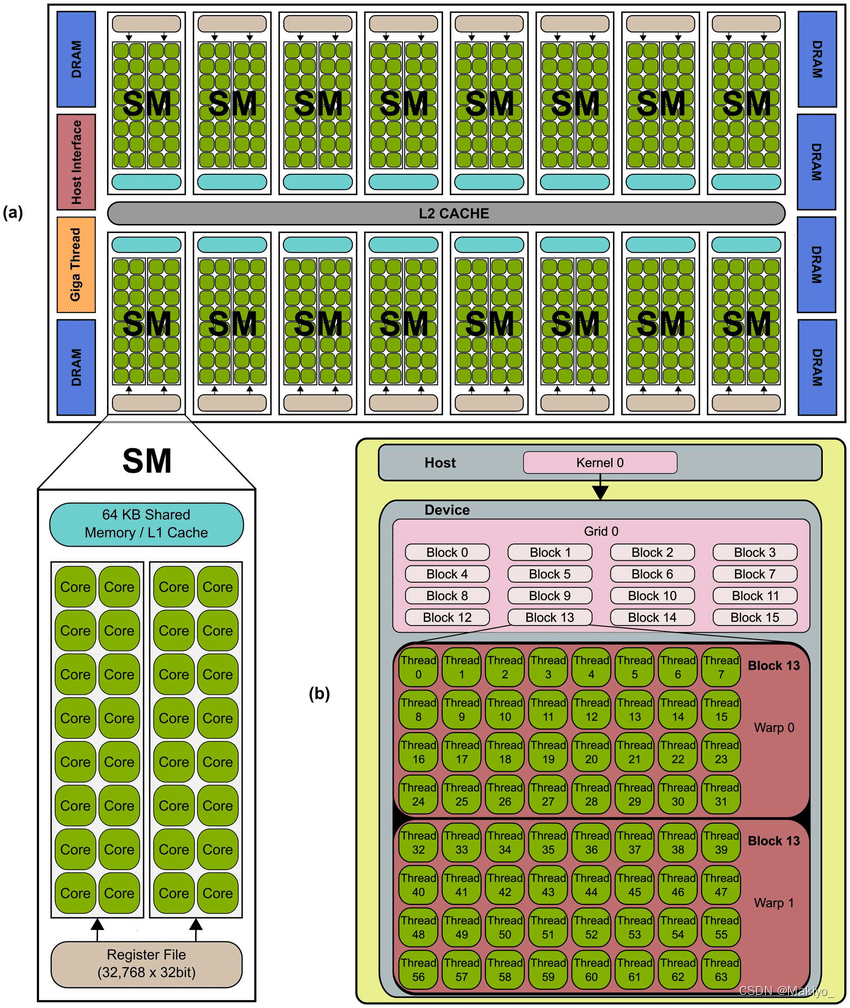
CUDA编程模型
CUDA编程的优点与后果
🌟CUDA最大特点:对线程块将在何处、何时运行不作保证。
优点:
-
硬件真正有效的运行,灵活
-
线程间无需互相等待
-
可扩展性强
后果:
-
对于那个块在那个 SM 上运行无法进行任何假设
-
无法获取块之间的明确通讯( hard to get communications between blocks)
CUDA编程模型的原则
-
所有在同一个线程块上的线程必然会在同一时间运行在同一个 SM 上
-
同一个内核(Kernel)的所有线程块必然会全部完成了后,才会运行下一个内核
内存模型
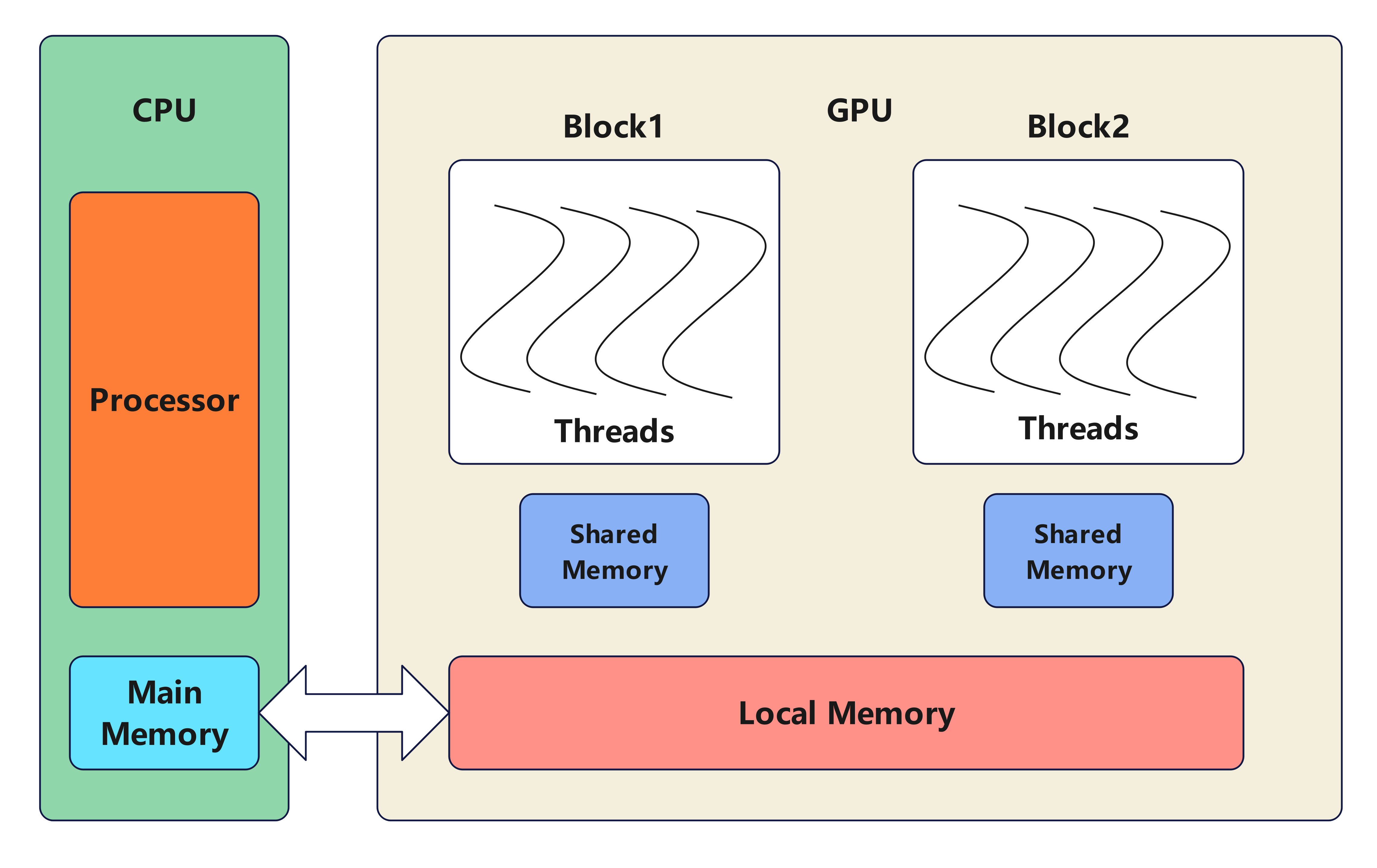
内存速度比较
🌟Local Memory > Shared Memory >> Global Memory > 主机内存Host Memory
同步性synchronisation和屏障barrier
同步性概念:同步性指的是确保多个线程在执行过程中按照预期的顺序和时序进行操作,以避免数据竞争和未定义行为。不同的线程在共享和全局内存中读写数据需要有先后的控制,所以引入了同步性的概念。
屏障概念:屏障是一种同步机制,用于确保线程在某一点上达到同步状态,等待所有参与的线程都到达该点后,才允许继续执行。
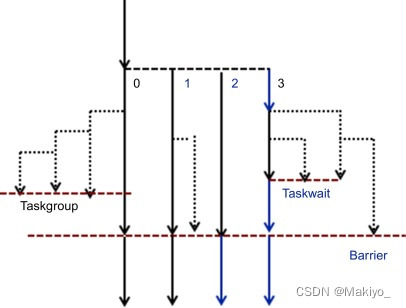
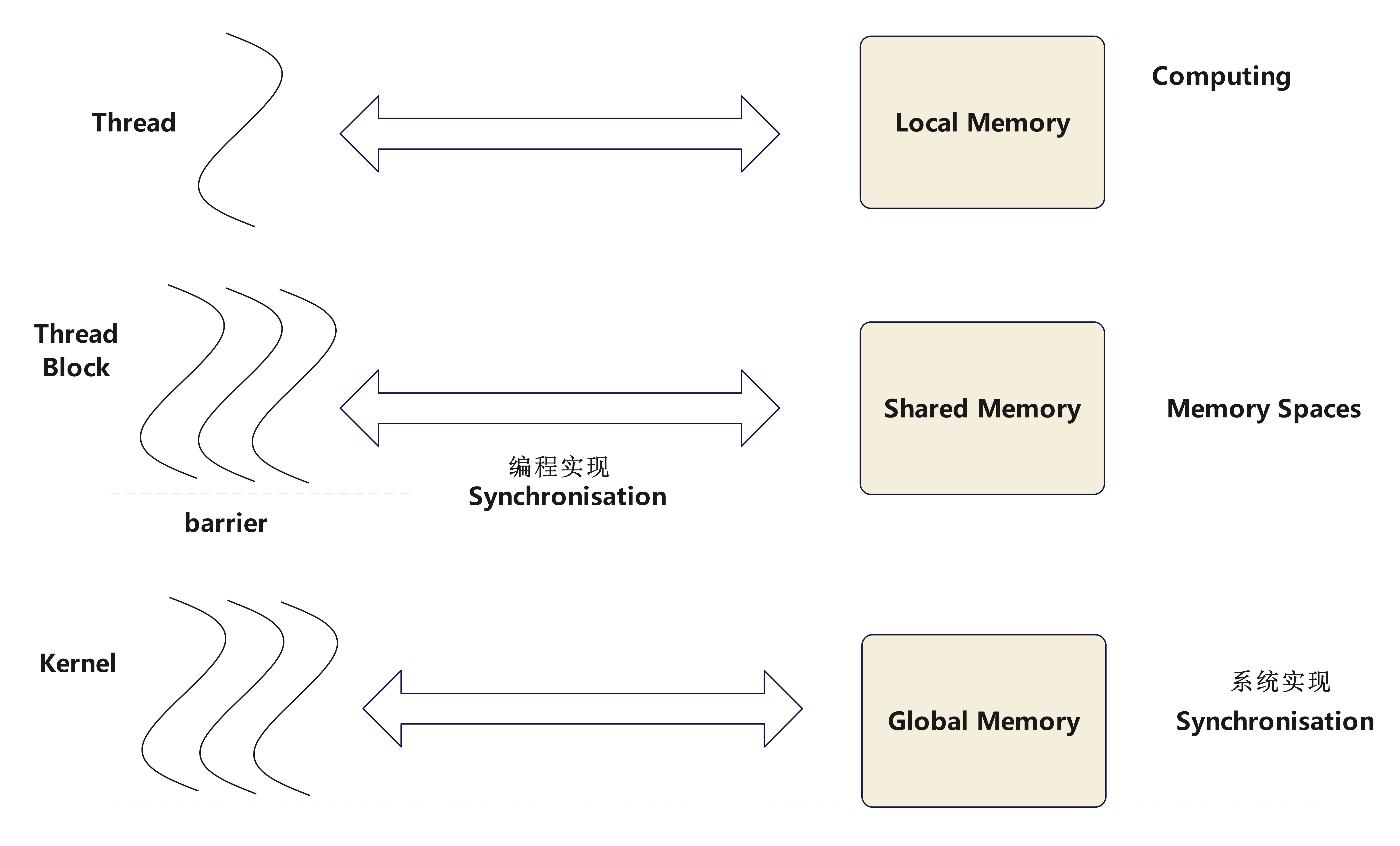
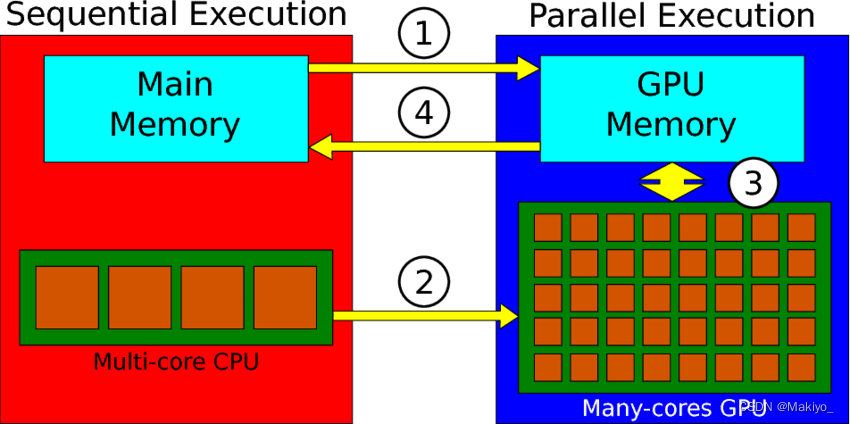
示意图
CUDA 程序中 CPU 是主导地位,负责完成以下的事情:
-
从 CPU 同步数据到 GPU
-
CPU 复制数据给 GPU (cudaMemcpy)
-
给 GPU 分配内存( cudaMalloc)
-
加载 Kernel 到 GPU 上, launch kernel on GPU


















 1750
1750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











