







简介
什么是Spark
Spark特点
1)Speed:相比于MR,官方说,基于内存计算spark要快mr100倍,基于磁盘计算spark要快mr10倍。如图-1所示。
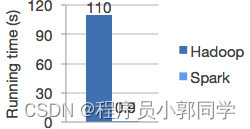
图-1 Spark和Hadoop运行速度比较
2)Ease of Use:Spark提供超过80多个高阶算子函数,来支持对数据集的各种各样的计算,使用的时候,可以使用java、scala、python、R,非常灵活易用。
df = spark.read.json("logs.json")
df.where("age > 21")
.select("name.first")
.show()
3)Generality:通用性如图-2所示。
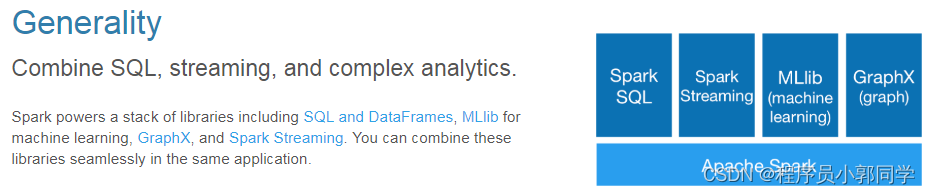
图-2 Spark通用性特点
4)Runs Everywhere:Spark程序可以再多个平台上面运行,如图-3所示。

图-3 Spark到处运行
Spark概述总结
什么是Spark呢?它就是一个集成离线计算,实时计算,SQL查询,机器学习,图计算为一体的通用的计算框架。
何为通用?就是在一个项目中,既可以使用离线计算,也可以使用其他比如,SQL查询,机器学习,图计算等等,而这是Spark最最最强大的优势,没有之一。
而这一切的基础是SparkCore,速度比传统的mr快的原因就是基于内存的计算。
Spark开发过程中,使用到的模型——RDD(Resilient Distributed Dataset,弹性分布式数据集),在编程中起到了非常重要的作用。
RDD概述
何为RDD?其实RDD就是一个不可变的scala的并行集合。
Spark的核心概念就是RDD,指的是一个不可变、可分区、里面元素可并行计算的集合,这个数据的全部或者部分可以缓存在内存中,在多次计算间被重用。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











