







 本文介绍了一个使用Java实现的基于TF-IDF模型的文本排序检索系统。系统支持用户输入一个或多个关键词,返回相关文本及其关键词频度信息。通过数据预处理、TF-IDF计算和关键词匹配算法,系统能够对文本库进行动态装载和处理。在调试过程中解决了数组越界、统计效率、对数计算和浮点数比较等问题。
本文介绍了一个使用Java实现的基于TF-IDF模型的文本排序检索系统。系统支持用户输入一个或多个关键词,返回相关文本及其关键词频度信息。通过数据预处理、TF-IDF计算和关键词匹配算法,系统能够对文本库进行动态装载和处理。在调试过程中解决了数组越界、统计效率、对数计算和浮点数比较等问题。
Java实现基于关键词的文本排序检索系统@TOC
注:个人的学习记录,勿用于其它途径
实验要求:
(1)利用TF-IDF模型,为文本库中的文本创建索引(如倒排索引)。
(2)用户输入的关键词可以是一个或多个。
(3)对于返回的结果文本,需同时显示各检索关键词在结果文本中的出现频度信息。
(4)系统内支持返回结果文本的查看。
(5)拓展要求支持停用词的管理和维护,停用词是指在没有检索价值的单词,如is, am, are, a, an, the,that等。
(6)拓展要求支持文本库的动态装载和处理
设计思路
程序流程图
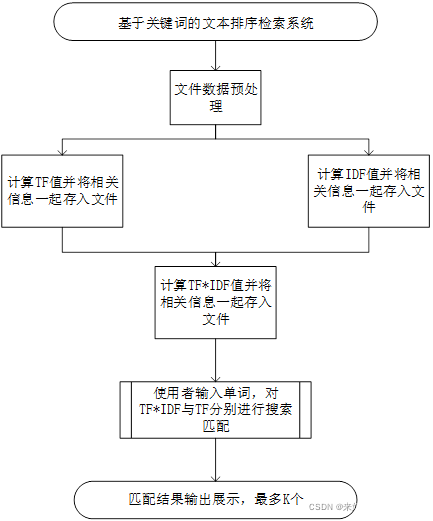
**注:**采用txt文件的形式进行实现,对已给的文本数据集进行处理,得到索引文件,之后直接对索引文件进行查找。(ps:感觉像是对文件中关键词建立了指针)
设计思路
1 数据预处理
得到解压后的文件路径,通过for循环遍历文件数组,通过strAll = getTemplateContent(file);函数将文件的内容以字符串的形式给出并通过toUpperCase()函数将单词全部转化为大写字母,然后对strAll进行单词的切割。首先将各种无用的分隔符用“-”代替如:str = str.replaceAll("\r\n","-");str = str.replaceAll("\|","-")并将多个“-”同样替代为单个的“-”。然后通过对“-”的切割,将文件切割为String[],每一个元素均为有意义的字符。之后便可通过HashMap<String,Integer>进行单词的频度信息进行TF文件的写入及后续步骤的执行。
2 TF-IDF模型
基于TF-IDF(term frequency-inverted document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。简单来说,TF即统计单词在本文档的词频;IDF即体现出现某单词的文档数和总文档数的关系,出现的文档越多表示该词的普遍重要程度不大。
故可将文件的TF值与IDF分别计算出来后再合并得出TF-IDF值。TF的计算方法:
〖TF〗_i=n_i/all
式中分子为单词i在当前文件的出现次数,分母是当前文件的单词数。IDF的计算方法:
〖IDF〗_i=log D_i/allD
式中对数函数的分式中分子为单词i在多少个文件中被包含,分母为所有的文件数即1000。
最后将单词i的TF值与IDF值相乘得到最终结果并写入新的文件。
3 关键词匹配算法
根据用户输入的字符串按“–”进行切割并存为String[],按顺序对TF与TFIDF文件进行遍历,若word.equals(strs1[0])即字符串相等则返回相关的文本信息。由于在处理数据中发现有的单词TF值较高,但是IDF值为很小,故我采用的是同时返回K个TF最大和TFIDF最大的文件,我认为这样更为合理。若用户输入停用词则输出提示信息并退出程序;若用户输入的单词不足K个文件进行返回,则只返回K个文件。
代码如下
**注:**代码不是放一起的,先对文本进行处理,计算得到索引文件,然后才是查找与返回结果显示。
1.文件数据预处理
package testCode;
import java.io.File;
import java.io.FileInputStream;
import java.nio.charset.StandardCharsets;
public class getFileName {
static int count =0;
public static void main(String[] args) {
String path = "C:\\Users\\11422\\Desktop\\算法设计\\题目B3的数据集";
File f = new File(path);
getFileName.getFile(f);
System.out.println(count);
}
public static void getFile(File file){
if(file != null){
File[] files = file.listFiles();
String strAll="";
if(files != null){
for(int i=0;i<files.length;i++){
getFile(files[i]);
}
}else{
//输出文件路径System.out.println(file);
try {
//将文件内容取出到字符串
strAll = getTemplateContent(file);
//计数取出多少文件
count++;
testCode test = new testCode();
test.SplitFile(strAll);
//输出字符串长度及内容
//System.out.println(strAll.length()+"--"+strAll);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
//获取文件内容到字符串
private static String getTemplateContent(File file) throws Exception{
if(!file.exists()){
return null;
}
FileInputStream inputStream = new FileInputStream(file);
int length = inputStream.available();
byte bytes[] = new byte[length];
inputStream.read(bytes);
inputStream.close();
String str =new String(bytes, StandardCharsets.UTF_8);
return str ;
}
}
2.计算TF值并存入文件
package testCode;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.HashMap;
public class testCode {
public static void SplitFile(String str){
//为所有单词建立索引文件
File SimplifiedData =
new File("C:\\Users\\11422\\Desktop\\算法设计\\SimplifiedData.txt");
FileWriter fw = null;
BufferedWriter bw = null;
try {
fw =new FileWriter(SimplifiedData,true);
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
bw =new BufferedWriter(fw);
//将字符串所有字母大写便于后续处理
str = str.toUpperCase();
//将各种字符转换为统一一个字符,便于切割且不会留空
str = str.replaceAll("\r\n","-");
str = str.replaceAll(" ","-");
str = str.replaceAll("$","-");
str = str.replaceAll("\\(","-");
str = str.replaceAll("\\[","-");
str = str.replaceAll("\\]","-");
str = str.replaceAll("\\)","-");
str = str.replaceAll("\\'","-");
str = str.replaceAll("\\!","-");
str = str.replaceAll(":","-");
str = str.replaceAll(";","-");
str = str.replaceAll("\\.","-");
str = str.replaceAll("\\?","-");
str = str.replaceAll("\\|","-");
str = str.replaceAll(",","-");
str = str.replaceAll("\\'","-");
str = str.replaceAll("--------","-");
str = str.replaceAll("-------","-");
str = str.replaceAll("------","-");
str = str.replaceAll("-----","-");
str = str.replaceAll("----","-");
str = str.replaceAll("---" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









