






The time for each iteration can be divided into the following parts: 1) Pipeline warm-up phase2) Pipeline steady phase f3) Pipeline cooldown phase4) Optimizer communication and computation
举个例子描述一下这个过程
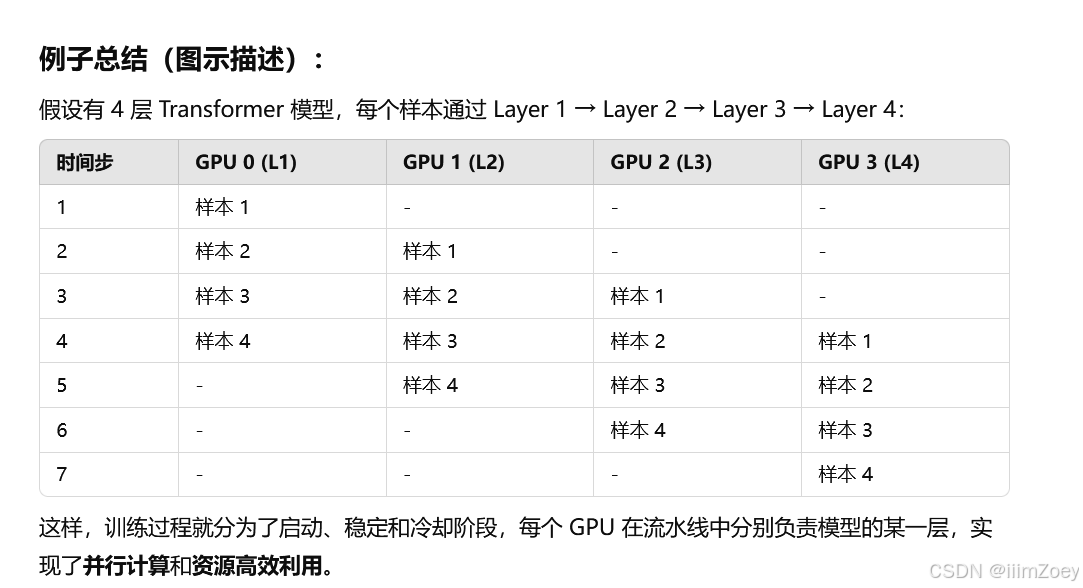
在流水线启动阶段,由于模型被分成多个阶段(如 Transformer 的多个层分布在不同 GPU 上),流水线逐步填充数据。
- 假设:模型有 4 层,每一层分布在一张 GPU 上(GPU 0、GPU 1、GPU 2 和 GPU 3),一个 mini-batch 有 4 个样本。
- 开始时:每个 GPU 只能开始计算一个样本,因为后续数据尚未到达。
NVLink 是 NVIDIA 提供的一种高速互连技术,主要用于连接多 GPU 系统,它提供比传统 PCIe 更高的带宽和更低的延迟,尤其适用于大规模深度学习训练任务。在跨机训练中,如果将网络通信改为更低带宽的传统网络,如以太网或 InfiniBand,训练的吞吐量和速度可能会大幅下降,而使用 NVLink 能够显著提高通信效率,减少性能瓶颈。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









