







 本文详细介绍了K-means聚类算法的实验步骤,包括从导入数据到使用K-means进行聚类,以及如何用sklearn库实现算法。实验数据可以清晰地划分为4个类别,经过几次迭代后能稳定找到聚类中心。此外,文章还提供了相关资源链接和画图函数的参考。
本文详细介绍了K-means聚类算法的实验步骤,包括从导入数据到使用K-means进行聚类,以及如何用sklearn库实现算法。实验数据可以清晰地划分为4个类别,经过几次迭代后能稳定找到聚类中心。此外,文章还提供了相关资源链接和画图函数的参考。
一、实验内容与步骤
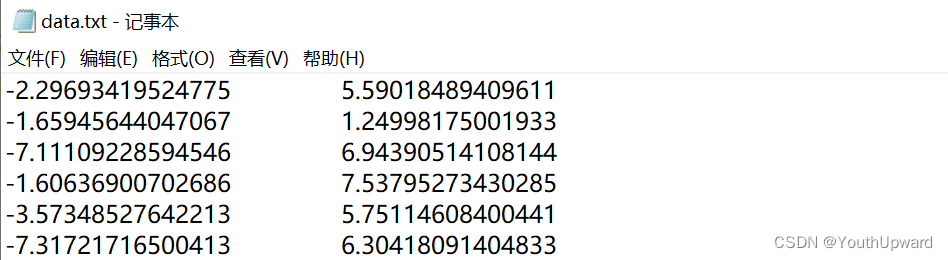
源数据(80行)
题目1
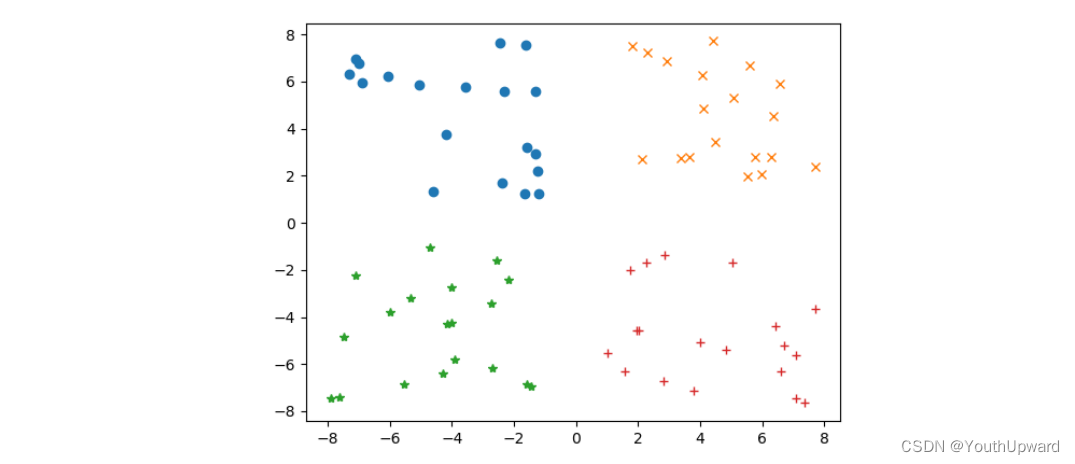
已知训练数据集data.txt可以划分成4个不同的类别(如下图所示),定义k=4,随机初始化4个不同的聚类中心,通过计算每个样本点与聚类中心之间的距离,将样本点划分成不同的类别中。
代码
1.导入训练数据集data.txt
def load_data(file_path):
'''导入数据
input: file_path(string):文件的存储位置
output: data(mat):数据
'''
f = open(file_path)
data = []
for line in f.readlines():
row = [] # 记录每一行
lines = line.strip().split("\t")
for x in lines:
row.append(float(x)) # 将文本中的特征转换成浮点数
data.append(row)
f.close()
return np.mat(data)
2.随机初始化k个聚类中心
def randCent(data, k):
'''随机初始化聚类中心
input: data(mat):训练数据
k(int):类别个数
output: centroids(mat):聚类中心
'''
n = np.shape(data)[1] # 属性的个数
centroids = np.mat(np.zeros((k, n))) # 初始化k个聚类中心
for j in range(n): # 初始化聚类中心每一维的坐标
minJ = np.min(data[:, j])
rangeJ = np.max(data[:, j]) - minJ
# 在最大值和最小值之间随机初始化
centroids[:, j] = minJ * np.mat(np.ones((k , 1))) \
+ np.random.rand(k, 1) * rangeJ
return centroids
3.利用K-means进行聚类算法(为每个个体分配聚类中心,移动聚类中心,迭代)
#利用K-Means进行聚类算法(为每个个体分配聚类中心,移动聚类中心,迭代)
def kmeans(data,k,centroids):
'''
input:
data(mat): 训练数据
k(int): 类别个数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









