







 本文介绍了使用sklearn库的KNN算法对鸢尾花数据集进行分类的步骤,包括前期准备、模型建立、最优参数寻找和模型评估。通过交叉验证确定k值为7时模型效果最佳,测试集错误率为0,同时展示了混淆矩阵和各种评价指标。
本文介绍了使用sklearn库的KNN算法对鸢尾花数据集进行分类的步骤,包括前期准备、模型建立、最优参数寻找和模型评估。通过交叉验证确定k值为7时模型效果最佳,测试集错误率为0,同时展示了混淆矩阵和各种评价指标。
**
机器学习knn算法学习笔记使用sklearn库 ,莺尾花实例。
具体knn算法是怎样的我这里就不再详细论述。在这里我注意总结我使用knn算法进行一个分类的分析
**
分析过程
1.前期准备
引入相关的库,model_selection这个模块采用我这种写法,不然就用不了
import numpy as np
from sklearn import model_selection #将训练集和测试集分开的模块
from sklearn.neighbors import KNeighborsClassifier # K-近邻算法模块
import matplotlib.pyplot as plt
import pandas as pd
引入数据看看数据是怎样的
data = pd.read_csv(r'C:\Users\lenovo\Desktop\毕业论文文献2\iris.csv')
data.head()
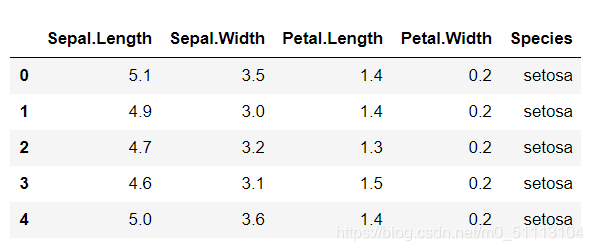
如图所示,一个数据有四个特征值,为了发方面后续分析,我们将各数据的类别重新命名。
###将种类名称替换成对应的数字, 1:setosa, 2:versicolor, 3: virginica. 这一步在这个分类预测中没有必要, 但可以用在回归中。
data['encode'] = data['Species'].map(lambda x :1 if x =='setosa' else (2 if x =='versicolor' else 3))
data.info()

一共有150个数据集,没存在空值的情况。
#设置变量x 与变量y
x = np.array(data.iloc[:,:4])
y = np.array(data.encode)
#将x,y分别划分为训练集与测试集
train_x,test_x,train_y 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1988
1988

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









