






一 .基础语法
1.基本操作
-
dir----打开文件命令符
-
cls ---清除当前内容
-
cd ---切换磁盘 md-移动文件
-
rd-删除文件
-
cd/ 返回根目录
-
stateinfo-文件信息
2.相关变量的使用
-
变量可随时修改 记录的是最新值
-
“数字 字母 下划线 ,数字不开头"
-
”空格出语法错误“
-
-
字符串使用————————单引号or双引号
-
name.title()-----首字母大写
-
name.upper()----全部大写
-
name.lower()---全部小写
-
-
f"{name} {name2}"-----合并字符串
-
生成空白---制表符\t 换行符\n----要加引号
-
删除空白---- 暂时性 再次引用时回复原态
-
name.rstrip()-----尾部暂时删除空白 "
-
name. lstrip()----头部暂时删除空白
-
name.strip()----两端暂时删除空白
-
-
-
语法错误
-
单引号引用时+撇号====语法错误 syntaxError
-
-
数 四则运算(+ — * /) **乘方运算

-
整数 1_000_000=1000000
-
浮点数
3. 列表 [XXX]表示
-
列表索引
-
访问---names[0]--(访问一号元素)
-
访问---names[-1]--(访问最后元素)
-
-
修改-增添-删除
-
修改---定义列表,索引修改//del按索引删除
bicycle = ['2-8大杠', '飞鸽', '风凰'] print(bicycle[2].title()) metrobike = ['dajiang', 'feige', 'apaqi', 'CAIHONG'] metrobike.insert(0,'feiji') del metrobike[0] print(metrobike) -
增加元素--
在列表尾 增加元素 names.append(~~~) 在列表中 增加元素 names.insert(x.'~~~') -
删除元素--
car=['byd','xiaomi','changcheng','bmw','w','roulsa'] my_car = car.pop(0) car.pop() expensive_car = car[-1] car.remove(expensive_car) print(f"\n {expensive_car.title()} is too expensive for me") print(car) print(my_car)del 语句 <!删除后无法访问> 无返回值 del names[x] pop 语句 <!末尾弹出> 返回删除元素值 names.pop() pop 语句删除任意位置的元素 返回删除元素值 names.pop(x) remove 根据值删除元素 返回删除元素值 names.remove(james)
-
-
组织列表 --调整顺序 <!注意差一现象>
-
永久排序---sort() names.sort()||names.sort(reverse=True)---反序排列
-
临时排序---sorted(names)
-
逆打印序列元素---reverse names.reverse() 永久性逆置
-
确定列表长度----len(names)
band=['taobao','jingdong','dewu','shihuo','xianyu','jiuwufen','zhaunzhuan'] print(band[-1].upper()) band.sort() print(band) band.reverse() print(band) print(len(band))
-
-
操作列表
-
遍历列表---fot name in names:
-
代码行的缩进----判断是否出错
忘记缩进 indetation error 忘记缩进额外的代码行 逻辑错误 不必要的缩进 unexpected indent 循环后缩进不必要的 逻辑错误 遗落for循环的冒号 syntaxterror -
创建数值列表
-
使用range()函数 差一现象,最后一个数打印不出来
for value in range(x,y)
for value in range(x,y,z)
for value in range(5)
-
使用range()函数创建数字列表
-
列表解析 squares=[value**2 for value in range(1,10)]
for values in range(1,11,5): print(values) numbers = [values**2 for values in range(1,5)] print(numbers) for num in range(5): print(num)
-
-
切片 print(names[a:b]) 索引定位
-
切片遍历 for name in names[:]:
-
复制列表first-name=second-name[:]
bands='huawei','xiaomi','sanxing','apple','oppo','vivo','honner','hongmi','nuojiya'] print("here are my favorite band:") for band in bands[0:3]: print(band.title())
-
-
-
元组操作-----元素不可修改的列表
-
元组的元素在程序的整个生命周期都不变
-
names=(a,b)
-
定义
-
修改 不可修改但可赋元素值
-
访问
bands=('bigband','exo','tfboy') for band in bands: print(band.title())
-
-
4 条件语句的使用
-
检查不等情况
bands=['bigband','exo','tfboy','rose1','blackpinck','ssw'] my_love_band = 'blackppinck' if my_love_band not in bands: print("error!") -
检查相等
num=100 if num>=0: if num<20: prince=10 elif num<50: prince=20 elif num<100: prince=30 else: prince=100 elif num<0: prince =0 print(prince) -
多条件检出 and||or 语句
-
元素是否在列表中 in||not in语句
-
if语句
if语句 if-else语句 if-elif-else语句 if-elif-elif-elif-elif-else语句
5.字典 键与值(类似于结构体)
aline_0={'color':'green','point':1,'x_value':20,'y_values':40}
print(aline_0)
aline_0['height']=200
aline_0['weight']=300
print(aline_0)
del aline_0['point']
print(aline_0)
aline_0['point']=20
print(aline_0)
my_aline=aline_0.get('point','NULL')
print(my_aline)-
格式
aline={键值1:属性1,键值2,属性2} aline={"color":"blue","point":5} -
使用字典
-
访问字典中的元素值
-
添加键值对
aline={"color":"blue","point":5} aline["height"]=20 aline["weight"]=30 -
创建空字典
aline={} aline["color"]="red" aline["point"]=3 -
修改字典中的元素值(类似于添加)
aline={"color":"red","x_poision":0,"y_poision":1,"speed":"last"} if aline["speed"]=="fast": x_poision=1 elif aline["speed"]=="mindmm": x_poision=4 else if aline["speed"]=="last": x_poision=6 aline["y_poision"]==aline["x_poision"]+aline["x_poision"] -
删除键值对---永久性del
alines={'color':'blue','point':2,'poision':'mindmun'} del aline['point'] -
有类似对象对象组成的字典
names={ 'first':'david', 'second':'bob', 'three':'ton', 'four':'jerry', } name=names['four'].title() print(f"my name is {name}") -
使用get()来访问值---不存在时返回默认值
alines={'name':'david','point':'5'} aline=alines.get('color','none') print(aline)
-
-
遍历字典<!---注意的单复数形式--->
-
遍历所有的键值对---使用.items()方法
points={'david':2,'bob':3,'yon':2,'bou':4,'hi':6} for name,point in points.items(): print(f"{name} his point is {point}") -
遍历字典中的所有键---显示使用.keys()方法
points={'david':2,'bob':3,'yon':2,'bou':4,'hi':6} for name in points.keys(): print(f"{name} his point is {points[name]}") -
遍历字典中的所有值---显示使用.values()方法
points={'david':2,'bob':3,'yon':2,'bou':4,'hi':6} for point in points.values(): print(point) -
按照特定的顺序遍历字典中的所有键
points={'david':2,'bob':3,'yon':2,'bou':4,'hi':6} for name in sorted(points.keys())://临时排序 print(f"{name} his point is {points[name]}") print(points) -
便利字典中的所有值---使用set()剔除重复项
points={'david':2,'bob':3,'yon':2,'bou':4,'hi':6} for point in set(points.values()): print(f"{name} his point is point")
-
-
嵌套
-
字典列表
aliens=[] for aline in range(20): alien={'coloe':'blue','point':30,'size':'big'} alines.append(aline) for aline in alines[-3]: print(aline) prinf(f"共有{len(alines)}个外星人) -
字典中存储列表
names={ 'janes':[2,34,34,34,45,], 'davis':[2,3,4,6], } for name,points in names.items(): print(f"\n{name}has get thr point:") for point in points: print(f"\t{point}") -
在字典中存储字典
users={ 'user1':{ 'firstname':'liu', 'lastname':'bin', 'location':'shaxni' }, 'user2':{ 'firstname':'liu', 'lastname':'liu', 'location':'xian' }, } for username,info in usernames.items(): print(f"\nUsername is{username}") fullname=f"{info['firstname']}{info['lastname']}" location=info['location'] print(f"\t{fullname.title()}") print(f"\t{location.title()}")
-
字典:{}定义,用:分开 aline={'color':'blue','point':2}
集合:{}定义,集合不以特定顺序存储元素aline={'color','point','blue'}
列表:[]定义aline=['aa','aa','ccc']
6.交互性while循环的使用
-
输入
-
input 原理---提示用户输入信息
<!---创建多行问文本(+=连接附加信息至上一字符串---> names=input("Please inout your name ") nmaes+="\what your name!"-
int()---获取数值输入
-
求模运算符---%
-
-
-
while循环
-
current_number=1
while curent_number<=10: print(cuernt_number) curent_number+=1 -
使用标志
flag=True while flag: message=input(prompt) if message=="quit": flag=False else: print(message) -
使用braek---退出遍历或者while循环
while True: message=input(prompt) if message=="quit": break else: print(f"I love this city{message.titlie()}") -
使用continue---忽略余下的代码返回循环头部
curent_number=0 while curent_number<=100: curent_number+=3 if curent_number%2==0: continue print(curent_number)p -
避免无限循环---while进行条件测试
-
-
while循环实例
-
在列表之间移动元素
从未验证的列表中验证通过后加加入到已验证的用户列表中
-
删除为特定值的所有元素列表
while循环加remove()方法
-
使用用户输入来填充字典
anwsers={} anwser_active=True while anwser_active: namee=input("\n 请输入你的名字:") age=input("\n你的年龄是:") anwsers[namee]=age repat=input("还有人要补充吗?") if repat=='no': anwser_active=False print("\n----调查结果是-----") for namee,age in anwsers.items(): print(f"{namee}的年龄是{age}")
-
7.函数的基本知识
-
函数的定义
def get_name(username):----username为形参||函数完成工作所需的信息 """显示简单的问候语""" print("hellow Person") get_name(”james")----james为实参||函数调用时传递给函数的信息 -
参数传递
-
使用位置实参---实参与形参是顺序一致---位置参数(可能产生逻辑错误)
def descrinb_animals(name,chareacter): """"显示宠物信息""" print(f"The animals's name is {name}") print(f"It's chareacter is{chareacter.title()}") descrinb_animals('xainhu','聪明') descrinb_animals('xiaoliu','笨拙') -
使用关键字实参---每个变量由变量名和值组成(精准对应)
def descrinb_animals(name,chareacter): """"显示宠物信息""" print(f"The animals's name is {name}") print(f"It's chareacter is{chareacter.title()}") descrinb_animals(name='xainhu',chareacter='聪明') descrinb_animals(name='xiaoliu',chareacter='笨拙') -
使用形参使用默认值---使用时先列出没有默认值得形参而后再列出有默认值的
def descrinb_animals(name,chareacter='聪明'): """"显示宠物信息""" print(f"The animals's name is {name}") print(f"It's chareacter is{chareacter.title()}") descrinb_animals(name='xainhu') descrinb_animals(name='xiaoliu') -
等效的函数调用--逻辑一致
-
-
返回值---使用return返回函数代码行,大部分工作由函数完成
-
返回简单值
def get_fullnmae(name1,name2): """"返回整个名字""" fullname=f"{name1} {name2}" return fullname.title() nickname=get_fullnmae('liu','bin') print(nickname) -
让实参变成可选的----形参变成默认值’空字符串‘
def get_fullname(name1, name2, name3=''): """"返回完整的名字""" if name3: fullname = f"{name1} {name3} {name2}" else: fullname = f"{name1}{name2}" return fullname fullname=get_fullname('liu', 'master', 'bin') print(fullname) fullname=get_fullname('xiao', 'liu') print(fullname) -
返回字典
def bulid_person(firstname,lastname,age): """储存个人信息""" person={'first':firstname,'last':lastname} if age: person['age']=age return person fullname=bulid_person('liu','bin',age=22) print(fullname) -
结合使用函数和whilie---谨慎使用---break语句
def get_fullname(name1,name2): """循环输入姓名""" fullname=f"{name1}{name2}" return fullname.title() while True: print("\nPlease input your f_name") print("Input the'q'is mean that exit") f_name =input("Please input your f_name") if f_name == 'q': break print("\nPlease input your l_name") print("Input the'q'is mean that exit") l_name=input("Please input your l_name") if l_name=='q': break name=get_fullname(f_name,l_name) print(f"\nHellow,{name}!")
-
-
传递列表---列表作为是实参调用时传递给函数
-
传递列表
def greet_name(names): """"问候列表中的每个人""" for name in names: message=f"Hellow,{name.title()}" print(message) usernames=['liubin','xiailiu','xialo'] greet_name(usernames) -
函数中修改列表---永久性写入---函数更易扩展和补充
-
禁止函数修改列表
-
方法:使用副本:function_name(listname[:])
-
缺点:花费时间和内存创建副本
-
-
传递任意数量的参数---元组来存储实参
def names(*userames): """"函数中包括以下名字""" print("\nThe list has following argument") for userame in userames: print(f"-{userame}") names('aa') names('aa','bb','cc','dd') -
结合位置参数使用任意数量的参数----”多者形为后"---args(任意数量的形参)
-
使用任意数量的关键字实参---information设定空字典---kwargs用于收集任意数量的关键字实参
def describe_information(first,last,**infomation): infomation['firstname']=first infomation['lastname']=last return infomation usernames=describe_information('liu','bin',location='china',major='computer') print(usernames)
-
-
将函数存储在模块中---可以将代码块与主函数分离。函数存储与模块的独立文件,再将模块导入到主程序中---方便程序员共享这些文件而不是整个程序
-
导入整个模块
#模块make.py,函数make_pizza() def make_pizza(size,*toppings): print(f"\nMaking a {size} pizza must have the follwing toppings:") for topping in toppings: print(f"-{topping}") import make make.make_pizza(16,'面粉') make.make_pizza(12,'淀粉','麦芽糖','纯净水') -
导入特定的模块---from 模块 import 函数1,函数2,函数3
from make import make_pizza make.make_pizza(11,'蔗糖') make.make_pizza(13,'苏打水','饴糖') -
使用as给函数指定别名---别名类似于外号---from 模块 import 函数 as 别名
from make import make_pizza as mp mp(11,'蔗糖') mp(13,'苏打水','饴糖') -
使用as给模块指定别名---import 模块 as别名
import make as m m.make_pizza(19,'mushroom','water') m.make_pizza(10,'paper','oil') -
导入函数中的所有模块---from 模块 import *
from make import * make.make_pizza(11,'蔗糖') make.make_pizza(13,'苏打水','饴糖')
-
8.类
-
-self指定实例自身的引用
class Dog: """"一次模拟小狗的活动""" def __init__(self,name,age): """"初始化name和age""" self.name=name self.age=age def sit(self): """"模拟小狗坐下""" print(f"小狗a age{self.age} {self.name}is now sitting!") def rollback(self): """"模拟小狗打滚""" print(f"小狗a age{self.age} {self.name}is now rollback!") -
根据类创建实例
class Dog: """"一次模拟小狗的活动""" def __init__(self,name,age): """"初始化name和age""" self.name=name self.age=age def sit(self): """"模拟小狗坐下""" print(f"小狗a age{self.age} {self.name}is now sitting!") def rollback(self): """"模拟小狗打滚""" print(f"小狗a age{self.age} {self.name}is now rollback!") my_dog = Dog('james',12) print(f"It's name is {my_dog.name}") print(f"It's age is {my_dog.age}")-
访问属性---实例化
my_dog = Dog('james',12) print(f"It's name is {my_dog.name}") print(f"It's age is {my_dog.age}") my_dog.sit() my_dog.rollback() -
创建多个实例
my_dog=Dog('bob',99) your_dog=Dog('tom',19) print(f"\nIt has a dog{my_dog.name}and it's age is{my_dog.age}") my_dog.sit() print(f"\nIt has a dog{your_dog.name}and it's age is{your_dog.age}") your_dog.rollback()
-
-
实用类和实例
class Car: """"创建汽车的一次简单实例""" def __init__(self,make,modul,year): self.make=make self.module=modul self.year=year self.meter=0 def information(self): """"返回整洁的信息""" longname=f"{self.make} {self.year} {self.module}" return longname.title() def get_meter(self): """"打印该汽车所拥有的里程数""" print(f"This car has run {self.meter} mile on taht road!!!") my_car=Car('宝马','三系','2023''9900') print(my_car.information()) my_car.get_meter()-
修改属性中的值
-
直接修改----通过实例直接修改
-
通过方法进行修改---定义修改的方法
class Dog: ---snip--- def updata_meter(self,milige): """"更改里程数""" if milige>=self.meter: self.meter=milige else: print("您的里程过低难以更新") my_car.updata_meter(10) my_car.get_meter() -
通过方法对属性的值进行递增
class Dog: ---snip--- def increatmile(self,miles): self.meter+=miles my_car.increatmile(100) my_car.get_meter()
-
-
-
继承---类与类之间
class Eletoriccar(Car): """"定义子类电动车""" def __int__(self,make,modul,yaer): """"初始化父类属性""" super().__init__(self,make,modul,yaer) tesla=Eletoriccar('电动车','s',2024) msg=tesla.information() print(msg)-
重写父类的方法---对于子类毫无意义,对于父类些许意义
class Eletoriccar(Car): ---snip--- def fill_oil_tanks(self): print("\n对于电动车子类毫无意义") -
将实例用作属性
-
给子类定义属性和方法
-
模拟实物:
-
-
导入类---允许类封装在模块中,
-
导入单个类
-
在同一模块存储多个类
-
多个类导入同一模块
-
-
从同一模块导入多个类
from car inport Car,Electtycar
-
导入整个模块
import car
-
导入模块整的所有类---最好使用import模块,类名
from car import *
-
在同一模块导入另一个模块
-
9.文件与异常
-
从文件中读取数据
-
读取整个文件----read()方法到达文件末尾时返回一个空字符串,该字符串显示后多空行
with open('digital.txt') as file_object: content=file_object.read() print(content) -
文件路径 ---绝对路径不在同一文件夹下-------相对路径—再同一目录中
-
windows系统中路径使用反斜杠(\)-----可能会出现转义错误=使用\解决
-
py中使用(斜杠/)表示路径
with open('1/digital.txt') as file_object: file_path='E:\\idea\\pythonProject\\.idea\\1\\digital.txt'
-
-
逐行读取---出现空白行,每行末尾出现一个换行符+print()函数的换行符
filename='digital.txt' with open(filename) as file_object: for line in file_object: print(line) -
创建一个包含各行的文件---可在with外使用文本文件的各行数据
filename='digital.txt' with open(filename) as file_object: lines=file_object.readline() for line in lines: print(line.rstrip()) -
使用文件的内容---读取文件时独处的数据是字符型
filename='digital.txt' with open(filename) as file_object: lines=file_object.readline() pi_string='' for line in lines: pi_string+=line print(pi_string)-----print(pi_string[:6])---显示部分信息 print(len(pi_string))
-
-
写入文件
-
写入空文件---只能写入字符串
-
w---写入模式---加入信息
-
r---读取模式---
-
a---附加模式---写入的信息附加到末尾
-
r+---读写模式
-
写入多行---使用转义字符
-
附加到文件
filename='digital.txt' with open(filename,'w') as file_object: file_object.write("I love you") file_object.write(str(1235)) filename='digital.txt' with open(filename,'a') as file_object: file_object.write("I will catch your path\n") file_object.write("you wait me and I deeply love you\n")
-
-
异常---通过try-expect解决异常
-
除0异常---zerodivisionerror
print("请输入整数已备除法运算") print("输入'q'表示结束") while True: firse_number=input("\n请输入除数") if firse_number=='q': print("结束了") break second_number=input("请输入被除数") if second_number=='q': print('结束了') break answer=int(firse_number)/int(second_number) print(answer) -
else代码--else代码块存储try快要成功才执行的代码
print("请输入整数已备除法运算") print("输入'q'表示结束") while True: firse_number=input("\n请输入除数") if firse_number=='q': print("结束了") break second_number=input("请输入被除数") if second_number=='q': print('结束了') break try: answer=int(firse_number)/int(second_number) except ZeroDivisionError : print("0除错误") else: print(answer) -
处理FileNotFoundError 错误
fliename="diigital.txt" try: with open(fliename,encoding='utf-8')as f: contnts = f.read() except FileNotFoundError: print("对不起,您查找的文件不存在") else: print(contnts) -
分析文本---方法split()---以空格为分隔符将字符串拆分成多个部分存储与列表中
fliename="alice.txt" try: with open(fliename,encoding='utf-8')as f: contnts = f.read() except FileNotFoundError: print("对不起,您查找的文件不存在") else: words=contnts.split() number=len(words) print(f"The {fliename} have a {number}word") -
使用多个文件---使用函数
def count_word(flienam): """描述文档含有有多少单词书""" fliename="alice.txt" try: with open(fliename,encoding='utf-8')as f: contnts = f.read() except FileNotFoundError: print("对不起,您查找的文件不存在") else: words=contnts.split() number=len(words) print(f"The {fliename} have a {number}word") flienames=['alce.txt','siddhartha.txt','little_women.txt'] for fliename in flienames: count_word(fliename) -
静默失败---告诉代码块什么不要做
def count_word(flienam): """描述文档含有有多少单词书""" fliename="alice.txt" try: with open(fliename,encoding='utf-8')as f: contnts = f.read() except FileNotFoundError: passs else: words=contnts.split() number=len(words) print(f"The {fliename} have a {number}word") flienames=['alce.txt','siddhartha.txt','little_women.txt'] for fliename in flienames: count_word(fliename)
-
-
-
存储数据
-
使用json.dump() 以及json.load()---程序之间共享数据
import json numbers=['12','123','234','2344'] filename='number.json' with open(filename,'w')as f: json.dump(numbers,f) import json numbers=['12','123','234','2344'] filename='number.json' with open(filename)as f: numbers=json.load(f) print(numbers) -
保护和读取用户产生的数据
-
10.测试函数
-
测试函数
-
单元测试与测试用例
import unittest from name_function import get_formatted_name class NameTestCase(unittest.TestCase): """"测试name_function中的unittest.TestCase""" def test_name_firstandlast(self): #测试函数的get_formatted_name一方面 """"能正确处理象json这样的数据吗""" full_name=get_formatted_name('liu','bin') self.assertEqual(full_name,'Liu Bin') #使用断言方法 核实结果是否与期望一致 if __name__=='__main__': #main是主函数运行 _name_是程序执行时产生的 unittest.main()-
可通过的测试
-
未通过的测试---应当修改导致测试出错的代码而不是修改测试代码
-
添加新测试
-
断言方法
-
-
-
测试类----类测试通过可认为对类的改进不破坏原有特性
-
各种断言方法
self.assertEqual(a,b)---核实a=b self.assertNotEqual(a,b)---核实a!=b self.assertTrue(x)---核实a为True self.assertFalse(x)---核实a为false self.assertIn(item,list)---核实item在list中 self.assertNotIn(item,list)---核实item不在list中 -
测试
-
方法setup—--一次创建多
-
二 .基础项目
1.数据可视化
-
绘制图形
matplotlib---数学绘图库,plotly包---用于生成数据图表在数字设备上显示、根据设备的尺寸自动调整大小、具备交互性、
-
subplots()————用于绘制一至多个图表
import matplotlib.pyplot as plt square=[1,4,9,16,26,36] fig,ax=plt.subplots() #fig表示一个图表,ax表示图片中的各个图层 ax.plot(square) plt.show() -
修改标签文字和线条粗细---linewidth=x线条粗细,fontsize=x标题大小
---plt.style.use(seaborn)设置线条颜色---ax.scatter(2,4,s=200)s设置点的尺寸
----matlpoltlib异常--字体库中不含中文字体
import matplotlib matplotlib.rc("font", family='Microsoft YaHei')-
设置内置样式
import matplotlib.pyplot as plt plt.style.available -
重用scatter()绘制一系列散点图
x_values=[1,2,3,4,5,6] y_values=[1,4,9,16,25,36] fig,ax=plt.subplots() ax.scatter(x_values,y_values,s=200) x_values=range(1,50) y_values=[x**2 for x in x_values] fig,ax=plt.subplots() #c自定义颜色 s指定单元大小 RGB颜色组"0深1浅" ax.scatter(x_values,y_values,c=1,s=2) //ax.scatter(x_values,y_values,c=(0,0.8,1),s=0.01) #ax.axis指定坐标轴的取值范围 ax.axis([0,1100,0,1100000])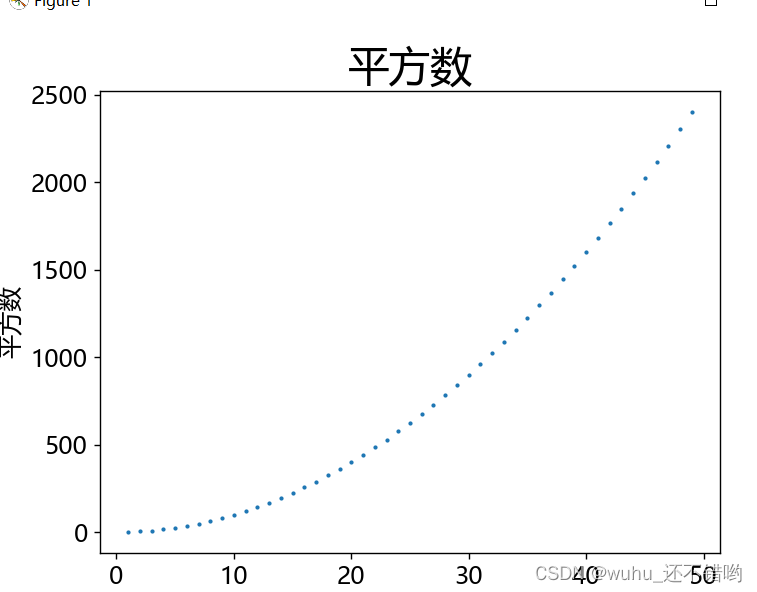
-
使用颜色渐变--以y值为渐变色,数值越大,颜色越深
ax.scatter(x_values,y_values,c=y_values,cmap=plt.cm.Blues,s=0.01)
-
自动保存图表---参数1表示以什么文件名保存,实参2表示受否省略图片周围空白部分
plt.savefig('sruqre_plot.png',bbox_inches='tight')
-
2.随机漫步
-
创建RandomWalk类
from random import choice class RandomWalk: """"一个随机漫步数据的类""" def __init__(self,num_points=5000): """初始化随机漫步的属性""" self.num_points=num_points #所有随机漫步都始于(0,0) self.x_values=[0] self.y_values=[0] def fill_walk(self): """"计算随机漫步包含的所有点""" #不断漫步,直到列表到到指定的高度 while len(self.x_values)<self.num_points: #决定前进方向以及沿这个方向前进的距离 x_direction=choice([1,-1]) x_distance=choice([0,1,2,3,4,5,6]) x_step=x_direction*x_distance y_direction = choice([1, -1]) y_distance = choice([0, 1, 2, 3, 4, 5, 6]) y_step = y_direction * y_distance #拒绝原地踏步 if x_step==0 and y_step==0: continue #计算下一个点的x值以及y值---最近的x位置加上移动方向数 x=self.x_values[-1]+x_step y=self.y_values[-1]+y_step self.x_values.append(x) self.y_values.append(y)函数调用
import matplotlib.pyplot as plt from random_walk import RandomWalk #创建一个randomwalk的实例 rw=RandomWalk() rw.fill_walk() plt.style.use('classic') fig,ax=plt.subplots() ax.scatter(rw.x_values,rw.y_values,s=10) plt.show() -
模拟多次随机漫步
-
给点着色
-
重新绘制起点和终点
ax.scatter(0,0,c='green',edgecolor='none',s=100) ax.scatter(rw.x_values[-1],rw.y_values[-1], c='red', edgecolor='none',s = 100) ax.scatter(rw.x_values,rw.y_values,c=points_numbers,cmap=plt.cm.Blues,edgecolor='none',s=10) -
隐藏坐标轴
ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) -
增加点数---实例中改变
rw=RandomWalk(50000)
-
调整尺寸适用屏幕---指定or改分辨率---1英尺==2.54cm
import matplotlib.pyplot as plt from random_walk import RandomWalk #创建一个randomwalk的实例 while True: rw=RandomWalk(50000) rw.fill_walk() plt.style.use('classic') fig,ax=plt.subplots(figsize=(15,9),dpi=100) #漫步点数 points_numbers=range(rw.num_points) #突出起点和终点---起点(0,0)背景绿色,大小100---终点背景红色,大小100 ax.scatter(0,0,c='green',edgecolor='none',s=100) ax.scatter(rw.x_values[-1],rw.y_values[-1], c='red', edgecolor='none',s = 100) ax.scatter(rw.x_values,rw.y_values,c=points_numbers,cmap=plt.cm.Blues,edgecolor='none',s=1) ax.get_xaxis().set_visible(False) ax.get_yaxis().set_visible(False) plt.show() keep_runing=input("是否还要保持数据漫步?y/n") if keep_runing=='n': break
-
3.模拟掷色子---
-
ployly 生成交互式图表
-
Bar()---用于绘制条形图的数据集
-
Layout()---指定一个图表布局和配置的对象
-
'dtick'---用于设置刻度间距
import matplotlib.pyplot as plt from random import randint class Die: """"模拟一个色子""" def __init__(self,num_side=6): """"一个六面的色子""" self.num_side=num_side def roll(self): """模拟一次投掷过程""" return randint(1,self.num_side) from die import Die from plotly.graph_objs import Bar,Layout from plotly import offline #创建一次六面体骰子 #所有模拟结果存储在一个列表中 die_1=Die() die_2=Die(10) results=[] for roll_num in range(1000): #一次投掷结果集 result=die_1.roll()+die_2.roll() results.append(result) frequencies=[] max_result=die_1.num_side+die_2.num_side for value in range(2,max_result+1): frequency=results.count(value) frequencies.append(frequency) print(frequencies) #结果进行可视化 x_values=list(range(2,max_result+1)) data=[Bar(x=x_values,y=frequencies)] #dtick用于设置刻度间距 x_axis_config={'title':'结果','dtick':1} y_axis_config={'title':'结果的频率'} my_layout=Layout(title='投掷一个d6和一个D8的色子1000次的结果',xaxis=x_axis_config,yaxis=y_axis_config) offline.plot({'data':data,'layout':my_layout},filename='d6_1.html')
-
4.下载的数据可视化
-
可视化数据以CSV以及JSON常见的格式存储
-
CSV文件---将数据以一系列的逗号分隔的值写入文件
-
分析CSV文件的文件头
import csv filename='data/sitka_weather_2018_simple.csv' with open(filename) as f: reader=csv.reader(f) #读取首行和文件头数据 header_row=next(reader) print(header_row) -
打印文件头及其位置
for index,colum_header in enumerate(header_row): print(index,colum_header) -
提取并读取数据
hights=[] for row in reader: hight=int(row[5]) hights.append(hight)
-
-
绘制每天的温度图表
-
可视化温度---
import matplotlib matplotlib.rc("font", family='Microsoft YaHei') import csv import matplotlib.pyplot as plt filename='data/sitka_weather_07-2018_simple.csv' with open(filename) as f: reader=csv.reader(f) #读取首行及头部数据 header_row=next(reader) print(header_row) hights = [] for row in reader: hight = int(row[5]) hights.append(hight) plt.style.use('bmh') fig,ax = plt.subplots() ax.plot(hights, c='red') ax.set_title('2018年7月每日的最高温度', fontsize=26) ax.set_xlabel('日', fontsize=16) ax.set_ylabel('温度(F)', fontsize=16) ax.tick_params(axis='both',which='major',labelsize=16) plt.show() -
读取日期---strptime()--根据格式设置
from datetime import datetime first_data=datetime.strptime('2018-07-01','%Y-%m-%d') print(first_data) -
datetime中的设置格式与时间格式
实参 含义 %A 星期X %B 月份X %m 用数表示的月份 %d 用数表示月份中的某一天 %Y 四位数的年份表示 %y 两位数的年份表示 %H 24小时制的小时数(0~13) %I 12小时制的小时数 %p am或pm %M 分钟数(00~59) %s 秒数(0~61) -
在图表中添加日期----fig.autofmt_xdate()设置倾斜日期标签
import matplotlib matplotlib.rc("font", family='Microsoft YaHei') import csv import matplotlib.pyplot as plt from datetime import datetime filename='data/sitka_weather_07-2018_simple.csv' with open(filename) as f: reader=csv.reader(f) #读取首行及头部数据 header_row=next(reader) print(header_row) #从文件中获取日期和最高温度 dates =[] hights = [] for row in reader: current_date=datetime.strptime(row[2],'%Y-%m-%d') dates.append(current_date) hight = int(row[5]) hights.append(hight) plt.style.use('bmh') fig,ax = plt.subplots() ax.plot(dates,hights, c='red') ax.set_title('2018年7月每日的最高温度', fontsize=26) ax.set_xlabel('', fontsize=16) ax.set_ylabel('温度(F)', fontsize=16) fig.autofmt_xdate() ax.tick_params(axis='both',which='major',labelsize=16) plt.show()-
涵盖更更长的时间
-
绘制一个数据系列
-
给图表区域着色---实参alpha指定颜色的透明度,0--完全透明,1---表示完全不透明----实参facecolor指定区域填充颜色
import matplotlib matplotlib.rc("font", family='Microsoft YaHei') import csv import matplotlib.pyplot as plt from datetime import datetime filename='data/sitka_weather_2018_simple.csv' with open(filename) as f: reader=csv.reader(f) #读取首行及头部数据 header_row=next(reader) print(header_row) #从文件中获取日期和最高温度 dates =[] hights = [] lows=[] for row in reader: current_date=datetime.strptime(row[2],'%Y-%m-%d') dates.append(current_date) hight = int(row[5]) low=int(row[6]) hights.append(hight) lows.append(low) plt.style.use('bmh') fig,ax = plt.subplots(figsize=(15,9),dpi=100) ax.plot(dates,hights, c='red',alpha=0.5) ax.plot(dates,lows,c='blue',alpha=0.5) ax.fill_between(dates,hights,lows,facecolor='green',alpha=0.1) ax.set_title('2018年每日的最高温度', fontsize=26) ax.set_xlabel('', fontsize=16) ax.set_ylabel('温度(F)', fontsize=16) fig.autofmt_xdate() ax.tick_params(axis='both',which='major',labelsize=16) plt.show()-
错误检查---缺失数据+数据不妥善处理=程序崩溃
#数据丢失,温度数据缺失 invalid literal for int() with base 10: '' #发现缺失数据的日期 Missing the data for in{current_date}
-
-
-
-
JSON数据—制作全球地震散点图----plotly提供数据绘制地图的工具
-
查看JSON数据
-
将文件中的数据写人另一个文件
json基于位置存储函数---geoJOSN格式遵循(经度,维度)的约定
-
metadata:指出文件时怎么生成的——能够在网上什么地方找到
——适合人类阅读的标题——文件中记录了多少次地震
-
features:地震数据——列表中每个元素对应一次地震
-
properties:关联到与特定的相关信息以及地震的标题,很好概括了震级和位置
-
geometry:指出地震在什么地方
-
-
5.使用API
三.django网页开发
1.建立项目django
-
建立虚拟环境
python -m venv 11_env
-
激活虚拟环境
source ll_env/bin/activate #停止使用虚拟环境 deactivate -
安装Diango
pip install django
-
在Diango中创建项目
django-admin startproject learning_log .——————创建learning_log文件 dir dir learning_log-
settings.py指定django如何与系统进行交互以及如何管理项目
-
urls.py应该用那些页面来响应浏览器请求
-
wsgi,py帮助django提供它创建的文件 web服务器网关接口
-
-
创建数据库---修改数据库为迁移数据库确保数据库可与项目的当前状态相匹配---在使用SQLlite的新项目中首次使用这个命令,Django将创建一个数据库
python manage.py migrate #准备数据库用于存储执行管理和身份验证的所需信息 -
查看项目----sqlite是一个使用单个文件的数据库
python manage.py runserver #创建了一个development.server的服务器
-
django启动一个名为developent server 的服务器,让你能够查看系统中的项目,了解其中的工作情况。输入URL请求页面,让Django服务器响应生成合适的页面并将其发送给浏览器。
-
2.创建应用程序
-
Django有一系列应用程序组成,它们协同工作让项目成为一个整体
-
startapp appname(XXX)让Django创建搭建应用程序所需的基础设施
-
-
models.py定义要在应用程序中管理的数据
-
admin.py
-
views.py
-
-
python manage.py makemigrations learning_logs makemigrattion ---让Django确定该如何修改数据库---使其存储与前面定义的新模型相关联的数据 修改数据库使其存储与模型Topic相关的信息---输出表明创建了0001-initial.py的迁移文件,这个文件将在数据库中创建一个模型为Topic的表 -
修改学习笔记 ——第一步:修改models.py 第二步:对learnings_logs调用makemigrations 第三步:让Django迁移数据
python manage.py migrate---结果将指出learning_logs应用迁移时一切正常
3.管理网站
-
创建超级用户
python manage.py createsupreuser Django并不存储你输入的密码,而是存储从该密码派生出的一个字符串'散列值' 验证的输入信息与散列值进行比对
-
向管理网站注册模型---手工进行注册
from .models import Topic admin.site.register(Topic) #导入要注册的模块Topic,.models作用是让admin.py所在的目录中查找models,admin.site.register让Django通过管理网站管理模型 -
添加主题---自定义添加
-
定义模型Entry
class Enrty(models.Model): """"学习到的有关某个主题的具体指示""" topic = models.ForeignKey(Topic,on_delete=models.CASCADE) ---级联删除,删除主题的同时删除条目,一个主题含多个条目 text = models.CharField() data_added = models.DateTimeField(auto_now_add=True) ---属性data_added按创建顺序呈现条目,并在每个条目中设置时间戳 class Meta:---meta存储用于管理模型的额外信息在需要时使用Entry verbose_name_plural='entries' def __str__(self):---条目还显示那些信息 """"返回模型的字符串表示""" return f"{self.text[:50]}..." #显示前50个字符-
迁移模型---迁移数据库
python manage.py makemigrations learning_logs python manage.py migrate -
向网站注册Entry
class Entry(models.Model): """"学习到的有关某个主题的具体指示""" topic = models.ForeignKey(Topic,on_delete=models.CASCADE) text = models.CharField(max_length=200) data_added = models.DateTimeField(auto_now_add=True) class Meta: verbose_name_plural='entries' def __str__(self): """"返回模型的字符串表示""" return f"{self.text[:50]}..." #显示前50个字符 admin.site.register(Entry)
-
-
Django shell---交互式终端会话(以编程的方式查看这些数据)
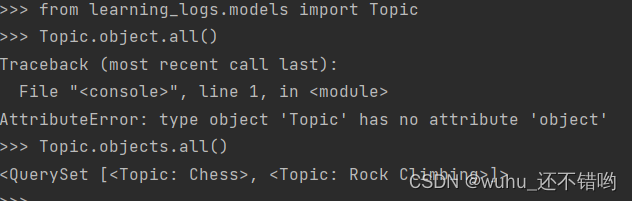
Topic.objects.all()---获取模型Topic的全部实例,将返回一个查询子集的列表
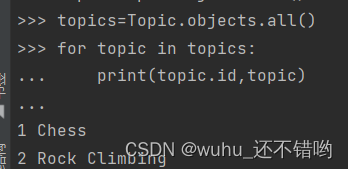
使用方法Topic.objects.get()获取该对象并查看其他属性----Entry中有外键topic可是条目与主题关联起来
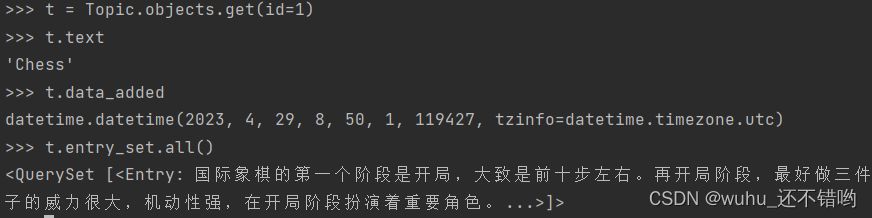
-
通过外键获取属性----使用相关模型的小写名称、下划线、单词set---获取主题全部属性
-
编写用户请求时---可使用,确认代码能获取的数据时,shell环境中排除故障比在生成页面的文件中排除故障容易的多
4.创建界面---学习笔记主页
-
Django创建界面----第一步:定义URL 第二步:编写视图 第三步:编写模板
-
URL模式:视图函数获取并处理界面所需的数据 视图函数通过使用模板来渲染页面 模板定义界面总体结构
-
映射URL:用户通过URL以及单机链接来请求界面
-
urlpatterns:包含项目中应用程序的URL
-
path('',views.index,name='index'), path中接受三个实参,第一个是一个字符串,帮助django正确地路由请求,收到请求的URL后,django将请求路由给一个视图 空字符串与基础字符串匹配 请求的都不匹配返回一个错误信息 第二个是指定了view要调用的函数,请求的url与前述正则表达式相匹配时,将调用view中的index(), 第三个是将这个URL模式的名称指定为index,能够在代码的其他地方引用它
-
-
编写试图:视图函数接受请求中的信息,准备好生成界面所需的数据,在将数据发送给浏览器-----通常是使用定义页面的外观的模板实现
def index(request):---函数render根据试图提供的数据渲染响应 """学习笔记的主页""" return render(request,'learning_logs/index.html') -
编写模板:模板定义页面的外观,每当页面被请求时,django将填入相关的数据,模板能够让你简单访问视图提供的任何数据
<p>Learning Log</p> <p> 学习笔记帮助你更好的学习!!! </p>
-
5.创建其他界面
---扩充学习笔记项目---对于每一个界面指向特定的URL模式、编写一个视图函数以及编写一个模板
-
模板继承---包含通用模板的父模板
-
父模板---base.html---包含所有页面都有的元素,其他模板都继承它----所有页面都包含顶端的标题
-
模板继承:子模版只需定义与当前页面特有的内容,模板修改只需修改父模板即可所做的修改将传到继承父模板的每个页面
{% url 'learning_logs:index' %}---模板标签 生成要在页面中显示的信息,(生成一个URL与在learning_logs/urls.py中定义的index的模式相匹配---确保链接是最新的:只需修改在urls中的URL模式,Django就会在下次被请求时自动插入修改过后的url {% block content %} {% endblock content %}---块标签 块名content,是一个占位符,其中包含的信息由子模块指定 子模版并非必须定义父模板中的每个块,因此在父模板可以使用多的模块来预留空间。而子模版可根据需要定义相应数量的块 -
-
显示所有主题的页面---用户创建、需要使用数据
-
url模式---定义所有主题的页面的URL
urlpatterns=[ #主页 path('',views.index,name='index'), #显示特定主题 path('topics/',views.topics,name='topics'), ] -
视图---数据库中获取数据并交给模板
def topics(request):---#Django从服务器那里收到的request对象 """显示所有主题""" topics=Topic.objects.order_by('date_added')---#查询数据库,请求Topic对象,并排序 context={'topics':topics}---#定义上下文模板,键是模板中用来访问数据的名称,值是要发送给模板的数据 return render(request,'learning_logs/topics.html',context)--- #变量context传递render() -
模板---显示所有主题的模板接受字典context,以便使用topics()提供的数据
{% extends "learning_logs/base.html" %} {% block content %} <p>Topics</p> <ul> {% for topic in topics %} <li>{{ topic }}</li>---循环中要将每个主题转换为项目列表中的一项,每次循环时{{ topic }}都会替换为 ---topic的当前值 {% empty %}---为空时没有添加任何模板 <li>NO topic hava been added yet.</li> {% endfor %} </ul> {% endblock content %}
-
-
显示特定主题的页面---显示该主题的名称及条目
-
url模式
path('topic/<int:topic_id>/', views.topics, name='topic'), topic---让Django查找基础URL后包含单词topics的URL /<int:topic_id>/---作用与包含在斜杠内的整数相匹配,并存储于topic_id的实参内 -
视图
def topic(request,topic_id): """显示单个主题及所有的条目""" topic = Topic.objects.get(id=topic_id) #get获取指定的主题 entries=topic.entry_set.order_by('-data_added') #获取与该主题相关联的条目并排序 context={'topics': topics,'entries':entries} #定义上下文模板,键是模板中用来访问数据的名称,值是要发送给模板的数据 return render(request, 'learning_logs/topics.html', context) #变量context传递render() -
模板
使用topic.id 与使用
{% extends "learning_logs/base.html" %} {% block content %} <p>Topics:{{ topic }}</p>----显示当前主题 <p>Entries:</p> <ul> {% for entry in entries %}---遍历条目 <li> <p>{{ entry.date_added|date:'M d,Y H:i' }}</p>---条目的时间戳格式 <p>{{entry.text|linebreaks }}</p> </li> {% empty %} <li>This topic hava no entry yet.</li> {% endfor %} </ul> {% endblock content %} -
将显示所有主题的页面中的主题设置为链接
<li> <a href="{% url 'learning_logs:topic' topic.id %}"> {{topic}} </a> </li>
6.用户账户
-
让用户输入数据
-
添加新主题
-
用于添加主题的表单
from django import forms from .models import Topic class TopicForm(forms.ModelForm): class Mata: model=Topic fields=['text'] labels=['text': ''] -
URL模式的new_topic
-
视图函数new_topic()---需要处理的情形 1.刚进入new_tipic页面(显示空表单)2.对提交的表单进行数据处理,并将用户重定向到页面topics:
-
GET和POST请求
GET请求:只是从服务器中读取数据
POST请求:需要通过表单提交信息、处理所有表单
-
模板new_topic
{% extends "learning_logs/base.html" %} {% block content %} <p>Add a new topic:</p> <form action="{% url 'learning_logs:new_topic' %}" method="post"> {% csrf_token %} {{ form.as_p }} <button name="submit">Add topic</button> </form> {% endblock content %} -
topic_id 与topic.id的区别
topic.id 检查主题、并获取其ID值;topic_id 指向该ID的引用
-
-
添加新条目
-
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









