









Promise
什么是promise?

promise出现的原因


 参考:(2条消息) 详述Promise的使用(前端必备)_alt鱼的博客-优快云博客_前端promise
参考:(2条消息) 详述Promise的使用(前端必备)_alt鱼的博客-优快云博客_前端promise
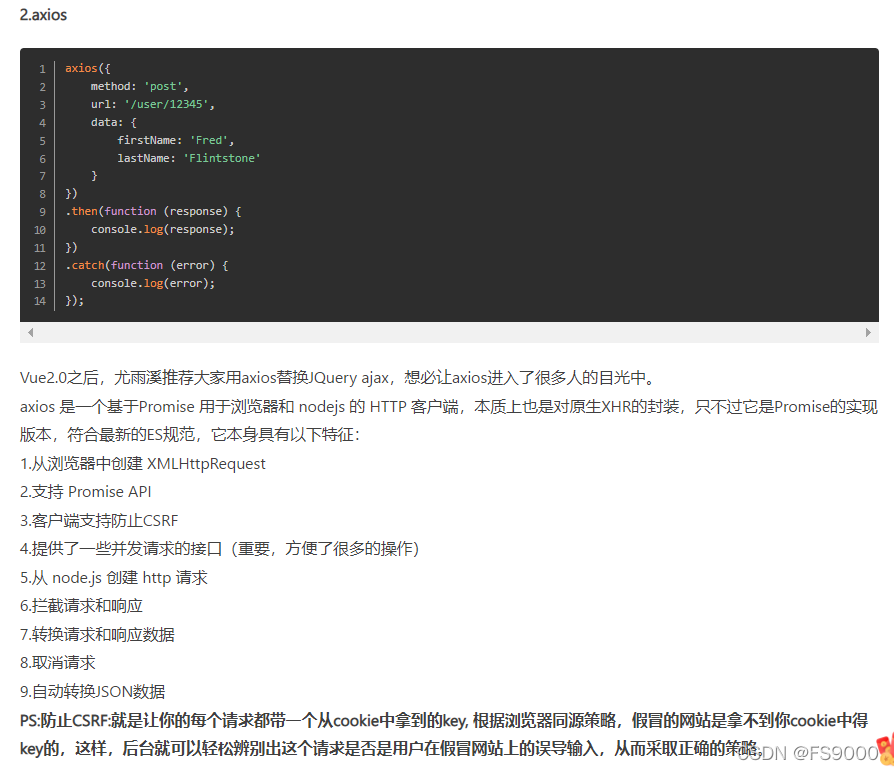
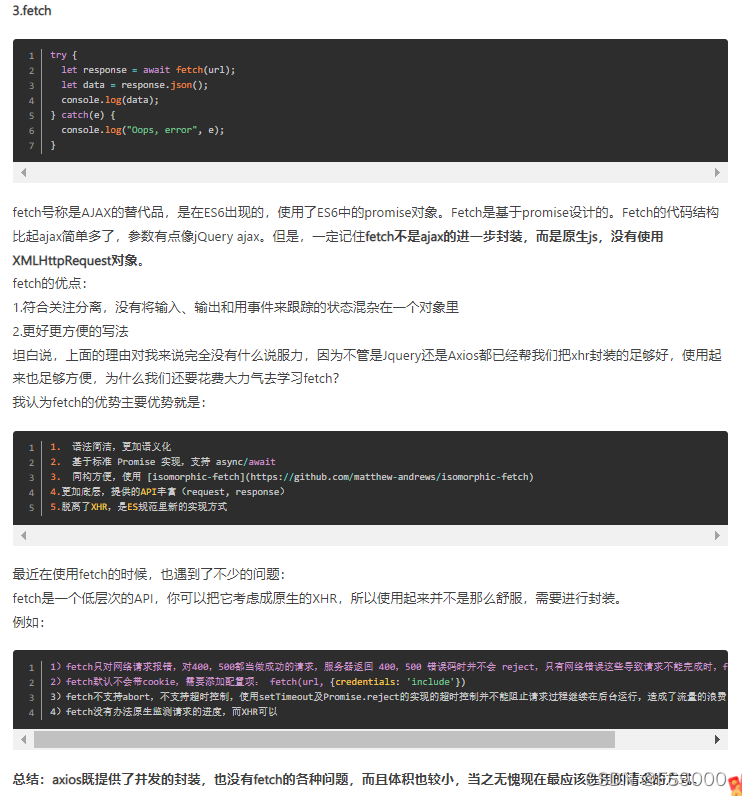
axios和fetch的写法以及区别
关系型数据库和非关系型

Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
迅捷开发
什么是迅捷开发?
敏捷开发(Agile)是一种以人为核心、迭代、循序渐进的开发方法。
在敏捷开发中,软件项目的构建被切分成多个子项目,各个子项目的成果都经过测试,具备集成和可运行的特征。
简单地来说,敏捷开发并不追求前期完美的设计、完美编码,而是力求在很短的周期内开发出产品的核心功能,尽早发布出可用的版本。然后在后续的生产周期内,按照新需求不断迭代升级,完善产品。
敏捷开发模式的分类
敏捷开发的实现主要包括 SCRUM、XP(极限编程)、Crystal Methods、FDD(特性驱动开发)等等。其中 SCRUM 与 XP 最为流行。
同样是敏捷开发,XP 极限编程 更侧重于实践,并力求把实践做到极限。这一实践可以是测试先行,也可以是结对编程等,关键要看具体的应用场景。
SCRUM 则是一种开发流程框架,也可以说是一种套路。SCRUM 框架中包含三个角色,三个工件,四个会议,听起来很复杂,其目的是为了有效地完成每一次迭代周期的工作。在这里我们重点讨论的是 SCRUM。
SCRUM 的工作流程
学习 Scrum 之前,我们先要了解几个基本术语:
Sprint:冲刺周期,通俗的讲就是实现一个“小目标”的周期。一般需要 2-6 周时间。
User Story:用户的外在业务需求。拿银行系统来举例的话,一个 Story 可以是用户的存款行为,或者是查询余额等等。也就是所谓的小目标本身。
Task:由 User Story 拆分成的具体开发任务。
Backlog:需求列表,可以看成是小目标的清单。分为 Sprint Backlog 和 Product Backlog。
Daily meeting:每天的站会,用于监控项目进度。有些公司直接称其为 Scrum。
Sprint Review meeting: 冲刺评审会议,让团队成员们演示成果。
Sprint burn down:冲刺燃尽图,说白了就是记录当前周期的需求完成情况。
Release:开发周期完成,项目发布新的可用版本。
面向对象的三个基本特征
面向对象的三个基本特征是:封装、继承、多态。
封装
封装最好理解了。封装是面向对象的特征之一,是对象和类概念的主要特性。
封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
继承
面向对象编程 (OOP) 语言的一个主要功能就是“继承”。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。
通过继承创建的新类称为“子类”或“派生类”。
被继承的类称为“基类”、“父类”或“超类”。
继承的过程,就是从一般到特殊的过程。
要实现继承,可以通过“继承”(Inheritance)和“组合”(Composition)来实现。
在某些 OOP 语言中,一个子类可以继承多个基类。但是一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现。
继承概念的实现方式有三类:实现继承、接口继承和可视继承。
Ø 实现继承是指使用基类的属性和方法而无需额外编码的能力;
Ø 接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力;
Ø 可视继承是指子窗体(类)使用基窗体(类)的外观和实现代码的能力。
在考虑使用继承时,有一点需要注意,那就是两个类之间的关系应该是“属于”关系。例如,Employee 是一个人,Manager 也是一个人,因此这两个类都可以继承 Person 类。但是 Leg 类却不能继承 Person 类,因为腿并不是一个人。
抽象类仅定义将由子类创建的一般属性和方法,创建抽象类时,请使用关键字 Interface 而不是 Class。
OO开发范式大致为:划分对象→抽象类→将类组织成为层次化结构(继承和合成) →用类与实例进行设计和实现几个阶段。
多态
多态性(polymorphisn)是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。简单的说,就是一句话:允许将子类类型的指针赋值给父类类型的指针。
实现多态,有二种方式,覆盖,重载。
覆盖,是指子类重新定义父类的虚函数的做法。
重载,是指允许存在多个同名函数,而这些函数的参数表不同(或许参数个数不同,或许参数类型不同,或许两者都不同)。
如何实现多态?
一般做法是:写一个方法,它只接收父类作为参数,编写的代码只与父类打交道。调用这个方法时,实例化不同的子类对象(new 一个对象)。
更具体的说:
(1)、子类重写父类的方法。使子类具有不同的方法实现。
(2)、把父类类型作为参数类型,该父类及其子类对象作为参数转入。
(3)、运行时,根据实际创建的对象类型动态决定使用那个方法。
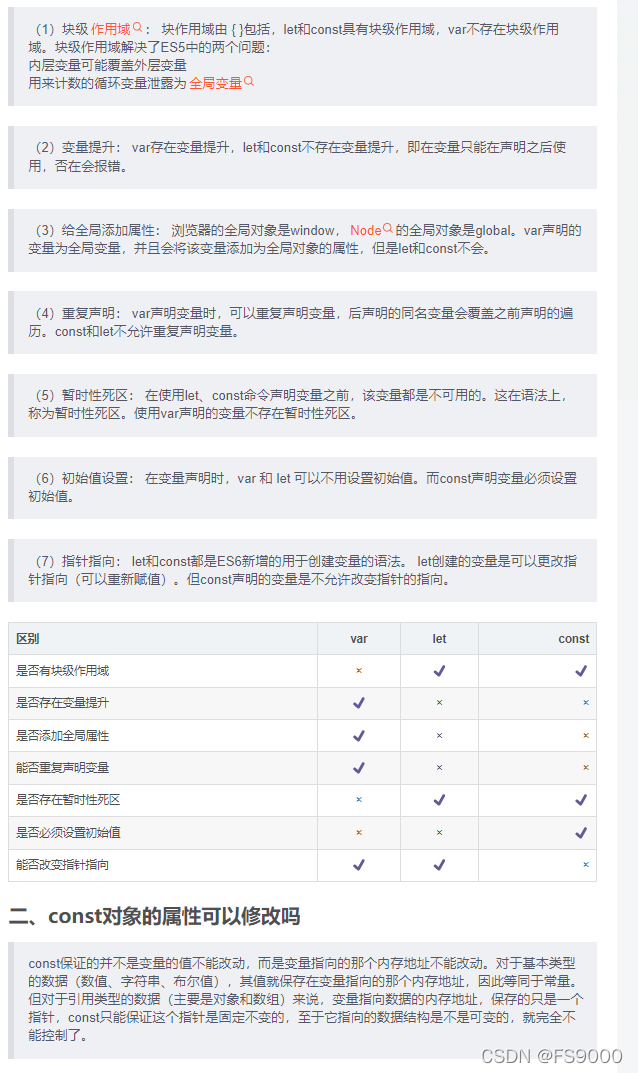
Let、const、var的区别
软件工程
1、什么叫软件工程?
答:软件工程就是将系统的、规范的、可度量的工程化方法应用于软件开发、运行和维护的全过程及上述方法的研究。
2、软件工程有哪些原则?
答:抽象、模块化、信息隐藏、局部化、一致性、完整性和可验证性。
3、什么叫软件?
答:软件的定义是计算机程序及其说明程序的各种文档。
4、什么是软件生命周期?什么是软件的生命周期模型?主要有哪些模型
答: 软件生命周期是指一个软件从提出开发要求开始直到该软件报废为止的整个时期(软件分析时期、软件设计时期、编码与测试时期、运行维护时期)。
关于这个重点说一下,我们平时的编写一些程序的时候,其实就有这个时期,你想刚开始可行性研究(当然,我们一般考虑的是自己的能力和时间是否可以去做这个项目),然后我们的脑子里面有一个大概的想法(概要设计),然后有了数据结构算法(详细设计),之后就开始利用编程语言编写(编码),然后运行测试看看是否符合(测试时期),之后小的程序基本就结束了,像一般的网页或者大一点的程序,就还有运行维护阶段。
软件生命周期模型是描述软件开发过程中各种活动如何执行的模型。
瀑布模型、原型模型、增量模型、喷泉模型、基于知识的模型和变换模型。
5、可行性研究的任务是什么?成本效应分析是什么?
答:(1)技术可行性、经济可行性、社会可行性、操作可行性
(2)成本效益分析是通过比较项目的全部成本和效益来评估项目价值的一种方法。
6、什么是数据流图?画数据流图需要哪些步骤?
答:数据流图是从数据传递和加工角度,以图形方式来表达系统的逻辑功能、数据在系统内部的逻辑流向和逻辑变换过程,是结构化系统分析方法的主要表达工具及用于表示软件模型的一种图示方法。
画系统的输入/输出;画系统内部,即顶层数据流图和0层数据流图。
7、软件总体设计阶段的基本任务是什么?
答:(1)软件系统结构设计(2)数据结构及数据库设计(3)网络系统设计(4)软件总体设计文档(5)评审
10、什么是模块?什么是模块化?
答:模块是可组合、分解和更换的单元。模块化是解决一个复杂问题时自顶向下逐层把软件系统划分成若干模块的过程。
11、什么是耦合?什么是内聚?
答:耦合表示软件结构内不同模块彼此之间相互依赖(连接)的紧密程度,是衡量软件模块结构质量好坏的度量,是对模块独立性的直接衡量指标。
内聚标志一个模块内各个元素彼此结合的紧密程度,它是信息隐藏和局部化概念的自然扩展
一个好的软件,它是低耦合高内聚的。
参考:整理软件工程最基本的几个概念_threecat.up的博客-优快云博客_软件工程概念
React函数式组件和类组件
React定义类组件
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<title>Hello World</title>
<script crossorigin src="https://unpkg.com/react@16/umd/react.development.js"></script>
<script crossorigin src="https://unpkg.com/react-dom@16/umd/react-dom.development.js"></script>
<script src="https://unpkg.com/babel-standalone@6.15.0/babel.min.js"></script>
</head>
<body>
<div id="root"></div>
<script type="text/babel">
class MyComponent extends React.Component{
render(){
return (<h1> hello world </h1>)
};
}
ReactDOM.render(
React.createElement(MyComponent),
document.getElementById('root')
);
</script>
</body>
</html>两种组件的特点区别:
挂载组件 :
函数式组件:react会直接调用该函数,并自动传入props参数
class组件:react会new此组件,并自动传入props参数
更新组件:
函数式组件:更新时,会重新执行此函数
class组件:更新时,该class组件的实例会重新调用自己的render方法,也就是说原来的实例还是原来的实例。通过测试发现:更新时,constructor函数根本没执行,也就是说根本没有new出新的实例。只是原实例会重新调用自己的render方法。
多多使用函数式组件:
函数式组件没有自己的实例,并且函数式组件执行时会捕获当前时刻的props和state(闭包),因为函数式组件更新或者挂载时就是执行此函数,所以函数中定义的函数,就会有闭包现象,因为我们return了JSX出去,如果在JSX上面绑定了相应的事件。那么绑定的事件中就会捕获当前时刻的props和state。在React Hooks 中闭包是十分关键的。
js中的钩子机制
什么是钩子机制?使用钩子机制有什么好处?
钩子机制也叫hook机制,或者你可以把它理解成一种匹配机制,就是我们在代码中设置一些钩子,然后程序执行时自动去匹配这些钩子;这样做的好处就是提高了程序的执行效率,减少了if else 的使用同事优化代码结构。由于js是单线程的编程语言,所以程序的运行效率在前端开发是比较重要的,在开发中我们秉承如果能用switch case 的地方就不要用if else 可以用hook实现的尽量使用hook机制去实现。
这里我们举一个例子看一下:
例如我们在向后台进行ajax请求的时候,后台经常会返回我们一些常见的错误码,如:001代表用户不存在,002代表用户密码输入错误。003代表用户被锁定。这个时候我们要将错误友好的提示给用户。这个时候我们该怎样实现呢?
一般的写法可能是:
$.ajax(option,function(result){
var errCode = result.errCode ;//错误码
if(errCode){
if(errCode =='001'){
alert("用户不存在")
}else if(errCode =='002'){
alert("密码输入错误")
}else if(errCode =='003'){
alert("用户被锁定")
}
}else{
//登录成功
}
},function(err){
})这样写其实是比较low低,稍微有点经验的可能会使用switch case来实现,但是这个两种写法都无法避免一个问题就是如果我的错误码特别多,那得写多少个if else和case 啊?但是如果使用hook写法的话就会简单好多,
首先我们先声明一个错误码钩子列表
var codeList = {
"001":"用户不存在",
"002":"密码输入错误",
"003":"用户被锁定"
}
$.ajax(option,function(result){
var errCode = result.errCode ;//错误码
if(!errCode){
alert(codeList[errCode]);
}else{
//登录成功
}
},function(err){
})这样写的话代码结构更加清楚明了。这个例子是最简单的应用了的了。


















 217
217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











