







大家好我是木木,只从2022年11月30日发布ChatGPT后,大模型迅速火热起来,人工智能作为当下最火的行业之一,很多人对它充满了好奇,接下来通过乳腺癌数据集带领大家进行PCA降维初体验。
算法思想
先说下算法思想,在人工智能机器视觉和大模型未出现之前,机器学习靠着支持向量机顶起一片天,那时候技术没有现如今发达,计算资源相对有限,而随着数据维度增加、特征增加相应的会出现一些挑战,如何在有限的计算资源内,解决更多的问题,PCA降维就此诞生。
数据维度增加:在高维空间内,计算具体的成本将会变得很高。
特征增加:高维空间内,不同的特征可能会有很多的相关性,导致特征冗余。
总的来说:特征构建时,特征之间信息有冗余,在尽可能保留重要的信息下,将高维数据(特征)变成低维数据(特征),可以提升计算性能,降低计算代价。
算法原理
PCA降维是一个无监督学习算法,通过线性变化,进行将高维数据转成低维数据,同时保留最终的要信息。实现方法很多,本次说的是SVD分解。
训练:做SVD分解,并通过右奇异向量选取最重要的X行并转置。
转换:将需要转换的数据输入和右奇异向量做矩阵相乘实现矩阵的降维。
使用乳腺癌进行PCA降维初体验
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.decomposition import PCA
X, y = load_breast_cancer(return_X_y=True)
#划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
#使用PCA降维
pca = PCA(n_components=10)
pca.fit(X=X_train)
#转换数据
X_train = pca.transform(X=X_train)
X_test = pca.transform(X=X_test)
print(f"降维后的数据维度:{X_train.shape},-----{X_test.shape}")
#构建模型
knn = KNeighborsClassifier(n_neighbors=5)
#训练模型
knn.fit(X = X_train, y = y_train)
#预测模型
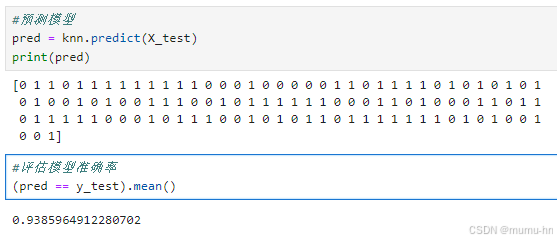
pred = knn.predict(X_test)
print(pred)
#评估模型准确率
(pred == y_test).mean()结果输出
数据特征从原先的30维度降到维度10

模型预测的结果准备率还在90%以上,还可以



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











