






数组
螺旋矩阵II
基本思路
首先初始化一个二维数组,长度和宽度都是n;
定义up down left right四个变量,分别表示上下左右四个边界;
循环条件:四个边界不相等(因为是正方形,所以判断up down即可)
注意,本题的关键在于循环内对每一个边界赋值时,保持区间的开闭性不变,这里以循环内左开右闭为例:
- 对于上边界,每次循环赋值,横坐标都是up,纵坐标位于[left,right)递增
- 对于右边界,每次循环赋值,纵坐标都是right,横坐标位于[up,down)递增
- 对于下边界,每次循环赋值,横坐标都是down,纵坐标 [right,left)递减
- 对于左边界,每次循环赋值,纵坐标都是left,横坐标[down,up)递减
for (int i=left;i<right;i++){
res[up][i] = count;
count++;
}
for (int i=up;i<down;i++){
res[i][right] = count;
count++;
}
for (int i=right;i>left;i--){
res[down][i] = count;
count++;
}
for (int i=down;i>up;i--){
res[i][left] = count;
count++;
}
up++;
down--;
left++;
right--;
最后,需要考虑边界情况:
- 如果上下边界重合,补齐中间一个点。
完整代码
class Solution {
public int[][] generateMatrix(int n) {
int[][] res = new int[n][];
for (int i=0;i<res.length;i++){
res[i] = new int[n];
}
int up = 0;
int down = n-1;
int left = 0;
int right = n-1;
int count = 1;
//up: [left,right)
//right: [up,down)
//down: [right,left) 反向
//left: [down,up) 反向
while(up<=down){
for (int i=left;i<right;i++){
res[up][i] = count;
count++;
}
for (int i=up;i<down;i++){
res[i][right] = count;
count++;
}
for (int i=right;i>left;i--){
res[down][i] = count;
count++;
}
for (int i=down;i>up;i--){
res[i][left] = count;
count++;
}
up++;
down--;
left++;
right--;
}
if (n%2==1){
res[n/2][n/2] = count;
}
return res;
}
}
螺旋矩阵
思路类似,不多写了,需要特别说明,这道题不是正方形,需要关注:
- 循环条件为 上下边界不重合且 左右边界不重合(即up<down&&left<right)
- 边界条件有二种
-
- 上下边界重合
-
- 上下不重合但是左右边界重合
if (up == down) {
for (int i=left;i<=right;i++){
res.add(matrix[up][i]);
}
}else {
if (left == right){
for (int i=up;i<=down;i++){
res.add(matrix[i][right]);
}
}
}
整体代码
class Solution {
public List<Integer> spiralOrder(int[][] matrix) {
List<Integer> res = new ArrayList<Integer>();
int up =0,down = matrix.length-1,left = 0,right = matrix[0].length-1;
while(up<down&&left<right){
for (int i=left;i<right;i++){
res.add(matrix[up][i]);
}
for (int i=up;i<down;i++){
res.add(matrix[i][right]);
}
for (int i=right;i>left;i--){
res.add(matrix[down][i]);
}
for (int i=down;i>up;i--){
res.add(matrix[i][left]);
}
up++;
down--;
right--;
left++;
}
if (up == down) {
for (int i=left;i<=right;i++){
res.add(matrix[up][i]);
}
}else {
if (left == right){
for (int i=up;i<=down;i++){
res.add(matrix[i][right]);
}
}
}
return res;
}
}
链表
反转链表
递归法
最简单的思路,对于一个链表反转,其实就等同于把它后面的链表反转,再把原先的头结点拿到最后。
思路不难,只要注意原先的头结点拿到最后这一步,一定要处理好尾节点的next值,否则就会死循环。
class Solution {
public ListNode reverseList(ListNode head) {
if (head==null){
return null;
}
ListNode res = head;
while(res.next!=null){
res = res.next;
}
reverseAndReturnTail(head);
return res;
}
//反转链表,并返回尾节点的值
public ListNode reverseAndReturnTail(ListNode head){
if (head.next==null){
return head;
}
ListNode tail = reverseAndReturnTail(head.next);
head.next = null;
tail.next = head;
return head;
}
}
迭代法
所谓迭代法,不要想得很难,其实就是把链表的箭头反转一下。
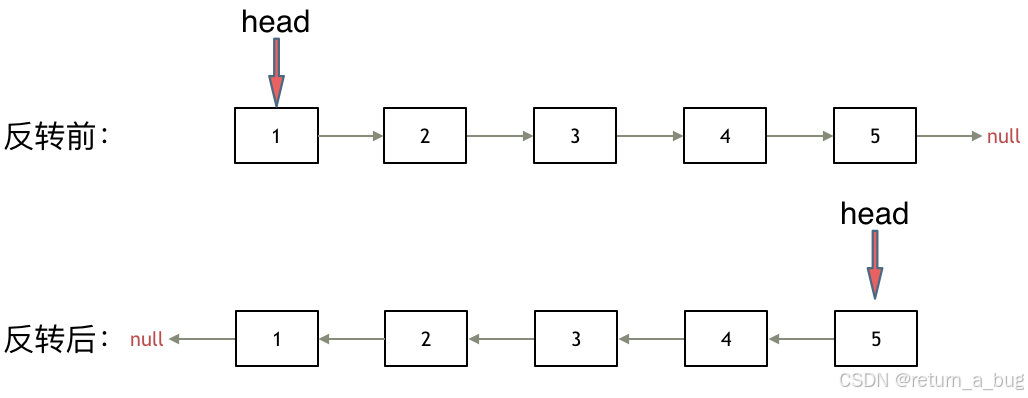
所以关键点在于处理每一个节点的时候,都要提前使用变量记住前一个节点和下一个节点,否则处理完之后就找不到了;
class Solution {
public ListNode reverseList(ListNode head) {
ListNode pre = null;
while(head!=null){
ListNode nextNode = head.next;
head.next = pre;
pre = head;
head = nextNode;
}
return pre;
}
}
两两交换链表中的节点
没什么需要特别注意的,模拟实现即可。
在处理过程中,两节点的前节点和后节点都需要记录,因此需要初始化变量pre为虚拟头结点;
在每次循环的处理过程中,只处理两个节点,因此循环的条件为:
while(pre.next!=null&&pre.next.next!=null)
跳出循环时,pre后面的链表长度只能为0或1,这两种情况都不需要处理了。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode swapPairs(ListNode head) {
ListNode pre = new ListNode();
pre.next = head;
ListNode ans = pre;
while(pre.next!=null&&pre.next.next!=null){
ListNode nextNode = pre.next.next.next;
ListNode tailNode = pre.next.next;
ListNode headNode = pre.next;
pre.next = tailNode;
tailNode.next = headNode;
headNode.next = nextNode;
pre = headNode;
}
return ans.next;
}
}
删除链表的倒数第 N 个结点
思路1:先遍历一遍,获取链表长度s,则被删除的是正序第s-N+1个节点,再遍历到第s-N个节点将其下一个节点删除即可。
思路2:双指针,通过快慢指针实现一次遍历找到被删除的节点的前一个节点;对于N=链表长度的情况,被删除的前一个节点是不存在的,所以需要模拟一个虚拟头节点应对。
class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode vHead = new ListNode();
vHead.next = head;
ListNode fast = vHead;
ListNode slow = vHead;
//要保证快指针到达链表尾的时候,慢指针正好在被删除节点的前一个节点,则它们相差N+1,也就是fast节点需要先走N+1步;
for(int i=0;i<=n;i++){
fast = fast.next;
}
while(fast!=null){
fast = fast.next;
slow = slow.next;
}
slow.next = slow.next.next;
return vHead.next;
}
}
链表相交
双指针法分别从A B两个链表进行移动,当指针a移动到A尾,将其置到B头;当指针b移动到B尾,将其置到A头
- 如果两链表有交点,则在a b指针移动到中间某一点时相交。
- 如果两链表无交点,则a移动到B尾,b移动到a尾,此时两指针都为null
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
// p1 指向 A 链表头结点,p2 指向 B 链表头结点
ListNode p1 = headA, p2 = headB;
while (p1 != p2) {
// p1 走一步,如果走到 A 链表末尾,转到 B 链表
if (p1 == null) p1 = headB;
else p1 = p1.next;
// p2 走一步,如果走到 B 链表末尾,转到 A 链表
if (p2 == null) p2 = headA;
else p2 = p2.next;
}
return p1;
}
}
环形链表II
这道题需要结合一下数学知识。
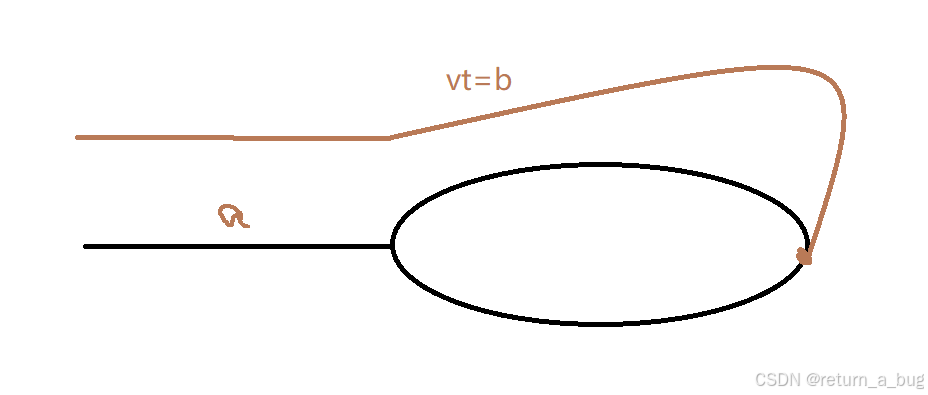
首先根据常识,两个速度不一样快的人,如果在一个环上同时起跑,一定会相遇,且第一次相遇的时候他们相差的距离为一个环的长度。
假设慢的人速度为v,快的人速度为2v,(也就是我们的快慢指针);设入口处到环形起点的距离为a,环形的长度为b。
假定时间为t,则根据上述常识有:2vt-vt = vt = b(一个环的长度)
又有vt=a+x(x是慢的人在环上走的长度),设y为慢的人剩余的环长度
有b = x + y,则vt = a+x = b = x +y
即a = y,也就是快慢指针相遇时,此时从链表头出发一个指针,与慢指针同一速度行进,会在环的入口相遇。
public class Solution {
public ListNode detectCycle(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while(fast!=null&&fast.next!=null){
fast = fast.next.next;
slow = slow.next;
if (fast==slow){
break;
}
}
if (fast==null||fast.next==null){
return null;
}
slow = head;
while(fast!=slow){
fast = fast.next;
slow = slow.next;
}
return fast;
}
}
哈希表
有效的字母异位词
根据题意,就是看A的所有字母重组能否得到B,所以记录A所有字母的出现次数,看B中字母出现的次数是否相等即可。
- 用HashMap记录A的所有字母出现次数,遍历B,如果字母不存在于HashMap,直接返回错误;否则从HashMap中把对应字母count–,若count==0,删除这个key,最后判断HashMap长度是否为0即可。时间复杂度O(N),空间复杂度O(N)
class Solution {
public boolean isAnagram(String s, String t) {
Map<Character,Integer> map = new HashMap<Character,Integer>();
for (int i=0;i<s.length();i++){
map.put(s.charAt(i),map.getOrDefault(s.charAt(i),0)+1);
}
for(int i=0;i<t.length();i++){
if (!map.containsKey(t.charAt(i))){
return false;
}
int count = map.get(t.charAt(i));
count--;
if (count==0){
map.remove(t.charAt(i));
}else{
map.put(t.charAt(i),count);
}
}
if (map.size()==0){
return true;
}
return false;
}
}
- 用数组优化,因为限定了字母是小写字母,所以只用长度为26的数组即可。
时间复杂度O(n),空间复杂度O(1)。
class Solution {
public boolean isAnagram(String s, String t) {
int[] count = new int[26];
int res = s.length();
for (int i =0;i<s.length();i++){
//字母相对于a的偏移量就是数组的下标
int index = s.charAt(i)-'a';
count[index]++;
}
for (int i=0;i<t.length();i++){
int index = t.charAt(i)-'a';
if (count[index]<=0){
return false;
}
count[index]--;
res--;
}
if (res == 0){
return true;
}
return false;
}
}
字母异位词分组
暴力解法O(n^2),直接模拟即可;如要优化到一次遍历O(n),不难想到配合哈希表,也就是把所有是异位词的单词放到同一个哈希槽上,关键在于如何让所有的异位词生成同一个Key?
回顾异位词的定义,使用原单词的所有字母重新组合生成一个新单词,这两个单词互为异位词,换个说法,对这两个单词以一定的规则进行重排序,它们的结果一定是一样的。
因此,我们可以定义一个函数,用一个固定的规则,生成某个单词的哈希Key。
这里以按字母顺序从小到大顺序为例:
public String CalculateKey(String s){
int[] res = new int[26];
for (int i=0;i<s.length();i++){
res[s.charAt(i)-'a']++;
}
StringBuilder sb = new StringBuilder();
for (int i=0;i<26;i++){
while(res[i]>0){
char c = (char)('a'+i);
sb.append(c);
res[i]--;
}
}
return sb.toString();
}
定义好这个方法后,我们只需要对原数组进行一遍遍历,把单词放到对应的Key对应的List中,最后收集HashMap的所有value,用List进行存储,并返回即可。
设n为入参strs的长度,m为其中单词的最大长度。
时间复杂度O(nm);
空间复杂度O(nm)
完整代码:
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String,List<String>> map = new HashMap<String,List<String>>();
for (int i=0;i<strs.length;i++){
String word = strs[i];
String key = CalculateKey(word);
List<String> value = map.getOrDefault(key,new ArrayList<String>());
value.add(word);
map.put(key,value);
}
List<List<String>> res = new ArrayList<List<String>>();
for(List<String> s :map.values()){
res.add(s);
}
return res;
}
public String CalculateKey(String s){
int[] res = new int[26];
for (int i=0;i<s.length();i++){
res[s.charAt(i)-'a']++;
}
StringBuilder sb = new StringBuilder();
for (int i=0;i<26;i++){
while(res[i]>0){
char c = (char)('a'+i);
sb.append(c);
res[i]--;
}
}
return sb.toString();
}
}
找到字符串中所有字母异位词
依据题意可知,滑动窗口的思路,构造左右闭区间的窗口[left,right];
right是遍历整个s数组的指针,每次把s[right]加入到窗口中,判断:
- 窗口大小 小于 p的长度,继续循环(添加下一个元素)
- 窗口大小 等于 p的长度:判断窗口单词和p是否异位词,如果是,添加到元素中;判断完成后将left右移一位。
时间复杂度:O(n+m) = O(m) m为s的长度 n为p的长度
空间复杂度:O(1) 常数级的数组大小
class Solution {
public List<Integer> findAnagrams(String s, String p) {
List<Integer> res = new ArrayList<Integer>();
int[] charCount = new int[26];
int[] count = new int[26];
for (int i=0;i<p.length();i++){
int key = p.charAt(i)-'a';
charCount[key]++;
}
int left = 0;
for (int right=0;right<s.length();right++){
char temp = s.charAt(right);
count[temp-'a']++;
int len =right-left+1;
if (len<p.length()){
continue;
}else if (len==p.length()){
if (IsEqual(count,charCount)){
res.add(left);
}
count[s.charAt(left)-'a']--;
left ++;
}
}
return res;
}
public boolean IsEqual(int[] s,int[] p){
if (s.length!=p.length){
return false;
}
for (int i=0;i<s.length;i++){
if (s[i]!=p[i]){
return false;
}
}
return true;
}
}
两数之和
class Solution {
public int[] twoSum(int[] nums, int target) {
int[] ans = new int[2];
Map<Integer,Integer> map = new HashMap<>();
for (int i=0;i<nums.length;i++){
int need = target - nums[i];
if (map.containsKey(need)){
ans[0] = map.get(need);
ans[1] = i;
return ans;
}else{
map.put(nums[i],i);
}
}
return ans;
}
}
四数相加II
注意题目只需要四元组个数,而不需要具体的四元组数组,使用哈希表存储nums1+nums2的和的可能性个数,再遍历nums3+nums4的所有可能性,看哈希表中是否存在互为相反数的key即可。
class Solution {
public int fourSumCount(int[] nums1, int[] nums2, int[] nums3, int[] nums4) {
HashMap<Integer,Integer> sumCount = new HashMap<>();
int res = 0;
for (int i=0;i<nums1.length;i++){
for(int j=0;j<nums2.length;j++){
int sum = nums1[i]+nums2[j];
int count = sumCount.getOrDefault(sum,0);
sumCount.put(sum,count+1);
}
}
for (int i=0;i<nums3.length;i++){
for (int j=0;j<nums4.length;j++){
int sum = nums3[i]+nums4[j];
int need = -sum;
if (sumCount.containsKey(need)){
res += sumCount.get(need);
}
}
}
return res;
}
}
三数之和
确定第一个数的位置,剩下来要做的就是在剩下的数中找到两数之和=-nums[i]。
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
Arrays.sort(nums);
List<List<Integer>> res = new ArrayList<>();
//[-4 -1 -1 0 1 2]
//[-1 -1 0 1]
for(int i=0;i<nums.length;i++){
if (i>0&&nums[i]==nums[i-1]){
continue;
}
if (nums[i]>0){
break;
}
int sum = 0-nums[i];
//对 [i+1,nums.length-1] 区间寻找两数之和为sum
//双指针 如果和太大,右指针左移;和太小 左指针右移
int left = i+1;
int right = nums.length-1;
while(left<right){
if (nums[left]+nums[right]>sum){
right--;
}else if (nums[left]+nums[right]<sum){
left++;
}else{
List<Integer> temp = new ArrayList<>();
temp.add(nums[i]);
temp.add(nums[left]);
temp.add(nums[right]);
res.add(temp);
right--;
while(left<right&&nums[right]==nums[right+1]){
right--;
}
left++;
while(left<right&&nums[left]==nums[left-1]){
left++;
}
}
}
}
return res;
}
}
四数之和
通过两层循环固定第一个数和第二个数的位置,根据三数之和类似的做法求出四数之和。
class Solution {
public List<List<Integer>> fourSum(int[] nums, int target) {
List<List<Integer>> res = new ArrayList<>();
Arrays.sort(nums);
//[-2 -1 0 0 1 2]
for (int i=0;i<nums.length;i++){
if (i>0&&nums[i]==nums[i-1]){
continue;
}
for (int j=i+1;j<nums.length;j++){
if (j>i+1&&nums[j]==nums[j-1]){
continue;
}
long need = (long)target-nums[i]-nums[j];
int left = j+1;
int right = nums.length-1;
while(left<right){
long sum = (long)nums[left]+nums[right];
if (sum==need){
List<Integer> temp = new ArrayList<>();
temp.add(nums[i]);
temp.add(nums[j]);
temp.add(nums[left]);
temp.add(nums[right]);
res.add(temp);
right--;
while(left<right&&nums[right]==nums[right+1]){
right--;
}
left++;
while(left<right&&nums[left]==nums[left-1]){
left++;
}
}else if(sum >need){
right--;
}else{
left++;
}
}
}
}
return res;
}
}
反转字符串中的单词
先反转整个单词,再去除首尾和中间重复的空格,最后把每个单词反转。
class Solution {
public String reverseWords(String s) {
//反转整个字符串
char[] sArray = s.toCharArray();
int left = 0;
int right = s.length()-1;
while(left<right){
swap(sArray,left,right);
left++;
right--;
}
System.out.println(new String(sArray));
//去除首尾空格和最后的空格
int fast = 0;
int slow = 0;
//去除头空格
while(fast<sArray.length&&sArray[fast]==' '){
fast++;
}
//去除中间多余的空格
// [0,slow)是去除空格后的新字符串
for(;fast<sArray.length;fast++){
if (sArray[fast]!=' '){
sArray[slow] = sArray[fast];
slow++;
}else{
if (sArray[slow-1]==' '){
continue;
}else{
sArray[slow] = ' ';
slow++;
}
}
}
System.out.println(slow);
if (slow>0&&sArray[slow-1] == ' '){
slow--;
}
int l = 0;
for (int tail=0;tail<slow;tail++){
if (sArray[tail]!=' '){
continue;
}
int r = tail-1;
while(l<r){
swap(sArray,l,r);
l++;
r--;
}
l = tail+1;
}
int r = slow-1;
while(l<r){
swap(sArray,l,r);
l++;
r--;
}
return new String(sArray).substring(0,slow);
}
public void swap(char[] s,int i,int j){
char temp = s[i];
s[i] = s[j];
s[j] = temp;
}
}
栈与队列
用栈实现队列
单个栈实现的功能是先进后出,要实现一个FIFO的队列,则需要一个输入栈,一个输出栈;
当元素入队时,直接进入输入栈;当元素出队时,如果输出栈为空,把输入栈的元素全部pop进输出栈,从输出栈取元素。
class MyQueue {
Stack<Integer> in;
Stack<Integer> out;
public MyQueue() {
in = new Stack<>();
out = new Stack<>();
}
public void push(int x) {
in.push(x);
}
public int pop() {
if (out.isEmpty()){
while(!in.isEmpty()){
out.push(in.pop());
}
}
return out.pop();
}
public int peek() {
if (out.isEmpty()){
while(!in.isEmpty()){
out.push(in.pop());
}
}
return out.peek();
}
public boolean empty() {
return in.size()==0&&out.size()==0;
}
}
/**
* Your MyQueue object will be instantiated and called as such:
* MyQueue obj = new MyQueue();
* obj.push(x);
* int param_2 = obj.pop();
* int param_3 = obj.peek();
* boolean param_4 = obj.empty();
*/
栈与队列
有效的括号
每一个左括号一定要对应一个右括号,否则视为无效的括号。
不难联想到每次遍历到右括号时,需要回头看一看有没有左括号,也就是查找队尾元素(先进后出)。
class Solution {
public boolean isValid(String s) {
char[] sArr = s.toCharArray();
Stack<Character> st = new Stack<>();
for (int i=0;i<sArr.length;i++){
if (sArr[i] == '(' || sArr[i] == '{' || sArr[i] == '['){
st.push(sArr[i]);
}else if(sArr[i] == ')'){
if (st.isEmpty()){
return false;
}
if (st.pop()!='('){
return false;
}
}else if(sArr[i] == '}'){
if (st.isEmpty()){
return false;
}
if (st.pop()!='{'){
return false;
}
}else if(sArr[i] == ']'){
if (st.isEmpty()){
return false;
}
if (st.pop()!='['){
return false;
}
}
}
return st.size()==0;
}
}
删除字符串中的所有相邻重复项
遍历字符串时,需要检查当前字符串的队尾元素是否重复,如果重复,需要删除队尾元素,且不入队;否则直接入队。
使用栈的写法
class Solution {
public String removeDuplicates(String s) {
Stack<Character> st = new Stack<>();
char[] sA = s.toCharArray();
for (int i=0;i<sA.length;i++){
boolean flag = false;
while(!st.isEmpty()&&st.peek()==sA[i]){
st.pop();
flag = true;
}
if (!flag){
st.push(sA[i]);
}
}
StringBuilder sb = new StringBuilder();
while(!st.isEmpty()){
sb.append(st.pop());
}
sb.reverse();
return sb.toString();
}
}
使用StringBuilder直接模拟栈
class Solution {
public String removeDuplicates(String s) {
Stack<Character> st = new Stack<>();
char[] sA = s.toCharArray();
StringBuilder sb = new StringBuilder();
int slow = -1;
for (int i=0;i<sA.length;i++){
if (slow>=0&&sb.charAt(slow)==sA[i]){
sb.deleteCharAt(slow);
slow--;
}else{
sb.append(sA[i]);
slow++;
}
}
return sb.toString();
}
}
使用双指针
class Solution {
public String removeDuplicates(String s) {
char[] sA = s.toCharArray();
int slow = 0;
//遍历到第i个元素时,[0,slow)是有效的元素区间
for (int i=0;i<sA.length;i++){
//有效区间的最后一个元素和当前元素相等,有效区间左移;
//否则,当前元素加入区间。
if (slow>0&&sA[slow-1]==sA[i]){
slow--;
}else{
sA[slow] = sA[i];
slow++;
}
}
return new String(sA,0,slow);
}
}
逆波兰表示法
实际是后缀表达式,使用栈进行运算。
需要注意的是,由于栈是先进后出,所以在进行-和/操作的时候,是用后出的数 -或/ 先出的数
class Solution {
public int evalRPN(String[] tokens) {
Stack<Integer> st = new Stack<>();
for (int i=0;i<tokens.length;i++){
if (tokens[i].equals("+")){
int x1 = st.pop();
int x2 = st.pop();
st.push(x1+x2);
}else if (tokens[i].equals("-")){
int x1 = st.pop();
int x2 = st.pop();
//注意 先进的后出,
st.push(x2-x1);
}else if (tokens[i].equals("*")){
int x1 = st.pop();
int x2 = st.pop();
st.push(x1*x2);
}else if (tokens[i].equals("/")){
int x1 = st.pop();
int x2 = st.pop();
st.push(x2/x1);
}else {
int temp = Integer.parseInt(tokens[i]);
st.push(temp);
}
}
return st.pop();
}
}
滑动窗口最大值
重点思路:较小元素本身就对窗口中的最大值无影响,因此无需保留在队列中。
考虑使用滑动窗口的方法进行处理。
实现一种数据结构,能够直接返回窗口中的最大值,不难想到把窗口中的最大值放在队首即可,后续维护一个单调递减队列。
时间复杂度O(N) 空间复杂度O(N)
实现新的数据结构处理
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
MyQueue mq = new MyQueue();
for (int i=0;i<k;i++){
mq.push(nums[i]);
}
int[] res = new int[nums.length-k+1];
res[0] = mq.getMax();
int index = 1;
for (int i=k;i<nums.length;i++){
int removeIndex = i-k;
mq.pop(nums[removeIndex]);
mq.push(nums[i]);
res[index] = mq.getMax();
index++;
}
return res;
}
}
public class MyQueue{
Deque<Integer> de;
public MyQueue(){
this.de = new LinkedList<>();
}
public void pop(int x){
if (de.getFirst()==x){
de.removeFirst();
}
}
public void push(int x){
while(!de.isEmpty()&&de.getLast()<x){
de.removeLast();
}
de.addLast(x);
}
public int getMax(){
return de.getFirst();
}
}
直接用双端队列处理
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
Deque<Integer> de = new LinkedList<>();
for (int i=0;i<k;i++){
while(!de.isEmpty()&&de.getLast()<nums[i]){
de.removeLast();
}
de.addLast(nums[i]);
}
int[] res = new int[nums.length-k+1];
res[0] = de.getFirst();
int index = 1;
for (int i=k;i<nums.length;i++){
int removeIndex = i-k;
if (nums[removeIndex]==de.getFirst()){
de.removeFirst();
}
while(!de.isEmpty()&&de.getLast()<nums[i]){
de.removeLast();
}
de.addLast(nums[i]);
res[index] = de.getFirst();
index++;
}
return res;
}
}
前 K 个高频元素
思路
使用HashMap对元素进行排序和聚合,然后运用语言内置的优先队列,根据出现次数对元素进行堆排序,最终取出topk个元素。
桶排序原理:
对一个无序的数组构造大/小顶堆,原理是从堆底进行比较,将大/小元素向上推,最终使得堆顶元素一定是整个列表中最大/最小的元素;
然后将堆顶和堆底元素互换,并将互换后的堆底元素剔除,继续进行调整,依次取出第二、第三、第K大/小的元素。
class Solution {
public int[] topKFrequent(int[] nums, int k) {
Map<Integer,Integer> wordCount = new HashMap<>();
for (int i=0;i<nums.length;i++){
int count = wordCount.getOrDefault(nums[i],0);
wordCount.put(nums[i],count+1);
}
PriorityQueue<Integer> qu = new PriorityQueue<Integer>(
new Comparator<Integer>(){
@Override
public int compare(Integer o1,Integer o2){
return wordCount.get(o2)-wordCount.get(o1);
}
}
);
Iterator<Map.Entry<Integer,Integer>> it = wordCount.entrySet().iterator();
while(it.hasNext()){
Map.Entry<Integer,Integer> es = it.next();
qu.add(es.getKey());
}
int index = 0;
int[] res = new int[k];
for(int i=0;i<k;i++){
res[index++] = qu.poll();
}
return res;
}
}```
二叉树的迭代遍历
递归法
迭代法
前序遍历
将头结点推入栈中,在栈不为空的情况下,推出栈尾元素并打印,再将其右左子树分别入栈。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
Stack<TreeNode> st = new Stack<>();
List<Integer> res = new ArrayList<>();
st.push(root);
while(!st.isEmpty()){
TreeNode temp = st.pop();
if (temp!=null){
res.add(temp.val);
st.push(temp.right);
st.push(temp.left);
}
}
return res;
}
}
后序遍历
模拟后序遍历的逻辑:对于每一个Node节点,首先判断其左右子树是否被访问过,都被访问过,则输出Node.val,并继续向上;如果左子树没被访问过,优先遍历左子树;否则看右子树是否访问过,否则遍历右子树。
class Solution {
public List<Integer> postorderTraversal(TreeNode root) {
if (root==null){
return new ArrayList<>();
}
Stack<TreeNode> stack = new Stack<>();
HashSet<TreeNode> visit = new HashSet<>();
List<Integer> res = new ArrayList<>();
stack.push(root);
while(!stack.isEmpty()){
TreeNode temp = stack.peek();
if (temp.left!=null&&!visit.contains(temp.left)){
stack.push(temp.left);
continue;
}
if (temp.right!=null&&!visit.contains(temp.right)){
stack.push(temp.right);
continue;
}
res.add(temp.val);
visit.add(temp);
stack.pop();
}
return res;
}
}
中序遍历
模拟后序遍历的逻辑;对于每一个Node节点,先判断左子树是否都访问完了,是则出栈并将右子树推入;否则将左子树推入栈中.
class Solution {
public List<Integer> inorderTraversal(TreeNode root) {
List res = new ArrayList<Integer>();
Stack<TreeNode> stack = new Stack<>();
while(root!=null||!stack.isEmpty()){
while(root!=null){
stack.push(root);
root = root.left;
}
TreeNode temp = stack.pop();
res.add(temp.val);
root = temp.right;
}
return res;
}
}
对称二叉树
实质上是比较左右子树是否对称,采用递归的方式,左子树用根左右去遍历,右子树用根右左去遍历,并且每次都要比较根节点的值是否相等。
class Solution {
public boolean isSymmetric(TreeNode root) {
return dfs(root.left,root.right);
}
public boolean dfs(TreeNode n1 ,TreeNode n2){
if (n1==null&&n2==null){
return true;
}
if (n1==null||n2==null){
return false;
}
if (n1.val!=n2.val){
return false;
}
boolean t1 = dfs(n1.left,n2.right);
boolean t2 = dfs(n1.right,n2.left);
return t1&&t2;
}
}
二叉树的最大深度
class Solution {
public int maxDepth(TreeNode root) {
if (root==null){
return 0;
}
int maxDepthLeft = maxDepth(root.left);
int maxDepthRight = maxDepth(root.right);
return Math.max(maxDepthLeft,maxDepthRight)+1;
}
}
二叉树的最小深度
递归法
使用后序遍历的方法,先求左右子树的最小深度,再比较得到根节点的最小深度。
需要特别注意的是,题目中强调了最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
也就是说如果根节点的左子树为空,那么左边的深度是不需要计算的;同样如果右子树节点为空,右边的深度不需要计算。
class Solution {
public int minDepth(TreeNode root) {
if (root==null){
return 0;
}
return dfs(root);
}
public int dfs(TreeNode root){
if (root==null){
return 0;
}
int leftDepth = minDepth(root.left);
int rightDepth = minDepth(root.right);
if (root.left==null){
return 1+rightDepth;
}
if (root.right==null){
return 1+leftDepth;
}
return 1+Math.min(leftDepth,rightDepth);
}
}
迭代法
根据最小深度的定义,只需要找到第一个出现的叶子节点,得到他的深度即可。
用栈来实现程序遍历。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public int minDepth(TreeNode root) {
if (root==null){
return 0;
}
Queue<TreeNode> q = new LinkedList<>();
q.add(root);
int depth = 0;
while(!q.isEmpty()){
depth++;
int s = q.size();
//这里不能把i<s写成i<q.size(),因为每次循环q的长度都在变
for (int i=0;i<s;i++){
TreeNode temp = q.poll();
if (temp.left==null&&temp.right==null){
return depth;
}
if (temp.left!=null){
q.add(temp.left);
}
if (temp.right!=null){
q.add(temp.right);
}
}
}
return depth;
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









