







 本文详细介绍了Spark的RDD(弹性分布式数据集)概念,包括其五个特性、分区与分区算子(如map与mapPartitions)、重分区算子(如repartitions和coalesce)、聚合算子(如reduce和aggregateByKey)以及关联算子(如join和groupByKey)。重点讲解了如何根据数据规模选择合适的操作和性能优化策略。
本文详细介绍了Spark的RDD(弹性分布式数据集)概念,包括其五个特性、分区与分区算子(如map与mapPartitions)、重分区算子(如repartitions和coalesce)、聚合算子(如reduce和aggregateByKey)以及关联算子(如join和groupByKey)。重点讲解了如何根据数据规模选择合适的操作和性能优化策略。
目录
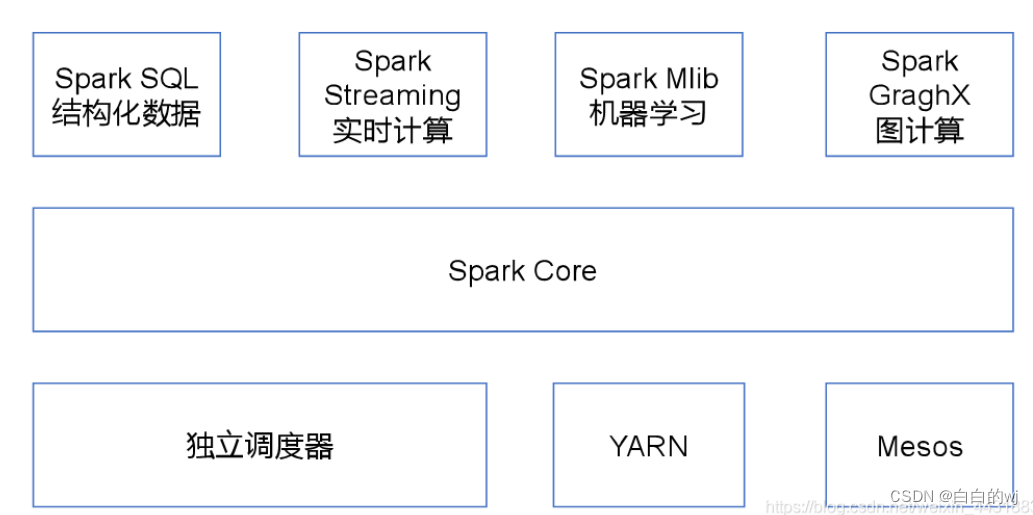
一 . RDD(弹性分布式数据集)
Resilent弹性 Distrbuted分布式 Dataset数据集
1. rdd是Spark底层的数据结构
2. Task 在Spark中就是线程
3 . RDD中的一个分区就是一个线程,分区数有多少线程数就有多少 ,set Master local里设置的就是线程
4. 使用 sc.parallelize(result)构建rdd,他的分区数量是受setMaster的local数影响的,你设置多少个就是多少分区 ; 如果这里写local[*],就会默认分区数是cpu核数 ; 如果在参数里有设置numslices, name就以参数的这个数量为分区数
5. 使用 sc.textfile构建RDD , 把setMaster 的local[]的值设置大于2的时候,不生效,分区的数量还是2 , 但是调小会生效 ;
在minPartitions里没有设置参数,那么一般就根据公式min(spark.default.parallelism,2)
在参数里设置 minPartitions, 这个参数设置的是最小分区的,所以得出来分区数是大于等于minPartitions设置的数的, 个别情况底层也会有优化,钥匙设置100,可能会出来36, 总之到底是多少没法保证 ;
6. 使用wholeTextFile 构建RDD, setMaster 的local 数量 ,minPartitions , 文件的具体数量 ,都会影响分区的数量, 当设置了minPartitions的时候,最大的分区数量为 文件的最大数量
# 查看分区数的命令
data = [1,2,3,4,5,6]
init_rdd = sc.parallelize(data)
print(init_rdd.getNumPartitions())
# 查看分区数
init_rdd = sc.textFile( 'file:///export/data/2024.1.2_Spark/1.2_day01/content.txt' , minPartitions=10 )
7 .RDD 的分区数据量受到多个因素,例如:机器Cpu的核数 , 调用的算子 , 算子中参数的设置,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











