





YOLO(You Only Look Once)系列模型是一类非常高效的目标检测模型。其主要特点是能够在单次前向传播中同时进行目标的定位和分类,实现实时的目标检测。YOLO 系列模型从最初的 YOLOv1 到目前的 YOLOv10,经过了多次迭代和改进,逐渐提高了检测的精度和速度。

YOLO简史
YOLOv1
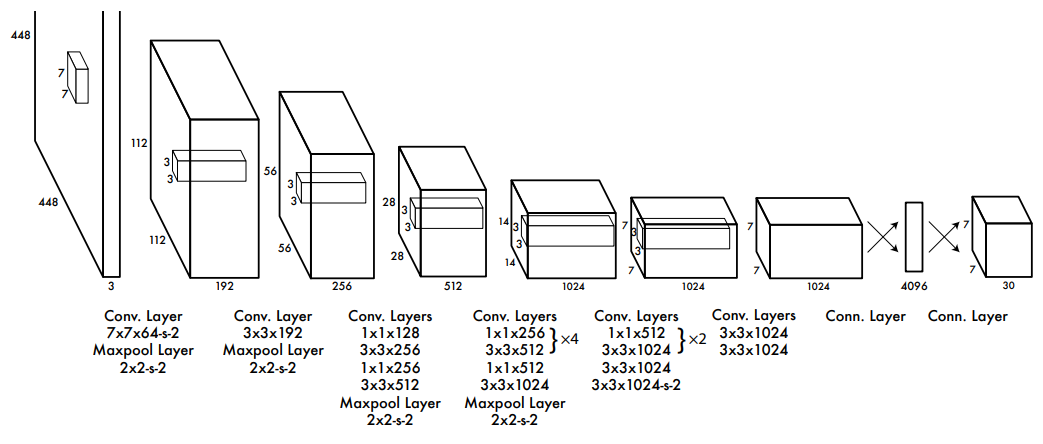
YOLOv1架构图
2015 年,Joseph Redmon 及其团队革命性地推出了 YOLOv1(You Only Look Once version 1),这一里程碑式的实时目标检测模型彻底颠覆了传统检测方法的框架。
YOLOv1 凭借其独特的设计理念——将目标检测任务转化为一个单一的回归问题,仅通过一次前向传播即可同时预测出图像中物体的边界框及其类别概率,极大地提升了检测速度与效率,为后续版本的迭代与优化奠定了坚实的基础。。

定性结果
-
参考论文:You Only Look Once: Unified, Real-Time Object Detection
-
论文链接:https://arxiv.org/abs/1506.02640
-
官方链接:https://pjreddie.com/darknet/yolo/
YOLOv2
次年,原班底提出 YOLO9000,作为 YOLO 系列的第二代力作,在 V1 的基础上做了很多改进,包括使用批量归一化、锚框、维度聚类、多尺度训练和测试等技术来提高模型的精度和鲁棒性。在标准的 VOC 2007 测试集上,YOLOv2 达到了 76.8% 的 mAP,比 YOLOv1 的 63.4% 有了明显提升。

-
参考论文:YOLO9000: Better, Faster, Stronger
-
论文链接:https://arxiv.org/abs/1612.08242
-
官方链接:http://pjreddie.com/yolo9000/
YOLOv3
YOLOv3 是 YOLO 系列目标检测模型的第三个版本,由 Joseph Redmon和Ali Farhadi 于 2018 年提出。YOLOv
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









