






1.eventLoop :
在nettry简介中我们可以了解到我们的eventLoop是一个Selector+一个单线程执行器。里面的run方法处理channel上源源不断的io事件(selecctor多路复用 操作系统提供的结构 可以让一个线程监听多个信道,有任务来了就去通知我们的线程来执行)
我们知道eventLoop是用来帮助我们执行IO操作的,当我们的channel被创建好过后,我们会将他他注册进一个eventLoop中,让eventLoop来监听它的IO操作并且进行处理
我们来简单的过一下流程:
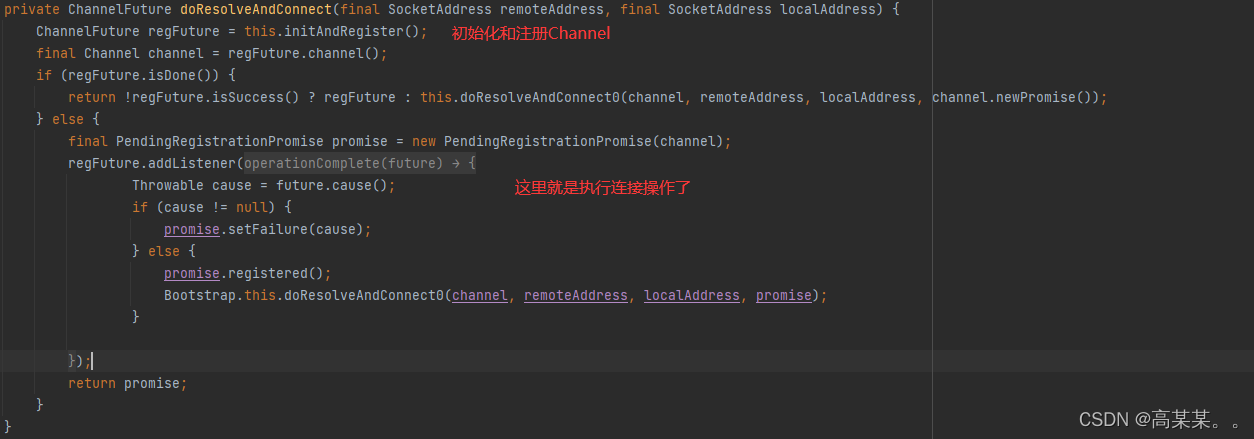
====================================================================================
final ChannelFuture initAndRegister() {//初始化和注册Channel
Channel channel = null;
try {
channel = this.channelFactory.newChannel();//这个是我们初始化ServerBootStrap的时候传入的channel的class信息形成的对象 他就是反射生成对象
this.init(channel);//可能设计到操作系统的底层操作了 我进不去
} catch (Throwable var3) {
if (channel != null) {
channel.unsafe().closeForcibly();
}
return (new DefaultChannelPromise(channel, GlobalEventExecutor.INSTANCE)).setFailure(var3);
}
ChannelFuture regFuture = this.config().group().register(channel);//这里就是关键步骤 向我们的eventGroup注册channel 就是将这个信道交给我们的其中一个eventLoop来处理 他会监听这个信道是否有IO操作 并且处理 至于怎么监听 操作系统底层的Selector收到IO会发给我们的
if (regFuture.cause() != null) {
if (channel.isRegistered()) {
channel.close();
} else {
channel.unsafe().closeForcibly();
}
}
return regFuture;
}
遇到IO操作它的做法:
//它后面会跳到这个write方法中
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = this.findContextOutbound();//通过当前的ChannelHandlerContext来找到下一个是ChannelOutBountContext 处理输出的
Object m = this.pipeline.touch(msg, next);
EventExecutor executor = next.executor();//获取当前的ctx所对应的信道注册在的EventLoop
//为什么是EventExeccutor 他是他们的公共父类 所有的EventLoop都是它的子类
if (executor.inEventLoop()) {//判断当前的线程是否是我们的这个EventLoop所对应的线程 如果是就执行
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {//如果不是当前的线程 我们需要做一些其他的安全处理的操作
Object task;
if (flush) {
task = AbstractChannelHandlerContext.WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = AbstractChannelHandlerContext.WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, (Runnable)task, promise, m);
}
}
2.ChannelHandler 和 ChannelPipeline
channelHandler是对我们的输入进来的数据进行操作的一个实现接口 , 用户可以通过自定义的实现来帮助我们获取需要的对象,而ChannelPinpeline会将handler包含进来 ,每一个channel都会有一个对应的Pinpeline来帮助它顺着逻辑线来处理我们的流,如图: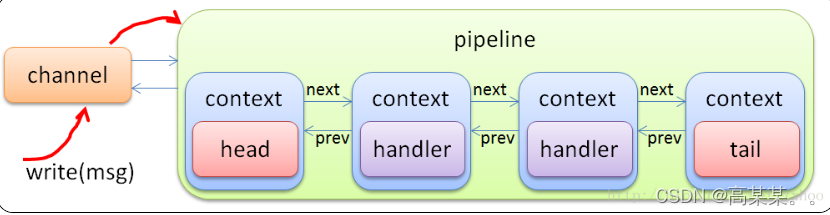
我们直接通过信道调用write方法查看它的执行流程:
通过这个我们可以看出 在Channel对象创建的时候我们就已经为他创建了一个ChannelPipeline
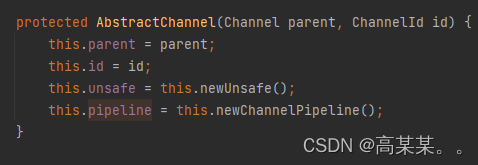
调用它的write方法:

//构造方法 创建了ChannelPipeline 创建了一个头指针和尾指针
protected DefaultChannelPipeline(Channel channel) {
this.channel = (Channel)ObjectUtil.checkNotNull(channel, "channel");
this.succeededFuture = new SucceededChannelFuture(channel, (EventExecutor)null);
this.voidPromise = new VoidChannelPromise(channel, true);
this.tail = new DefaultChannelPipeline.TailContext(this);//创建特殊的头部和尾部节点
this.head = new DefaultChannelPipeline.HeadContext(this);
this.head.next = this.tail;
this.tail.prev = this.head;
}
public final ChannelFuture write(Object msg) {
return this.tail.write(msg);//从尾巴上开始调用write方法
}
public ChannelFuture write(Object msg) {
return this.write(msg, this.newPromise());//尾和头都是我们创建的特殊节点
}
public ChannelFuture write(Object msg, ChannelPromise promise) {//做完一些校验操作过后调用我们的write方法
if (msg == null) {
throw new NullPointerException("msg");
} else {
try {
if (this.isNotValidPromise(promise, true)) {
ReferenceCountUtil.release(msg);
return promise;
}
} catch (RuntimeException var4) {
ReferenceCountUtil.release(msg);
throw var4;
}
this.write(msg, false, promise);
return promise;
}
}
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = this.findContextOutbound();//从尾部向前开始寻找可以的输出处理器
Object m = this.pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);//执行任务
} else {
next.invokeWrite(m, promise);
}
} else {
Object task;
if (flush) {
task = AbstractChannelHandlerContext.WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = AbstractChannelHandlerContext.WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, (Runnable)task, promise, m);
}
}
private void invokeWriteAndFlush(Object msg, ChannelPromise promise) {
if (this.invokeHandler()) {//调用我们的自己的handler来帮助我们进行处理
this.invokeWrite0(msg, promise);
this.invokeFlush0();
} else {
this.writeAndFlush(msg, promise);//直接write
}
}
原文:https://www.jianshu.com/p/b9f3f6a16911
1.netty使用了NIO,非阻塞的具体在之前的NIO文章介绍了一点NIO。
2.NIO之所以快还有一个原因就是它不会像其他的一样从Socket赋值到java的堆内存中,而是直接由操作系统开辟一个空间直接使用 所以省去了复制的时间。
http的组成:
所以我们不能一个HttpRequest多次处理 最好一次直接处理一个完整的FullHttpRequest
public class HttpServer {
private final int port;
public HttpServer(int port) {
this.port = port;
}
public static void main(String[] args) throws Exception {
new HttpServer(8888).start();
}
public void start() throws Exception {
ServerBootstrap serverBootstrap=new ServerBootstrap();
NioEventLoopGroup group=new NioEventLoopGroup();
serverBootstrap.group(group)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {//我们自定义的处理功能
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
System.out.println(socketChannel);
socketChannel.pipeline()
//这个decoder是将我们读取到的byte-->Message
.addLast("decoder",new HttpRequestDecoder())
//将response的 Message-->byte 因为网络通信是0,1字节传输的
.addLast("encoder",new HttpResponseEncoder())
//HttpObjectAggregator会保证http请求的完整 它会将属于统一Http请求的信息封装起来 再我们的Handler处理时直接处理完整的请求
//以免每次处理请求的一部分 512*1024是合并后的一个请求最大的长度
.addLast("aggregator",new HttpObjectAggregator(512 * 1024))
.addLast("handler",new HttpHandler());
//这个是处理我们的返回值 对业务逻辑进行处理
}
})
.option(ChannelOption.SO_BACKLOG,128)
.childOption(ChannelOption.SO_KEEPALIVE,Boolean.TRUE);
serverBootstrap.bind(port).sync();
}
}
1.HttpRequestDecoder,用于解码request
2.HttpResponseEncoder,用于编码response
3.aggregator,消息聚合器(重要)。为什么能有FullHttpRequest这个东西,就是因为有他,HttpObjectAggregator,如果没有他,就不会有那个消息是FullHttpRequest的那段Channel,同样也不会有FullHttpResponse。
如果我们将z’h
HttpObjectAggregator(512 * 1024)的参数含义是消息合并的数据大小,如此代表聚合的消息内容长度不超过512kb。
4.添加我们自己的处理接口。
public class HttpHandler extends SimpleChannelInboundHandler<FullHttpRequest> {//fullHttpRequest泛型代表我们接收的类型只能是一个完整的Http请求
private AsciiString contentType = HttpHeaderValues.TEXT_PLAIN;
@Override
protected void channelRead0(ChannelHandlerContext channelHandlerContext, FullHttpRequest fullHttpRequest) throws Exception {
System.out.println("class"+fullHttpRequest.getClass().getName());
DefaultFullHttpResponse httpResponse=new DefaultFullHttpResponse(HttpVersion.HTTP_1_1, HttpResponseStatus.OK, Unpooled.wrappedBuffer("test".getBytes()));
//响应头的设置
HttpHeaders headers = httpResponse.headers();
headers.add(HttpHeaderNames.CONTENT_TYPE,contentType + "; charset=UTF-8");
headers.add(HttpHeaderNames.CONTENT_LENGTH,httpResponse.content().readableBytes());
headers.add(HttpHeaderNames.CONNECTION,HttpHeaderValues.KEEP_ALIVE);
channelHandlerContext.write(httpResponse);
}
//执行完上面的read方法过后的处理逻辑
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
System.out.println("channelReadComplete");
super.channelReadComplete(ctx);
ctx.flush();
}
//出现异常过后的处理逻辑
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
System.out.println("exceptionCaught");
if(cause!=null) cause.printStackTrace();
if(ctx!=null) ctx.close();
}
}
我们先运行一下含有aggregator(和并一个请求的处理):
运行程序 直接在浏览器访问我们设置的端口:

可以看到一个请求只执行了一次:

我们去掉HttpServer中的.addLast("aggregator",new HttpObjectAggregator(512 * 1024))和将HttpHandler 的泛型去掉再次执行:
可以看到一个请求被拆分为了两个来处理:


















 2384
2384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









