






基于SparkStreaming的流数据处理和分析简介
一、流是什么
数据流:
①:数据的流入
②:数据的处理
③:数据的流出
流处理:
是一种允许用户在接收到数据后的短时间内快速查询连续数据流和检索条件的技术
什么需要流处理:
①:能够快速的提供查询能力,通常在毫秒之间,
②:大部分数据的产生过程都是一个永无止境的事件流
—>要进行批处理,需要存储,在某个时间停止数据收集,并处理数据
—>流处理自然适合时间序列数据和检测模式随时间推移
二、常用的流处理框架
①:Apache Spark Streaming
②:Apache Flink
③:Confluent
④:Apache Strom
针对Spark Streaming简介
Spark Streaming是基于Spark Core API的扩展,用于流式数据处理
优点:
①:高容错
②:可扩展
③:高流量
④:低延时
支持多种数据源和输出:
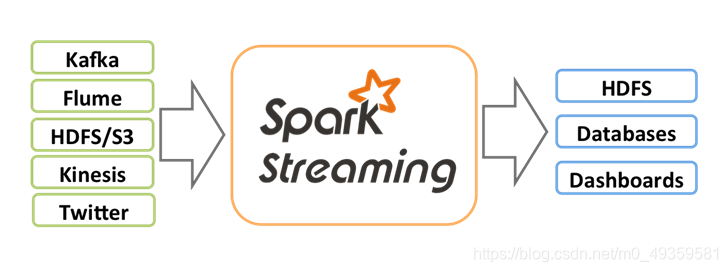
Spark Streaming流数据处理架构
典型架构: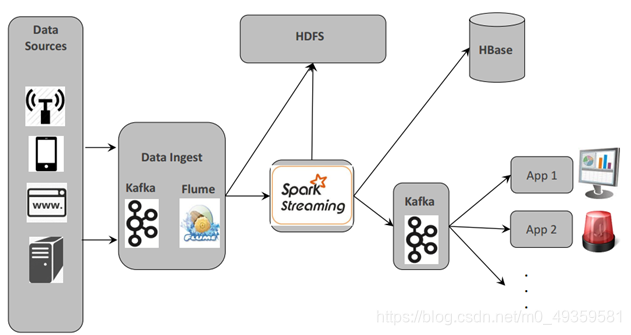
Spar Streaming工作流程
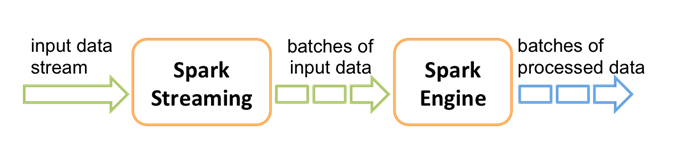
微批处理:输入 -> 分批处理 -> 结果集
—>以离散流的形式传入数据,(DStream:Discretized Streams)
—>流被分成微批次(1-10) 每一个微批都是一个RDD
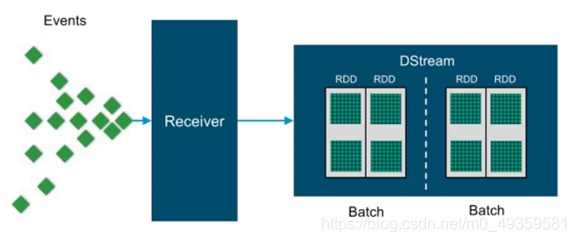
DStream
离散数据流流(Discretized Stream)是Spark Streaming提供的高级别抽象
DStream代表一系列连续的RDD算子
每个RDD都包含一个时间间隔内的数据
DStream既是输入数据流,也是转换处理过的数据流
对DStream的转换既是对具体RDD的操作
Input DStream与接收器
Input DStream指从某种流式数据源(Streaming Sources)接收数据的DStream
内建流式数据源:文件系统,Socket,Kafka,Flume…


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









