






1.背景
前段时间接了一个简单的需求,业务需要对本地缓存caffiene做拆解,把一部分及时性要求高的数据单独拆出来从新的redis读取。为了做数据的灰度验证,所以原缓存中被拆分的字段任然保留,逐步放量切到新缓存,新redis数据有问题的情况下可以及时通过灰度切换原缓存,保证不对线上业务产生影响。
2.问题
业务灰度上线后通过监控发现新发版的机器young gc次数和耗时都有较大增加,业务请求处理耗时涨了20ms,请求失败率翻倍上涨。
同时查了caffiene缓存的监控,发现新缓存加载耗时是原缓存的几千倍,分析了两个缓存的差异后得到以下两个解决方案:
方案一
通过arthas生成服务的cpu火焰图发现新加的缓存中获取到redis中的json数据后,使用fastJson转java对象占用cpu时间较多。原缓存使用的protobuf协议,存入redis的数据为字节码,在进行对象转换时性能会更好。所以可以在生成redis数据时使用pb格式,减少读取数据后的对象转换耗时。
方案二
针对灰度机器的gc频率和耗时升高的问题,是因为新增了一个本地缓存,加载缓存创建了大量对象,在缓存容量达到设定的最大值后开始频繁的逐出旧数据,进而导致频繁gc。所以可以把两个本地缓存融合成一个新的缓存,减少对象的创建。同时重写缓存的reload方法,每次重新加载都会判断数据是否更新,没有更新的数据不会进行重新赋值,保证长期使用的缓存对象一直呆在老年代,不走竟升流程,减少gc压力。
3.第一次优化
按照上述方案优化后,缓存的加载耗时较没拆分缓存之前有一定幅度上涨,但是在预期范围内。
GC的问题有一定好转,但是gc耗时依然高了30%以上,服务请求耗时整体高了10ms,达不到上线要求。
拉取了线上的gc日志,没发现有什么问题
后续在本地搭建压测环境使用jprofile分析内存占用情况(线上dump文件太大不方便分析)
先找到最大对象CaffieneCacheService
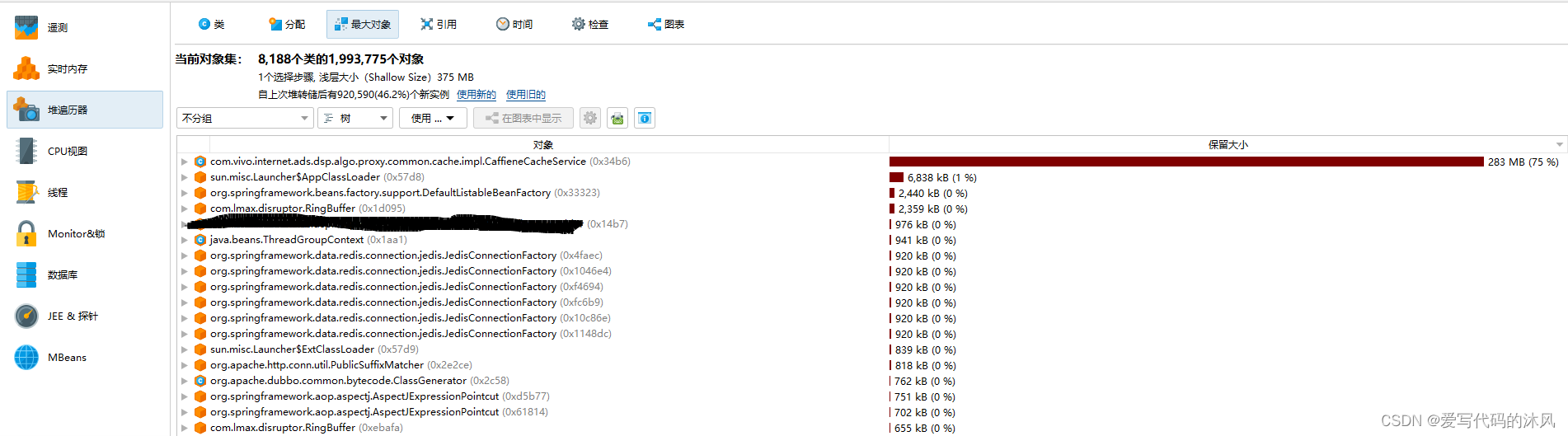
发现新加的缓存对象实例数要比原缓存多很多,导致gc耗时长的根本原因可能就在这里
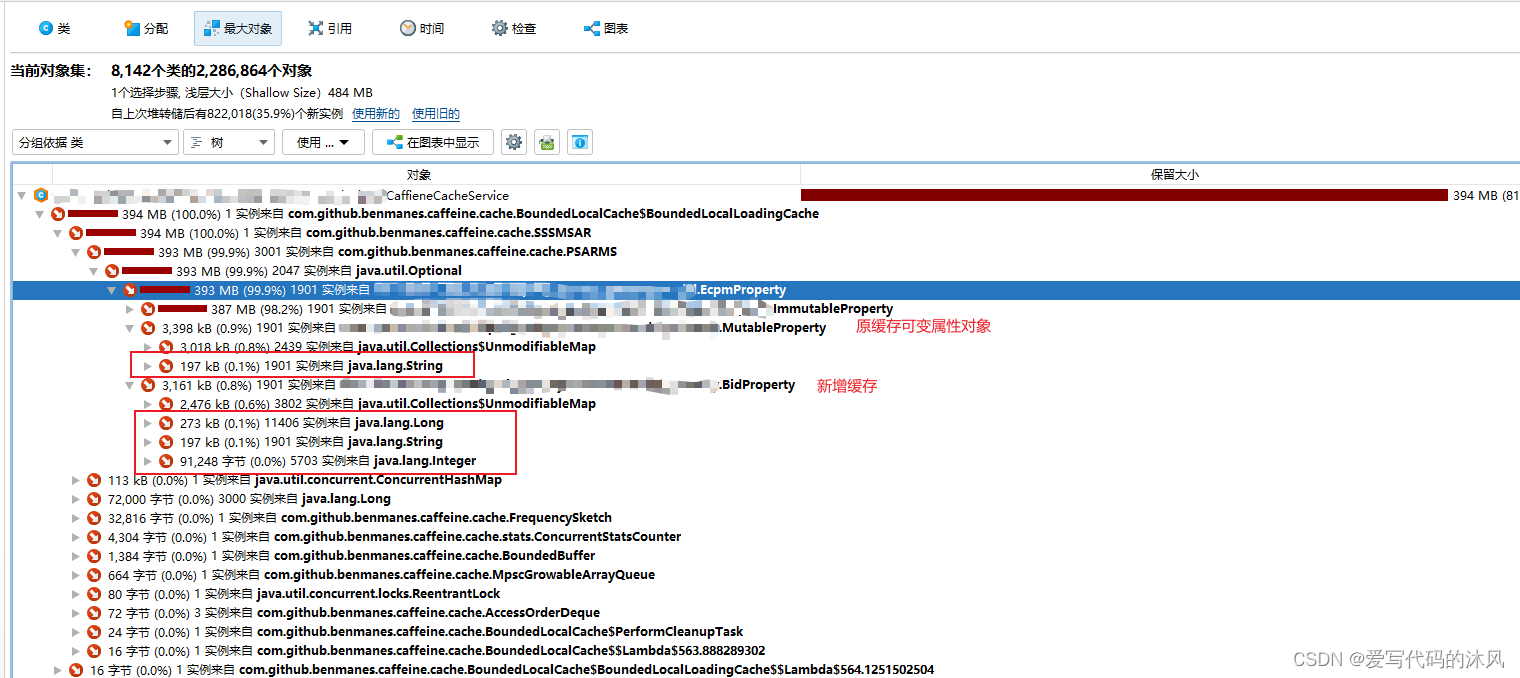
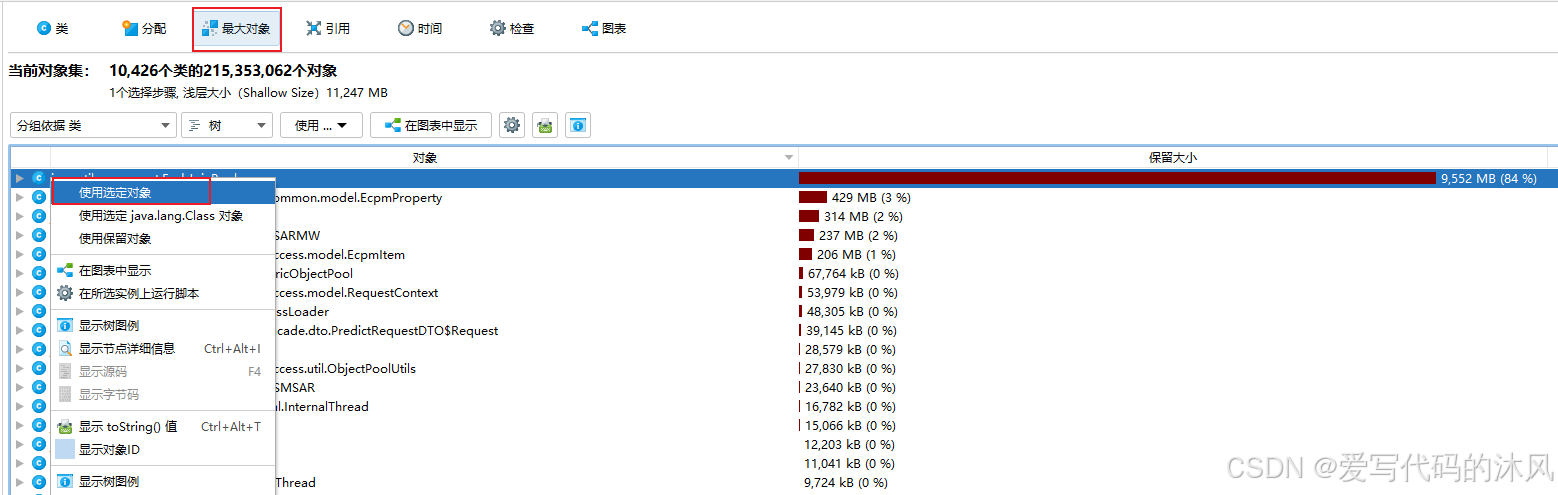
接着选中缓存对象,右键使用选定对象,查看对应的引用信息发现了问题所在
新加的缓存对象都是使用的包装类,原缓存使用的都是基本数据类型
在 Java 中,对于基本数据类型(如 double 和 boolean),它们在创建时不会生成对象。基本数据类型是直接存储在栈内存中的,它们的值直接存储在变量中,而不是存储在堆内存中的对象中。
因此,无论你创建多少个相同值的基本数据类型变量,它们实际上都指向相同的内存位置,因为基本数据类型不是对象,不会生成不同的实例。这意味着当你创建两个相同值的 double 或 boolean 变量时,它们实际上指向相同的内存位置,而不是两个不同的对象。
4.第二次优化
经过上次的优化,虽然GC的问题有所改善,但整体服务延迟和缓存加载耗时等问题仍未达到上线要求。在学习了其他博主在G1性能优化和Caffeine优化方面的经验后,结合当前项目的特性,我们进一步进行了优化。
优化点1: Caffeine异步缓存的使用
优势:
- 性能提升: 异步缓存能在后台处理缓存操作,不会阻塞主线程,从而提高系统的响应速度和性能。
- 并发处理: 异步缓存能更好地处理并发请求,多个请求可以同时触发缓存更新或加载操作,提高了系统的并发处理能力。
- 减少延迟: 通过异步缓存,可以在后台预加载或更新缓存数据,减少了对实时数据的依赖,降低了请求的延迟。
- 异步处理: 异步缓存可以在后台处理大量的缓存操作,例如批量加载、刷新等,提高了系统的整体效率。
劣势:
- 复杂性: 异步缓存会增加系统的复杂性,需要处理异步任务的调度、错误处理等,增加了代码的复杂度。
- 一致性问题: 异步缓存可能会导致缓存数据和数据库数据之间的一致性问题,需要额外的处理来保证数据的一致性。
- 调试困难: 异步缓存可能会导致调试和错误排查变得更加困难,需要更多的日志和监控来追踪异步操作的状态和结果。
优化点2: 调整JVM参数-XX:MaxGCPauseMillis=150
通过调整MaxGCPauseMillis参数,将G1垃圾收集器的最大停顿时间目标值设置为150毫秒,可以提高应用程序的响应性,减少用户感知到的延迟。然而,为了达到更短的停顿时间目标,G1垃圾收集器可能会更频繁地执行垃圾收集,从而导致更高的CPU使用率。鉴于当前系统的瓶颈主要在内存上,适度提升CPU使用率是可以接受的。
优化点3: 业务上优化了配置中心配置读取
之前的代码没有充分关注配置中心配置读取,考虑到配置中心在服务中具有缓存,我们没有意识到在循环中直接读取配置的影响。原本一次请求只需要读取一次的配置,在循环中需要被多次读取,导致系统整体耗时增加。
效果:
经过这几点优化后,系统的整体耗时和失败率甚至比之前还要低,猜测主要还是jvm调参的功劳。
5.后续
上线后发现了部分机器有OOM的问题,短时间内存会突然上涨一倍,触发fullGc,但是无法回收,最后机器被打挂掉。
使用Jprofiler分析了一下oom的堆栈
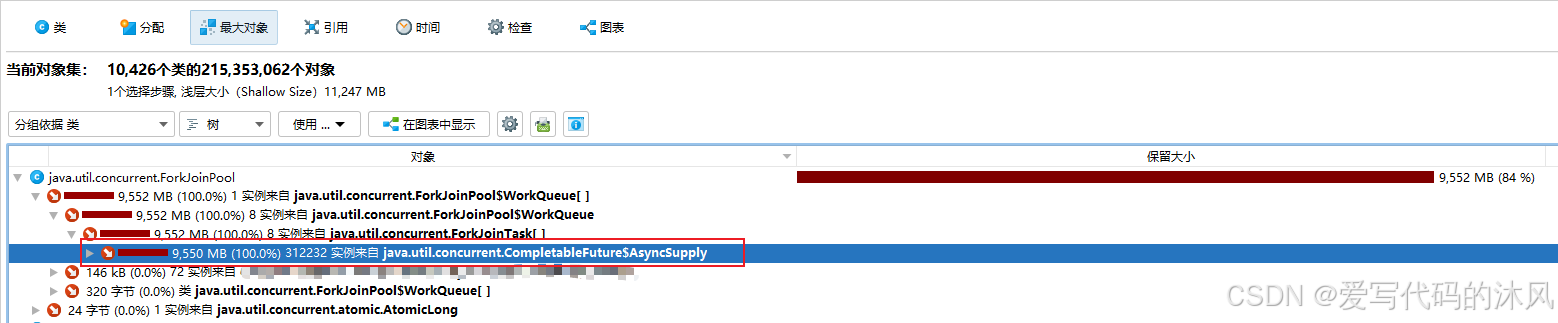

主要的内存占用在请求上下文,同时由CompletableFuture.supplyAsync创建的ForkJoinPool的实例拥有,问题应该是出在这里了。
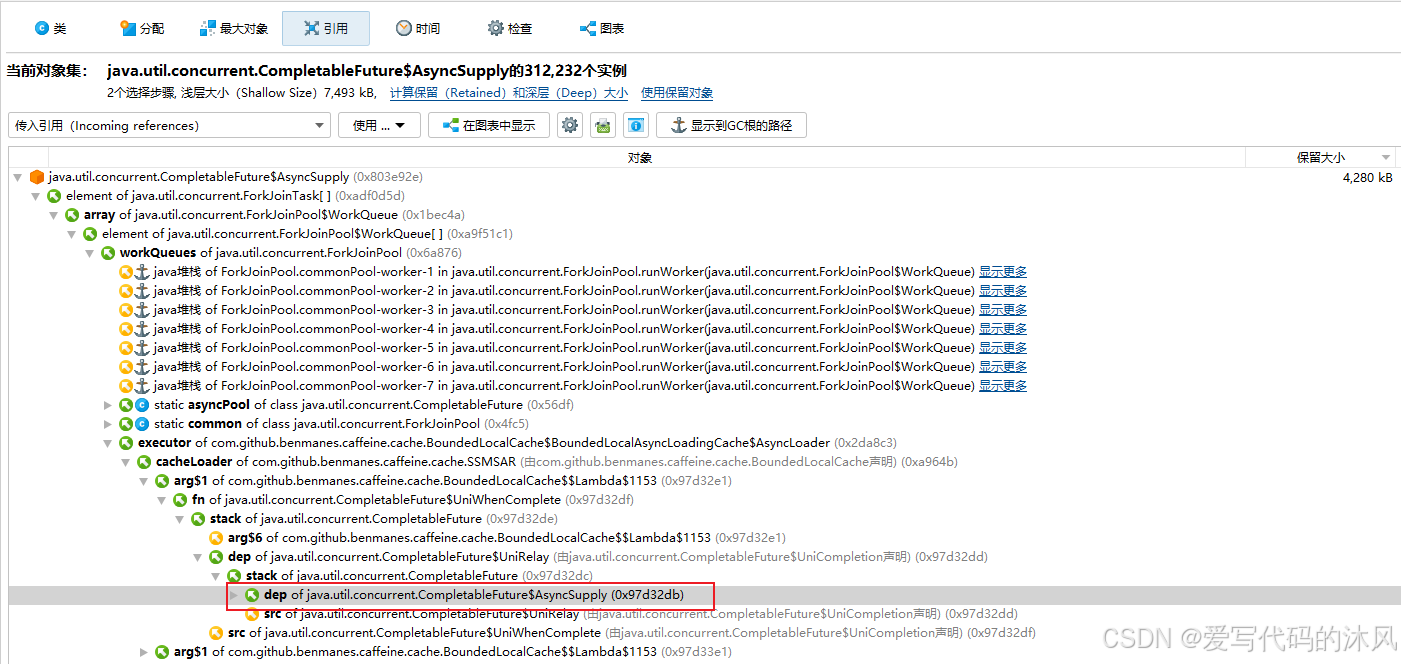
进而分析了这些实例的传入引用发现确实是有少量缓存使用了这个方法异步刷新数据,但是缓存并不持有请求上下文信息,即使大量阻塞也不会占用太多内存,所以继续向下多点了几个实例得引用信息发现了问题提所在。
绝大部分的ForkJoinPool实例都是由服务中的rta调用业务生成。查看了相关代码,发现这个业务使用了CompletableFuture.supplyAsync来异步指定代码,但是没有独立创建线程池,和caffiene共享一个ForkJoinPool线程池。因为rta调用比较耗时且携带的请求上下文中含有大对象,当服务请求量大的时候,缓存刷新任务大量存入ForkJoinPool的线程池中,导致rta的任务一直阻塞,大量请求的上下文一直无法被回收,导致一直fullGc,拖垮机器。
补充一个知识点:
caffiene可以自定义异步线程池,没有传入自定义的线程池时才会用默认的ForkJoinPool

Jprofiler使用技巧:
一般内存问题,可以先通过最大对象选项筛选出有问题的对象,然后右键这个对象,选用后就能在引用选项卡里查看对应的传入和传出引用。根据引用信息很容易就能分析出被大量持有无法被回收的原因,进而找到解决问题的方法。

















 2532
2532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









