







一、数据加载基本框架
package com.lzl.recommender
/**
* Product数据集
* 3982 商品ID
* Fuhlen 富勒 M8眩光舞者时尚节能 商品名称
* 1057,439,736 商品分类ID,不需要
* B009EJN4T2 亚马逊ID,不需要
* https://images-cn-4.ssl-image 商品的图片URL
* 外设产品|鼠标|电脑/办公 商品分类
* 富勒|鼠标|电子产品|好用|外观漂亮 商品UGC标签
*/
case class Product( productId: Int, name: String, imageUrl: String, categories: String, tags: String )
/**
* Rating数据集
* 4867 用户ID
* 457976 商品ID
* 5.0 评分
* 1395676800 时间戳
*/
case class Rating( userId: Int, productId: Int, score: Double, timestamp: Int )
/**
* MongoDB连接配置
* @param uri MongoDB的连接uri
* @param db 要操作的db
*/
case class MongoConfig( uri: String, db: String )
object DataLoader {
def main(args: Array[String]): Unit = {
// 创建一个spark config
val sparkConf = null
// 创建spark session
val spark = null
// 加载数据
val productRDD = null
val productDF = null
val ratingRDD = null
val ratingDF = null
spark.stop()
}
}二、代码编写
package com.lzl.recommender
import com.mongodb.casbah.Imports.MongoClientURI
import com.mongodb.casbah.MongoClient
import com.mongodb.casbah.commons.MongoDBObject
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* Product数据集
* 3982 商品ID
* Fuhlen 富勒 M8眩光舞者时尚节能 商品名称
* 1057,439,736 商品分类ID,不需要
* B009EJN4T2 亚马逊ID,不需要
* https://images-cn-4.ssl-image 商品的图片URL
* 外设产品|鼠标|电脑/办公 商品分类
* 富勒|鼠标|电子产品|好用|外观漂亮 商品UGC标签
*/
case class Product( productId: Int, name: String, imageUrl: String, categories: String, tags: String )
/**
* Rating数据集
* 4867 用户ID
* 457976 商品ID
* 5.0 评分
* 1395676800 时间戳
*/
case class Rating( userId: Int, productId: Int, score: Double, timestamp: Int )
/**
* MongoDB连接配置
* @param uri MongoDB的连接uri
* @param db 要操作的db
*/
case class MongoConfig( uri: String, db: String )
object DataLoader {
// 定义数据文件路径
val PRODUCT_DATA_PATH = "E:\\Java\\ECommerceRecommendSystem\\recommender\\DataLoader\\src\\main\\resources\\products.csv"
val RATING_DATA_PATH = "E:\\Java\\ECommerceRecommendSystem\\recommender\\DataLoader\\src\\main\\resources\\ratings.csv"
// 定义mongodb中存储的表名
val MONGODB_PRODUCT_COLLECTION = "Product"
val MONGODB_RATING_COLLECTION = "Rating"
// 主程序的入口
def main(args: Array[String]): Unit = {
// 定义用到的配置参数
val config = Map(
"spark.cores"->"local[*]",
"mongo.uri"->"mongodb://localhost:27017/recommender",
"mongo.db"->"recommender"
)
// 创建一个spark config
val sparkConf = new SparkConf().setAppName("DataLoader").setMaster(config("spark.cores"))
// 创建spark session
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
//引入包(在对DataFrame和Dataset进行操作许多操作都需要这个包进行支持)
import spark.implicits._
// 加载数据
//将Product、Rating数据集加载进来
val productRDD = spark.sparkContext.textFile(PRODUCT_DATA_PATH)
//将ProdcutRDD装换为DataFrame
val productDF = productRDD.map(item => {
val attr = item.split("\\^")
Product(attr(0).toInt, attr(1).trim, attr(4).trim, attr(5).trim, attr(6).trim)
}).toDF()
//同理,rating数据也转化为DataFrame
val ratingRDD = spark.sparkContext.textFile(RATING_DATA_PATH)
val ratingDF = ratingRDD.map(item => {
val attr = item.split(",")
Rating(attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt)
}).toDF()
// 声明一个隐式的配置对象
implicit val mongoConfig =
MongoConfig(config("mongo.uri"), config("mongo.db"))
// 将数据保存到MongoDB中
storeDataInMongoDB(productDF, ratingDF)
// 关闭Spark
spark.stop()
}
//隐士调用(implicit mongoConfig: MongoConfig)
def storeDataInMongoDB(productDF: DataFrame, ratingDF: DataFrame)(implicit mongoConfig: MongoConfig): Unit = {
//新建一个到MongoDB的连接
val mongoClient = MongoClient(MongoClientURI(mongoConfig.uri))
// 定义要操作的mongodb表,可以理解为 db.Product
val productCollection =mongoClient(mongoConfig.db)(MONGODB_PRODUCT_COLLECTION)
val ratingCollection = mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION)
//如果表已经存在,则删掉
productCollection.dropCollection()
ratingCollection.dropCollection()
//将当前的数据存入到mongoDB中对应表中
productDF.write
.option("uri",mongoConfig.uri)
.option("collection",MONGODB_PRODUCT_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
ratingDF.write
.option("uri",mongoConfig.uri)
.option("collection",MONGODB_RATING_COLLECTION)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
// 对表创建索引
productCollection.createIndex(MongoDBObject("productId"->1))
ratingCollection.createIndex(MongoDBObject("productId"->1))
ratingCollection.createIndex(MongoDBObject("userId"->1))
mongoClient.close()
}
}在window环境下安装mongodb,并开启mongoDB服务。
我们可以看到数据库只有原始3个:
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB启动idea程序,运行DataLoader类
发现mongodb多了一个库:
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
recommender 0.001GB
查询表和表内的数据:
> show tables
Product
Rating
> db.Product.find().count()
96
> db.Product.find().pretty()
{
"_id" : ObjectId("60a8e1fc1f34d81324327a4d"),
"productId" : 259637,
"name" : "小狗钱钱",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/51oNLo7MsmL._SY344_BO1,204,203,200_QL70_.jpg",
"categories" : "图书音像|少儿|少儿/教育图书",
"tags" : "书|少儿图书|教育类|童书|不错|孩子很喜欢"
}
{
"_id" : ObjectId("60a8e1fc1f34d81324327a56"),
"productId" : 260348,
"name" : "西尔斯亲密育儿百科(全球最权威最受欢迎的育儿百科最新定本)",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/41XLbU3%2B3lL._SY344_BO1,204,203,200_QL70_.jpg",
"categories" : "育儿/早教|生活类图书|图书音像",
"tags" : "书|育儿类|教育类|不错|内容丰富|西尔斯"
}
{
"_id" : ObjectId("60a8e1fc1f34d81324327a59"),
"productId" : 275707,
"name" : "猜猜我有多爱你",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/51OaoKgR8RL._SX258_BO1,204,203,200_QL70_.jpg",
"categories" : "图书音像|少儿|少儿/教育图书",
"tags" : "书|教育类|不错|内容丰富|少儿图书|好看"
}
{
"_id" : ObjectId("60a8e1fc1f34d81324327a5c"),
"productId" : 286997,
"name" : "千纤草黄瓜水500ml",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/31i7lIchHBL._SY300_QL70_.jpg",
"categories" : "面部护理|美妆个护|化妆水/爽肤水",
"tags" : "化妆品|面部护理|千纤草|到货速度快|用起来很舒服"
}
{
"_id" : ObjectId("60a8e1fc1f34d81324327a5e"),
"productId" : 294209,
"name" : "不畏将来 不念过去",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/51DbBJiAbOL._SY344_BO1,204,203,200_QL70_.jpg",
"categories" : "政治/军事|人文社科类图书|图书音像",
"tags" : "书|军事类|政治类|好看|有破损|内容不错"
}
{
"_id" : ObjectId("60a8e1fc1f34d81324327a60"),
"productId" : 300265,
"name" : "Edifier漫步者 H180 耳塞式耳机 白色(经典时尚)",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/41LUEX%2BDciL._SY300_QL70_.jpg",
"categories" : "外设产品|耳机/耳麦|电脑/办公",
"tags" : "耳机|耳塞式耳机|电子产品|漫步者|外观漂亮|质量好"
}
{
"_id" : ObjectId("60a8e1fc1f34d81324327a62"),
"productId" : 302217,
"name" : "Elizabeth Arden伊丽莎白雅顿绿茶香水50ml(进)(特卖)",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/41AAc8vsA5L._SY300_QL70_.jpg",
"categories" : "彩妆|香水|美妆个护",
"tags" : "化妆品|伊丽莎白|香水|好用|很香|到货速度快"
}
{
"_id" : ObjectId("60a8e1fc1f34d81324327a64"),
"productId" : 314081,
"name" : "时寒冰说:经济大棋局,我们怎么办",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/51DDJuy6zbL._SX258_BO1,204,203,200_QL70_.jpg",
"categories" : "政治/军事|人文社科类图书|图书音像",
"tags" : "书|军事类|政治类|时寒冰|经管类|扯淡|很有启发|好看"
}
{
"_id" : ObjectId("60a8e1fc1f34d81324327a66"),
"productId" : 323519,
"name" : "Rapoo 雷柏 1090光学鼠标(经典黑)(智能自动对码/1000DPI高精度光学引擎)",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/410NDN9q1EL._SY300_QL70_.jpg",
"categories" : "外设产品|鼠标|电脑/办公",
"tags" : "电子产品|鼠标|外设|质量好|雷柏|到货速度快|外观漂亮|好用"
}
{
"_id" : ObjectId("60a8e1fc1f34d81324327a68"),
"productId" : 326582,
"name" : "Mentholatum曼秀雷敦男士冰爽活炭洁面乳150ml (特卖)",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/41Jc24lBavL._SY300_QL70_.jpg",
"categories" : "男士护肤|美妆个护|男士洁面",
"tags" : "化妆品|男士|曼秀雷敦|好用|用起来很舒服|到货速度快"
}
{
"_id" : ObjectId("60a8e1fc1f34d81324327a6a"),
"productId" : 333125,
"name" : "素年锦时",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/41Pzfrt4ZVL._SY344_BO1,204,203,200_QL70_.jpg",
"categories" : "音像|图书音像|有声读物",
"tags" : "书|有声读物|青春文学|文学|小说|好看|狗血"
}
{
"_id" : ObjectId("60a8e1fc1f34d81324327a6c"),
"productId" : 352021,
"name" : "Lenovo 联想 A820T TD-SCDMA/GSM 双卡双待 3G手机(白色 移动定制) 四核1.2G处理器 800万像素",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/41GOej5rPUL._SX300_QL70_.jpg",
"categories" : "手机|手机通讯|手机/数码",
"tags" : "联想|手机|质量好|联想手机还不错|好用|待机时间长"
}
{
"_id" : ObjectId("60a8e1fc1f34d81324327a6e"),
"productId" : 353799,
"name" : "沉思录",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/41MA9JZAjPL._SY344_BO1,204,203,200_QL70_.jpg",
"categories" : "哲学/宗教|人文社科类图书|图书音像",
"tags" : "书|哲学类|励志|值得一读再读|总理推荐|很有启发"
}
{
"_id" : ObjectId("60a8e1fc1f34d81324327a70"),
"productId" : 365357,
"name" : "怀孕40周完美方案(升级畅销版)",
"imageUrl" : "https://images-cn-4.ssl-images-amazon.com/images/I/51NKwb2S-jL._SX258_BO1,204,203,200_QL70_.jpg",
"categories" : "孕产/胎教|生活类图书|图书音像",
"tags" : "书|育儿类|教育类|内容丰富|有破损|胎教类|到货速度快|孕妇必读"
}说明此前的数据已经按照我们的格式导入到mongodb中了。
三、离线推荐服务建设
3.1离线推荐服务
离线推荐服务是综合用户所有的历史数据,利用设定的离线统计算法和离线推荐算法周期性的进行结果统计与保存,计算的结果在一定时间周期内是固定不变的,变更的频率取决于算法调度的频率。
离线推荐服务主要计算一些可以预先进行统计和计算的指标,为实时计算和前端业务相应提供数据支撑。
离线推荐服务主要分为统计推荐、基于隐语义模型的协同过滤推荐以及基于内容和基于Item-CF的相似推荐。我们这一章主要介绍前两部分,基于内容和Item-CF的推荐在整体结构和实现上是类似的
3.2离线统计服务
3.2.1主体框架
package com.lzl.statistics
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import java.text.SimpleDateFormat
import java.util.Date
//定义Rating类
case class Rating(userId: Int, productId: Int, score: Double, timestamp: Int)
//定义MongoConfig连接
case class MongoConfig(uri:String, db:String)
object StatisticsRecommender {
//定义Mongodb中的表名
val MONGODB_RATING_COLLECTION= "Rating"
//定义统计的表的名称
val RATE_MORE_PRODUCTS="RateMoreProducts"
val RATE_MORE_RECENTLY_PRODUCTS="RateMoreRecentlyProducts"
val AVERAGE_PRODUCTS="AverageProducts"
//入口方法
def main(args: Array[String]): Unit = {
val config =Map(
"spark.cores"->"local[*]",
"mongo.uri"->"mongodb://localhost:27017/recommender",
"mongo.db"->"recommender"
)
//创建SparkConf配置
val sparkConf= new SparkConf().setMaster(config("spark.cores")).setAppName("StatisticsRecommender")
//创建SparkSession
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
//加入隐式转换
import spark.implicits._
implicit val mongoConfig =MongoConfig(config("mongo.uri"),config("mongo.db"))
//数据加载进来(从mongodb数据库读取数据)
val ratingDF = spark.read
.option("uri",mongoConfig.uri)
.option("collection",MONGODB_RATING_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[Rating]
.toDF()
//创建一张名叫ratings的临时表
ratingDF.createOrReplaceTempView("ratings")
//TODO: 不同的统计推荐结果(从这里开始连接统计方法)
//关闭程序
spark.stop()
}
}
3.2.2 历史热门商品统计
根据所有历史评分数据,计算历史评分次数最多的商品。
实现思路:
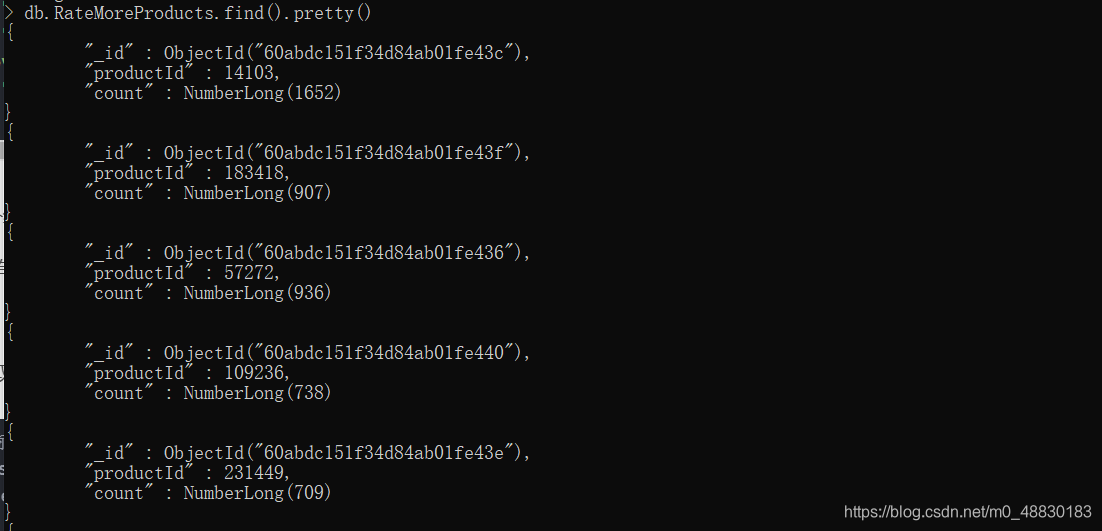
通过Spark SQL读取评分数据集,统计所有评分中评分数最多的商品,然后按照从大到小排序,将最终结果写入MongoDB的RateMoreProducts数据集中
//TODO: 不同的统计推荐结果(连接上面的框架)
//用spark sql去做不同的统计推荐
//1.历史热门商品,按照评分个数统计,数据结构 -> productId,count
val rateMoreProductsDF =spark.sql("select productId,count(productId) as count from ratings group by productId order by count desc")
//将查询的结果写进mongodb中
rateMoreProductsDF
.write
.option("uri",mongoConfig.uri)
.option("collection",RATE_MORE_PRODUCTS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()3.2.3 最近热门商品统计
根据评分,按月为单位计算最近时间的月份里面评分数最多的商品集合。
实现思路:
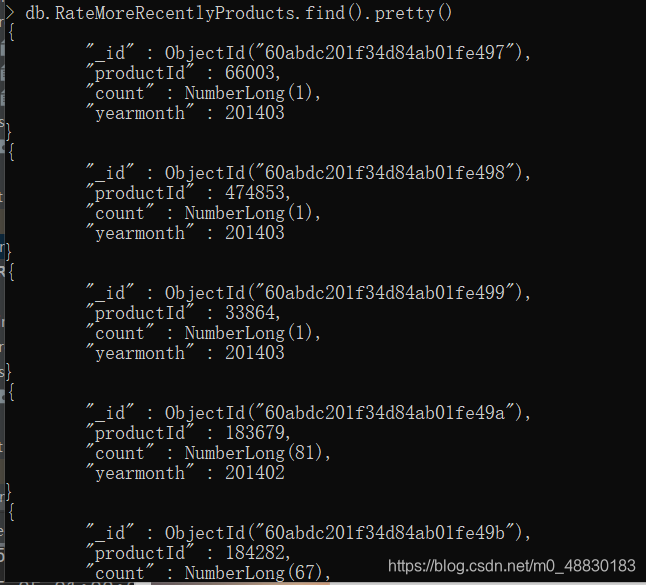
通过Spark SQL读取评分数据集,通过UDF函数将评分的数据时间修改为月,然后统计每月商品的评分数。统计完成之后将数据写入到MongoDB的RateMoreRecentlyProducts数据集中。
// 2. 近期热门商品,把时间戳转换成yyyyMM格式进行评分个数统计,最终得到productId, count, yearmonth
// 创建一个日期格式化工具
val simpleDateFormat = new SimpleDateFormat("yyyyMM")
//注册一个UDF函数,用于将timestamp装换成年月格式 1260759144000 => 201605
spark.udf.register("changeData",(x:Int) => simpleDateFormat.format(new Date(x*1000L)).toInt)
// 调用函数将原来的Rating数据集中的时间转换成年月的格式
val ratingOfYearMonth = spark.sql("select productId,score,changeData(timestamp) as yearmonth from ratings")
//将转化后的数据注册成为一张表,表名为:ratingOfMonth
ratingOfYearMonth.createOrReplaceTempView("ratingOfMonth")
//再从新表中用spark.sql读取不同的数据存入到mongodb中
val rateMoreRecentlyProducts = spark.sql("select productId,count(productId) as count,yearmonth from ratingOfMonth group by yearmonth,productId order by yearmonth desc,count desc")
rateMoreRecentlyProducts
.write
.option("uri",mongoConfig.uri)
.option("collection",RATE_MORE_RECENTLY_PRODUCTS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()3.2.4 商品平均得分统计
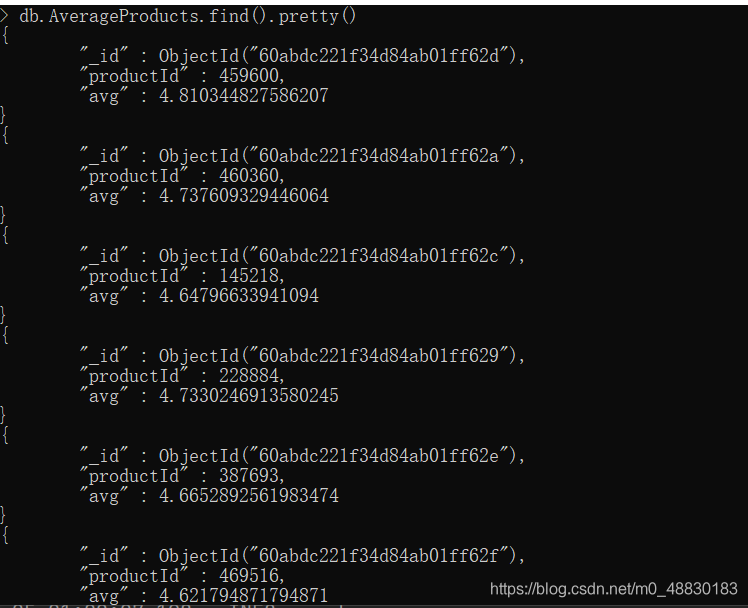
根据历史数据中所有用户对商品的评分,周期性的计算每个商品的平均得分。
实现思路:
通过Spark SQL读取保存在MongDB中的Rating数据集,通过执行以下SQL语句实现对于商品的平均分统计:
// 3.统计每个商品的平均评分
//用spark.sql读取数据
val averageProductsDF = spark.sql("select productId, avg(score) as avg from ratings group by productId order by avg desc")
//将数据存储与mongodb中
averageProductsDF
.write
.option("uri",mongoConfig.uri)
.option("collection",AVERAGE_PRODUCTS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()运型idea程序后,查询mongodb中的表的数据如下:
四、基于LFM的离线推荐模块(基于隐语义模型的协同过滤推荐)
项目采用ALS作为协同过滤算法,根据MongoDB中的用户评分表计算离线的用户商品推荐列表以及商品相似度矩阵。
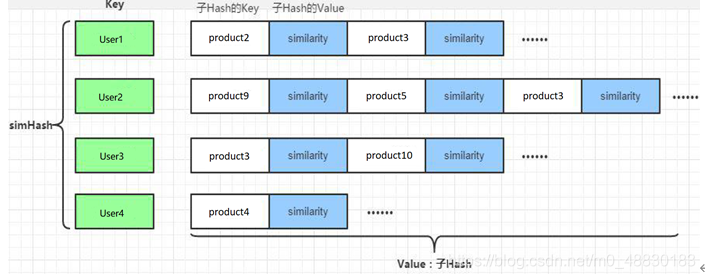
4.1用户商品推荐列表
通过ALS训练出来的Model来计算所有当前用户商品的推荐列表,主要思路如下:
1. userId和productId做笛卡尔积,产生(userId,productId)的元组
2. 通过模型预测(userId,productId)对应的评分。
3. 将预测结果通过预测分值进行排序。
4. 返回分值最大的K个商品,作为当前用户的推荐列表。
最后生成的数据结构如下:将数据保存到MongoDB的UserRecs表中
(1)代码实现如下:
package com.lzl.offline
import org.apache.spark.SparkConf
import org.apache.spark.mllib.recommendation.{ALS, Rating}
import org.apache.spark.sql.SparkSession
import org.jblas.DoubleMatrix
/**
* 基于LFM的离线推荐模块
*
* @param productId
* @param score
*/
case class ProductRating( userId: Int, productId: Int, score: Double, timestamp: Int )
case class MongoConfig( uri: String, db: String )
//定义标准的推荐对象(productId,score)
case class Recommendation(productId:Int,score:Double)
//定义用户的推荐列表(userId,recs)
case class UserRecs( userId: Int, recs: Seq[Recommendation] )
//定义商品相似度列表
case class ProductRecs(productId: Int, recs: Seq[Recommendation])
object OfflineRecommender {
//定义mongodb存储表名
val MONGODB_RATING_COLLECTION = "Rating"
//推荐表的名称
val USER_RECS = "UserRecs"
val PRODUCT_RECS = "ProductRecs"
val USER_MAX_RECOMMENDATION = 20
def main(args: Array[String]): Unit = {
//定义配置
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://localhost:27017/recommender",
"mongo.db" -> "recommender"
)
// 创建一个spark config
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("OfflineRecommender")
// 创建spark session
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
//加载数据,读取mongoDB中的业务数据
val ratingRDD = spark
.read
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[ProductRating]
.rdd
.map(
rating => (rating.userId, rating.productId, rating.score)
).cache()
//用户的数据集 RDD[Int](提取出所有用户和商品的数据集)
val userRDD = ratingRDD.map(_._1).distinct()
val productRDD = ratingRDD.map(_._2).distinct()
//TODO:核心计算过程
//1. 训练隐语义模型(创建训练数据集)
val trainData = ratingRDD.map(x=>Rating(x._1,x._2,x._3))
// 定义模型训练的参数,rank隐特征个数,iterations迭代词数,lambda正则化系数(rank是模型中隐语义因子的个数,iterations是迭代的次数, lambda是ALS的正则化参)
val (rank,iterations,lambda) = (5,10,0.01)
// 调用ALS算法训练隐语义模型
val model = ALS.train(trainData, rank, iterations, lambda)
//2. 获得预测评分矩阵,得到用户的推荐列表
// 用userRDD和productRDD做一个笛卡尔积,得到空的userProductsRDD表示的评分矩阵
val userProducts = userRDD.cartesian(productRDD)
// model已训练好,把id传进去就可以得到预测评分列表RDD[Rating] (userId,productId,rating)
val preRating = model.predict(userProducts)
// 从预测评分矩阵中提取得到用户推荐列表
val userRecs = preRating.filter(_.rating>0)
.map(
rating => (rating.user,(rating.product,rating.rating))
)
.groupByKey()
.map{
case (userId, recs) =>
UserRecs(userId,recs.toList.sortWith(_._2>_._2).take(USER_MAX_RECOMMENDATION).map(x=>Recommendation(x._1,x._2)))
}
.toDF()
userRecs.write
.option("uri", mongoConfig.uri)
.option("collection", USER_RECS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
//TODO:计算商品相似度矩阵
//3. 利用商品的特征向量,计算商品的相似度列表
val productFeatures = model.productFeatures.map{
case (productId, features) => ( productId, new DoubleMatrix(features) )
}
// 两两配对商品,计算余弦相似度
val productRecs = productFeatures.cartesian(productFeatures)
.filter{
case (a, b) => a._1 != b._1
}
// 计算余弦相似度
.map{
case (a, b) =>
val simScore = consinSim( a._2, b._2 )
( a._1, ( b._1, simScore ) )
}
.filter(_._2._2 > 0.4)
.groupByKey()
.map{
case (productId, recs) =>
ProductRecs( productId, recs.toList.sortWith(_._2>_._2).map(x=>Recommendation(x._1,x._2)) )
}
.toDF()
productRecs.write
.option("uri", mongoConfig.uri)
.option("collection", PRODUCT_RECS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
spark.close()
}
//计算两个商品之间的余弦相似度
def consinSim(product1: DoubleMatrix, product2: DoubleMatrix): Double ={
product1.dot(product2)/ ( product1.norm2() * product2.norm2() )
}
}(2)启动idea程序OfflineRecommender类,在mongodb的OfflineRecommender库查看:
//查看表,多了2张表:UserRecs、ProductRecs
> show tables
AverageProducts
Product
ProductRecs //多出这张表
RateMoreProducts
RateMoreRecentlyProducts
Rating
UserRecs //多出这张表
(3)查看表中信息:
> db.UserRecs.find().pretty()
{
"_id" : ObjectId("60afbccd92f212049073f2e4"),
"userId" : 175655,
"recs" : [
{
"productId" : 116405,
"score" : 5.660461421183866
},
{
"productId" : 203971,
"score" : 5.5004573565573684
},
{
"productId" : 13316,
"score" : 5.479760166077213
},
{
"productId" : 474201,
"score" : 5.472789044554331
},
{
"productId" : 353799,
"score" : 5.449200898485728
},
{
"productId" : 228884,
"score" : 5.346900717738464
},
{
"productId" : 75701,
"score" : 5.284602295140783
},
{
"productId" : 507644,
"score" : 5.244891493900729
},
{
"productId" : 183418,
"score" : 5.233466535949109
},
{
"productId" : 425715,
"score" : 5.220903081207561
},
{
"productId" : 457976,
"score" : 5.197529762862075
},
{
"productId" : 183679,
"score" : 5.169029330421441
},
{
"productId" : 204025,
"score" : 5.168269618476224
},
{
"productId" : 66003,
"score" : 5.165381149489736
},
{
"productId" : 333125,
"score" : 5.156595381765671
},
{
"productId" : 156103,
"score" : 5.090763877818269
},
{
"productId" : 102886,
"score" : 5.033073950059061
},
{
"productId" : 406697,
"score" : 5.005064354725313
},
{
"productId" : 206404,
"score" : 4.975564116457182
},
{
"productId" : 517740,
"score" : 4.966298981473621
}
]4.2、模型评估和参数选取
在上述模型训练的过程中,我们直接给定了隐语义模型的rank,iterations,lambda三个参数。对于我们的模型,这并不一定是最优的参数选取,所以我们需要对模型进行评估。
通常的做法是计算均方根误差(RMSE),考察预测评分与实际评分之间的误差。
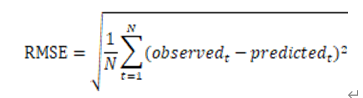
有了RMSE,我们可以就可以通过多次调整参数值,来选取RMSE最小的一组作为我们模型的优化选择。
代码编写如下:
kage com.lzl.offline
import breeze.numerics.sqrt
import com.lzl.offline.OfflineRecommender.MONGODB_RATING_COLLECTION
import org.apache.spark.SparkConf
import org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* ALS模型评估和参数选择
*/
object ALSTrainer {
def main(args: Array[String]): Unit = {
val config = Map(
"spark.cores" -> "local[*]",
"mongo.uri" -> "mongodb://localhost:27017/recommender",
"mongo.db" -> "recommender"
)
// 创建一个spark config
val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("OfflineRecommender")
// 创建spark session
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
import spark.implicits._
implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db"))
// 加载数据
val ratingRDD = spark.read
.option("uri", mongoConfig.uri)
.option("collection", MONGODB_RATING_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[ProductRating]
.rdd
.map(
rating => Rating(rating.userId, rating.productId, rating.score)
).cache()
// 数据集切分成训练集和测试集
val splits = ratingRDD.randomSplit(Array(0.8, 0.2))
val trainingRDD = splits(0)
val testingRDD = splits(1)
// 核心实现:输出最优参数
adjustALSParams( trainingRDD, testingRDD )
spark.stop()
}
def adjustALSParams(trainData: RDD[Rating], testData: RDD[Rating]): Unit ={
// 遍历数组中定义的参数取值
val result = for( rank <- Array(5, 10, 20, 50); lambda <- Array(1, 0.1, 0.01) )
yield {
val model = ALS.train(trainData, rank, 10, lambda)
val rmse = getRMSE( model, testData )
( rank, lambda, rmse )
}
// 按照rmse排序并输出最优参数
println(result.minBy(_._3))
}
def getRMSE(model: MatrixFactorizationModel, data: RDD[Rating]): Double = {
// 构建userProducts,得到预测评分矩阵
val userProducts = data.map( item=> (item.user, item.product) )
val predictRating = model.predict(userProducts)
// 按照公式计算rmse,首先把预测评分和实际评分表按照(userId, productId)做一个连接
val observed = data.map( item=> ( (item.user, item.product), item.rating ) )
val predict = predictRating.map( item=> ( (item.user, item.product), item.rating ) )
sqrt(
observed.join(predict).map{
case ( (userId, productId), (actual, pre) ) =>
val err = actual - pre
err * err
}.mean()
)
}
}
启动idea程序,ALSTrainer类,结果如下:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









