






本文是win11环境、JDK8;
一、ES8下载、安装、启动
1、es8安装和配置
去官网下载es8.5.3,地址:
官网:https://www.elastic.co/cn/downloads/elasticsearch
官网太慢,我已放到百度网盘:
百度:https://pan.baidu.com/s/1JGgaVYUUI4viR0v6_FfdVQ
提取码:elk8
2、下载完,解压即可
3、配置config下elasticsearch.yml文件:在文件最下面添加
# 换个集群的名字,免得跟别人的集群混在一起
cluster.name: my-es
# 换个节点名字
node.name: el_node
# 修改一下ES的监听地址,这样别的机器也可以访问
network.host: 0.0.0.0
http.host: 0.0.0.0
#设置对外服务的http端口,默认为9200
http.port: 9200
#设置索引数据的存储路径
path.data: M:/elk8.5.3/data/data #换成自己的路径
#设置日志文件的存储路径
path.logs: M:/elk8.5.3/data/logs #换成自己的路径
# 增加新的参数,head插件可以访问es
http.cors.enabled: true
http.cors.allow-origin: "*"
# 关闭http访问限制
xpack.security.enabled: false
xpack.security.enrollment.enabled: true
cluster.initial_master_nodes: ["el_node"] #注意,这个要与node.name填写一致
4、启动:双击bin文件里的elasticsearch.bat文件
二、logstash-8.5.3
将数据库的数据同步到ES里:
1、去官网下载es对应版本
2、解压
3、配置
config文件夹下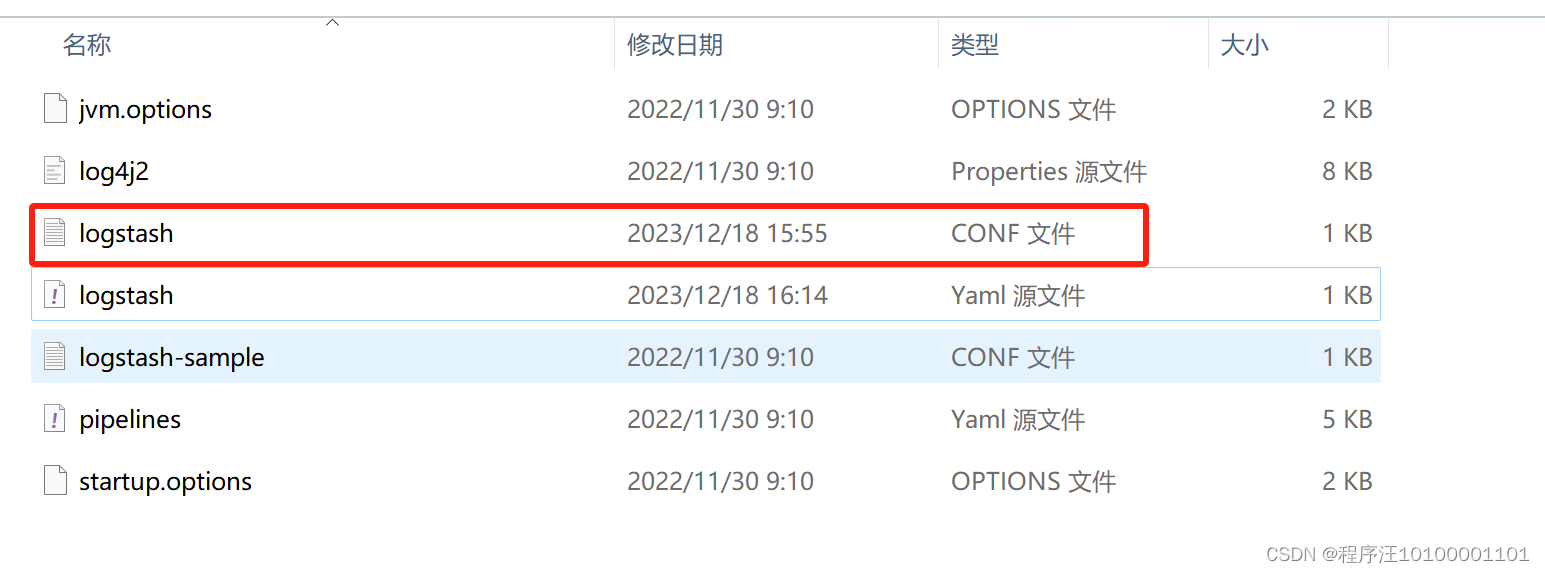
input {
stdin {
}
jdbc {
#数据库四大金刚配置
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=false&serverTimezone=UTC&rewriteBatchedStatements=true"
jdbc_user => "root"
jdbc_password => "123456"
#数据库驱动路径
jdbc_driver_library => "M:/mysql/mysql-connector-java/8.0.30/mysql-connector-java-8.0.30.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#这里可以指定sql文件或直接写SQL语句
statement => "SELECT * FROM user"
#定义每分钟去刷新数据库数据
schedule => "* * * * *"
type => "context"
}
}
filter {
}
output {
elasticsearch {
#输出至ES的端口
hosts => "localhost:9200"
#输出至ES的索引,索引名称可以动态设置,比如【aaa-2023-12-25】"[aaa]-%{+YYYY-MM-dd}"
index => "aaa-*"
#设置_id自增
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
4、启动:双击bin目录下logstash.bat,然后会通过定时任务自动根据文档id扫描、同步数据到ES
三、kibana8.5.3
1、去官网下载es对应版本
2、解压
3、配置kibana.yml文件
server.port: 5601
server.host: "127.0.0.1"
elasticsearch.hosts: ["http://localhost:9200"]
i18n.locale: "zh-CN"
4、双击bin目录下的kibana.bat
5、然后在浏览器输入:localhost:5601进行管理ES
6、查看数据是否自动导入到ES
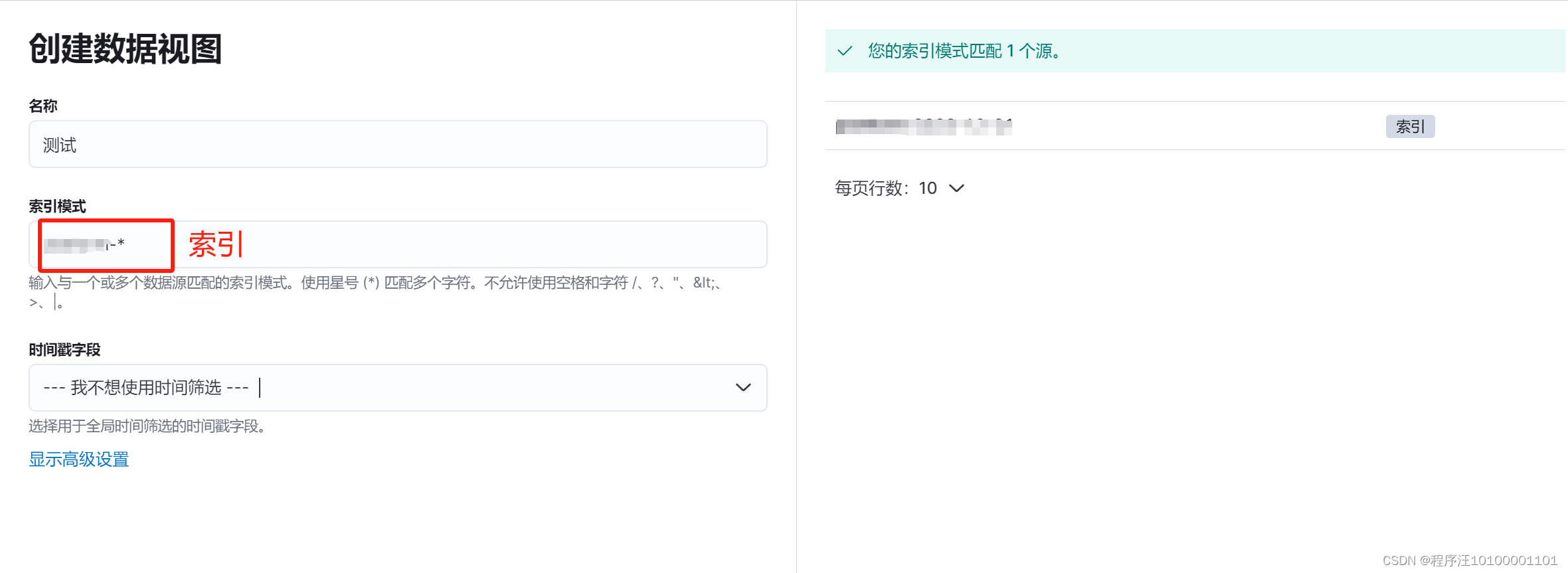
7、创建索引:aaa-*,以后用这个索引进行查询
8、关于分页报错:
因为es最大一次能查出2147483647条数据
PUT aaa-*/_settings
{
"index":{
"max_result_window": 2147483647
}
}
9、简单的分页查询
GET aaa-*/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"userName": {
"query": "aaa"
}
}
},
{
"match": {
"age": {
"query": 12
}
}
}
]
}
},
"from": 1,
"size": 10
}
10、日期区间查询
GET platform-*/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"time": {
"gte": "2023-12-01",
"lte": "2023-12-28",
"format": "yyyy-MM-dd'T'HH:mm:ss.SSSZ||yyyy-MM-dd||epoch_millis"
}
}
},
{
"match": {
"userName": "aaa"
}
}
]
}
},
"size": 0, # 返回结果,不返回列表hits
"track_total_hits": true # 解决不管查多少,最多返回10000的问题
}
四、Springboot集成ES-8.5.3
1、在pom.xml引入
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>8.5.3</version>
</dependency>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.5.3</version>
</dependency>
<dependency>
<groupId>jakarta.json</groupId>
<artifactId>jakarta.json-api</artifactId>
<version>2.1.1</version>
</dependency>
2、yml配置
elasticsearch:
#多个IP逗号隔开:集群时用到
#hosts: 127.0.0.1:9201,127.0.0.1:9202,127.0.0.1:9203
hosts: 127.0.0.1:9201
username:
password:
apikey:
# 本地配置
host: 127.0.0.1
port: 9200
3、编写ElasticSearchConfig
import co.elastic.clients.elasticsearch.ElasticsearchClient;
import co.elastic.clients.json.jackson.JacksonJsonpMapper;
import co.elastic.clients.transport.ElasticsearchTransport;
import co.elastic.clients.transport.rest_client.RestClientTransport;
import lombok.extern.slf4j.Slf4j;
import org.apache.http.Header;
import org.apache.http.HttpHeaders;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponseInterceptor;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.conn.ssl.NoopHostnameVerifier;
import org.apache.http.entity.ContentType;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.message.BasicHeader;
import org.apache.http.ssl.SSLContextBuilder;
import org.apache.http.ssl.SSLContexts;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.util.StringUtils;
import javax.net.ssl.SSLContext;
import java.io.IOException;
import java.io.InputStream;
import java.security.KeyManagementException;
import java.security.KeyStore;
import java.security.KeyStoreException;
import java.security.NoSuchAlgorithmException;
import java.security.cert.Certificate;
import java.security.cert.CertificateException;
import java.security.cert.CertificateFactory;
import java.util.stream.Stream;
import static java.util.stream.Collectors.toList;
@Configuration
@Slf4j
public class ElasticSearchConfig {
@Value("${elasticsearch.host}")
private String host;
@Value("${elasticsearch.port}")
private int port;
@Value("${elasticsearch.hosts}")
private String hosts;
@Value("${elasticsearch.username}")
private String username;
@Value("${elasticsearch.password}")
private String password;
@Value("${elasticsearch.apikey}")
private String apikey;
/**
* 单节点没密码连接
*
* @return
*/
@Bean
public ElasticsearchClient client() {
ElasticsearchTransport transport = null;
// 不是集群时
if (hosts.split(",").length == 1) {
// 无账号、密码
if (org.apache.commons.lang3.StringUtils.isEmpty(username) && org.apache.commons.lang3.StringUtils.isEmpty(password)) {
RestClient client = RestClient.builder(new HttpHost(host, port, "http")).build();
transport = new RestClientTransport(client, new JacksonJsonpMapper());
} else {
// 账号密码的配置
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
// 自签证书的设置,并且还包含了账号密码
RestClientBuilder.HttpClientConfigCallback callback = httpAsyncClientBuilder -> httpAsyncClientBuilder
.setSSLContext(buildSSLContext())
.setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE)
.setDefaultCredentialsProvider(credentialsProvider)
.setDefaultHeaders(
Stream.of(new BasicHeader(
HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON.toString())).collect(toList())
).addInterceptorLast(
(HttpResponseInterceptor)
(response, context) ->
response.addHeader("X-Elastic-Product", "Elasticsearch"));
RestClient client = RestClient.builder(new HttpHost(host, port, "http"))
.setHttpClientConfigCallback(callback)
.build();
transport = new RestClientTransport(client, new JacksonJsonpMapper());
}
} else {
// 无账号、密码
if (org.apache.commons.lang3.StringUtils.isEmpty(username) && org.apache.commons.lang3.StringUtils.isEmpty(password)) {
transport = getElasticsearchTransport(toHttpHost());
} else {
transport = getElasticsearchTransport(username, password, toHttpHost());
}
}
return new ElasticsearchClient(transport);
}
/**
* 多接点账号密码连接
*
* @return
*/
@Bean
public ElasticsearchClient clientByPwd() {
ElasticsearchTransport transport = null;
// 不是集群时
if (hosts.split(",").length == 1) {
// 无账号、密码
if (org.apache.commons.lang3.StringUtils.isEmpty(username) && org.apache.commons.lang3.StringUtils.isEmpty(password)) {
RestClient client = RestClient.builder(new HttpHost(host, port, "http")).build();
transport = new RestClientTransport(client, new JacksonJsonpMapper());
} else {
// 账号密码的配置
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
// 自签证书的设置,并且还包含了账号密码
RestClientBuilder.HttpClientConfigCallback callback = httpAsyncClientBuilder -> httpAsyncClientBuilder
.setSSLContext(buildSSLContext())
.setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE)
.setDefaultCredentialsProvider(credentialsProvider)
.setDefaultHeaders(
Stream.of(new BasicHeader(
HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON.toString())).collect(toList())
).addInterceptorLast(
(HttpResponseInterceptor)
(response, context) ->
response.addHeader("X-Elastic-Product", "Elasticsearch"));
RestClient client = RestClient.builder(new HttpHost(host, port, "http"))
.setHttpClientConfigCallback(callback)
.build();
transport = new RestClientTransport(client, new JacksonJsonpMapper());
}
} else {
// 无账号、密码
if (org.apache.commons.lang3.StringUtils.isEmpty(username) && org.apache.commons.lang3.StringUtils.isEmpty(password)) {
transport = getElasticsearchTransport(toHttpHost());
} else {
transport = getElasticsearchTransport(username, password, toHttpHost());
}
}
return new ElasticsearchClient(transport);
}
/**
* ESes自签证书连接
*
* @return
*/
@Bean
public ElasticsearchClient clientByApiKey() {
ElasticsearchTransport transport = null;
if (org.apache.commons.lang3.StringUtils.isNotEmpty(apikey)) {
transport = getElasticsearchTransport(apikey, toHttpHost());
}
return new ElasticsearchClient(transport);
}
private HttpHost[] toHttpHost() {
if (!StringUtils.hasLength(hosts)) {
throw new RuntimeException("invalid elasticsearch configuration");
}
String[] hostArray = hosts.split(",");
HttpHost[] httpHosts = new HttpHost[hostArray.length];
HttpHost httpHost;
for (int i = 0; i < hostArray.length; i++) {
String[] strings = hostArray[i].split(":");
httpHost = new HttpHost(strings[0], Integer.parseInt(strings[1]), "http");
httpHosts[i] = httpHost;
}
return httpHosts;
}
private static ElasticsearchTransport getElasticsearchTransport(String username, String password, HttpHost... hosts) {
// 账号密码的配置
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
// 自签证书的设置,并且还包含了账号密码
RestClientBuilder.HttpClientConfigCallback callback = httpAsyncClientBuilder -> httpAsyncClientBuilder
.setSSLContext(buildSSLContext())
.setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE)
.setDefaultCredentialsProvider(credentialsProvider)
.setDefaultHeaders(
Stream.of(new BasicHeader(
HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON.toString())).collect(toList())
).addInterceptorLast(
(HttpResponseInterceptor)
(response, context) ->
response.addHeader("X-Elastic-Product", "Elasticsearch"))
.addInterceptorLast((HttpResponseInterceptor) (response, context)
-> response.addHeader("X-Elastic-Product", "Elasticsearch"));
// 用builder创建RestClient对象
RestClient client = RestClient
.builder(hosts)
.setHttpClientConfigCallback(callback)
.build();
return new RestClientTransport(client, new JacksonJsonpMapper());
}
private static ElasticsearchTransport getElasticsearchTransport(HttpHost... hosts) {
// 用builder创建RestClient对象
RestClient client = RestClient
.builder(hosts)
.build();
return new RestClientTransport(client, new JacksonJsonpMapper());
}
private static SSLContext buildSSLContext() {
ClassPathResource resource = new ClassPathResource("es01.crt");
SSLContext sslContext = null;
try {
CertificateFactory factory = CertificateFactory.getInstance("X.509");
Certificate trustedCa;
try (InputStream is = resource.getInputStream()) {
trustedCa = factory.generateCertificate(is);
}
KeyStore trustStore = KeyStore.getInstance("pkcs12");
trustStore.load(null, null);
trustStore.setCertificateEntry("ca", trustedCa);
SSLContextBuilder sslContextBuilder = SSLContexts.custom().loadTrustMaterial(trustStore, null);
sslContext = sslContextBuilder.build();
} catch (CertificateException | IOException | KeyStoreException | NoSuchAlgorithmException |
KeyManagementException e) {
log.error("ES连接认证失败", e);
}
return sslContext;
}
private static ElasticsearchTransport getElasticsearchTransport(String apiKey, HttpHost... hosts) {
// 将ApiKey放入header中
Header[] headers = new Header[]{new BasicHeader("Authorization", "ApiKey " + apiKey)};
// es自签证书的设置
RestClientBuilder.HttpClientConfigCallback callback = httpAsyncClientBuilder -> httpAsyncClientBuilder
.setSSLContext(buildSSLContext())
.setSSLHostnameVerifier(NoopHostnameVerifier.INSTANCE)
.setDefaultHeaders(
Stream.of(new BasicHeader(
HttpHeaders.CONTENT_TYPE, ContentType.APPLICATION_JSON.toString())).collect(toList())
).addInterceptorLast(
(HttpResponseInterceptor)
(response, context) ->
response.addHeader("X-Elastic-Product", "Elasticsearch"));
// 用builder创建RestClient对象
RestClient client = RestClient
.builder(hosts)
.setHttpClientConfigCallback(callback)
.setDefaultHeaders(headers)
.build();
return new RestClientTransport(client, new JacksonJsonpMapper());
}
}
4、创建ESUtils工具类
import co.elastic.clients.elasticsearch._types.SortOrder;
import co.elastic.clients.elasticsearch.core.*;
import co.elastic.clients.elasticsearch.core.bulk.BulkOperation;
import co.elastic.clients.elasticsearch.indices.CreateIndexResponse;
import co.elastic.clients.elasticsearch.indices.DeleteIndexResponse;
import co.elastic.clients.elasticsearch.indices.GetIndexResponse;
import co.elastic.clients.transport.endpoints.BooleanResponse;
import org.apache.poi.ss.formula.functions.T;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.io.IOException;
import java.util.List;
import java.util.Map;
@Component
public class ESUtils {
@Autowired
private ElasticSearchConfig config;
/**
* 增加index
* @throws IOException
*/
public void createIndex(String index) throws IOException {
//写法比RestHighLevelClient更加简洁
CreateIndexResponse indexResponse = config.client().indices().create(c -> c.index(index));
}
/**
* 查询Index
* @throws IOException
*/
public GetIndexResponse queryIndex(String index) throws IOException {
GetIndexResponse getIndexResponse = config.client().indices().get(i -> i.index(index));
return getIndexResponse;
}
/**
* 判断index是否存在
* @return
* @throws IOException
*/
public boolean existsIndex(String index) throws IOException {
BooleanResponse booleanResponse = config.client().indices().exists(e -> e.index(index));
return booleanResponse.value();
}
/**
* 删除index
* @param index
* @return
* @throws IOException
*/
public DeleteIndexResponse deleteIndex(String index) throws IOException {
DeleteIndexResponse deleteIndexResponse = config.client().indices().delete(d -> d.index(index));
return deleteIndexResponse;
}
/**
* 插入数据
*/
public IndexResponse document(String index, String id, T t) throws IOException {
IndexResponse indexResponse = config.client().index(i -> i
.index(index)
//设置id
.id(id)
//传入user对象
.document(t));
return indexResponse;
}
/**
* 批量插入Document
*/
public BulkResponse documentAll(String index, List<BulkOperation> bulkOperationArrayList) throws IOException {
BulkResponse bulkResponse = config.client().bulk(b -> b.index(index)
.operations(bulkOperationArrayList));
return bulkResponse;
}
/**
* 更新Document
* @throws IOException
*/
public UpdateResponse updateDocumentIndex(String index, String id, T t) throws IOException {
UpdateResponse<T> updateResponse = config.client().update(u -> u
.index(index)
.id(id)
.doc(t)
, T.class);
return updateResponse;
}
/**
* 判断Document是否存在
* @throws IOException
*/
public BooleanResponse existDocumentIndex(String index) throws IOException {
BooleanResponse indexResponse = config.client().exists(e -> e.index(index).id("1"));
return indexResponse;
}
/**
* 查询Document
* @throws IOException
*/
public GetResponse getDocumentIndex(String index, String id, T t) throws IOException {
GetResponse<T> getResponse = config.client().get(g -> g
.index(index)
.id(id)
, T.class
);
return getResponse;
}
/**
* 分页查询[精确查找]
* @param index
* @param map
* @return
* @throws IOException
*/
public SearchResponse<T> searchPage(String index, Map<String, Object> map) throws IOException {
SearchResponse<T> search = config.client().search(s -> s
.index(index)
//查询name字段包含hello的document(不使用分词器精确查找)
.query(q -> q
.term(e -> e
.field(map.get("key").toString())
.value(v -> v.stringValue(map.get("value").toString()))
))
.trackTotalHits(new TrackHits.Builder().enabled(true).build())
//分页查询
.from((Integer) map.get("pageNum"))
.size((Integer) map.get("pageSize"))
//按age降序排序
.sort(f->f.field(o->o.field("createDate").order(SortOrder.Desc))),T.class
);
return search;
}
/**
* 删除Document
* @throws IOException
*/
public DeleteResponse deleteDocumentIndex(String index, String id) throws IOException {
DeleteResponse deleteResponse = config.client().delete(d -> d
.index(index)
.id(id)
);
return deleteResponse;
}
}
5、实战:
- 新增
User user = new User();
user.setUserName("aaa");
user.setAge(12);
String data = JSON.toJSONString(user);
esUtil.addDocument("aaa-*", data);
- 批量新增
List<User > datas = new ArrayList<>();
User user = new User();
user.setUserName("aaa");
user.setAge(12);
datas.add(user);
if (CollectionUtils.isNotEmpty(datas)) {
if (!esUtil.existsIndex("aaa-*")) {
esUtil.createIndex("aaa-*");
}
List<BulkOperation> bulkOperationArrayList = new ArrayList<>();
//遍历添加到bulk中
for (User obj : datas) {
bulkOperationArrayList.add(BulkOperation.of(o -> o.index(i -> i.document(obj))));
}
esUtil.documentAll("aaa-*", bulkOperationArrayList);
}
-
删除
-
批量删除
List<Query> queryList = new ArrayList<>();
Query queryTime = MatchQuery.of(m -> m.field("age").query(12))._toQuery();
queryList.add(queryTime);
Query queryAppId = MatchQuery.of(m -> m.field("userName.keyword").query("aaa"))._toQuery();
queryList.add(queryAppId);
SearchResponse<User> search = config.client().search(builder ->
builder.index("aaa-*")
.query(q -> q.bool(b -> b.must(queryList)))
.trackTotalHits(new TrackHits.Builder().enabled(true).build())
,User.class);
List<BulkOperation> list = new ArrayList<>();
List<Hit<User>> hitList = search.hits().hits();
for (Hit<User> hit : hitList) {
list.add(new BulkOperation.Builder().delete(d-> d.index(hit.index()).id(hit.id())).build());
}
config.client().bulk(e->e.index("aaa-*").operations(list));
- 修改
- 查询
List<Query> queryList = new ArrayList<>();
Query queryTime = MatchQuery.of(m -> m.field("age").query(12))._toQuery();
queryList.add(queryTime);
Query queryAppId = MatchQuery.of(m -> m.field("userName.keyword").query("aaa"))._toQuery();
queryList.add(queryAppId);
SearchResponse<User> search = config.client().search(builder ->
builder.index("aaa-*")
.query(q -> q.bool(b -> b.must(queryList)))
.trackTotalHits(new TrackHits.Builder().enabled(true).build())
,User.class);
List<Hit<User>> hitList = search.hits().hits();
- 分页查询
Integer pageNum = 1;
Integer pageSize = 10;
// 动态组装查询条件
List<Query> queryList = new ArrayList<>();
Query queryTime = MatchQuery.of(m -> m.field("age").query(12))._toQuery();
queryList.add(queryTime);
Query queryAppId = MatchQuery.of(m -> m.field("userName.keyword").query("aaa"))._toQuery();
queryList.add(queryAppId);
// 分页查询
SearchResponse<User> search = config.client().search(builder ->
builder.index("aaa-*")
.query(q -> q.bool(b -> b.must(queryList)))
.from((pageNum - 1) * pageSize)
.trackTotalHits(new TrackHits.Builder().enabled(true).build())
.size(pageSize),User.class);
List<Hit<User>> hitList = search.hits().hits();
List<User> list = new ArrayList<>();
for (Hit<User> hit : hitList) {
list.add(hit.source());
}
12、聚合查询
也就是mysql里的group by语句
SELECT
time,
userId,
age,
count( DISTINCT userId ) AS userIdCount ,
count( 1 ) AS count,
count(time) as timeCount,
(CAST(IFNULL(ROUND(SUM(timeLong) / count(userId), 2), 0) as DECIMAL(10,2))) AS avgTime
FROM
user
where 1=1
<if test="time != null and time != ''"> and time = #{time}</if>
<if test="userId!= null"> and userId= #{userId}</if>
GROUP BY
time,userId,age
java实现:
List<Query> queryList = new ArrayList<>();
if (StringUtils.isNotEmpty(time)) {
Query queryTime = MatchQuery.of(m -> m.field("time").query(time))._toQuery();
queryList.add(queryTime);
}
if (StringUtils.isNotEmpty(userId)) {
Query queryUserId = MatchQuery.of(m -> m.field("userId").query(userId))._toQuery();
queryList.add(queryUserId);
}
SearchRequest searchRequest = new SearchRequest.Builder()
//0:结果不返回列表,只返回结果
.size(0)
.index("aaa-*")
.query(q -> q.bool(b -> b.must(queryList)))
.aggregations("userId_aggs", userIdAgg ->
userIdAgg.terms(aterm -> aterm.field("userId.keyword")
//分组查询时,显示10000个,默认只查出10个
.size(10000))
.aggregations("age_aggs", ageAgg ->
ageAgg.terms(oterm -> oterm.field("age.keyword")
//分组查询时,显示10000个,默认只查出10个
.size(10000))
.aggregations("avgTime", avgsum ->
avgsum.sum(sum -> sum.field("timeLong")))
.aggregations("userIdCount", cardagg ->
cardagg.cardinality(car -> car.field("userId.keyword")))
.aggregations("count", useragg ->
useragg.valueCount(u -> u.field("userId.keyword")))
.aggregations("timeCount", csagg ->
csagg.valueCount(u -> u.field("time")))
)
)
).build();


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









