







 本文详细讲解了文法的基本概念,并通过词法分析和保留字检查函数,展示了自动机如何判断代码符合正规集。介绍了确定有限自动机(DFA)和非确定有限自动机(NFA),以及两者之间的转化过程,以实际例子演示如何在编译器中应用。
本文详细讲解了文法的基本概念,并通过词法分析和保留字检查函数,展示了自动机如何判断代码符合正规集。介绍了确定有限自动机(DFA)和非确定有限自动机(NFA),以及两者之间的转化过程,以实际例子演示如何在编译器中应用。
在上一章节中简单谈了文法,那自动机又是个啥呢?
说实话,刚开始看到这个名词时,总感觉这是一个很高级的东西,就感觉这是一个很牛逼的装置。
后来才发现,尼玛就是一个方法而已,这个方法可以判断代码中的字符或语句是否满足对应的正规集。
打个比方,词法分析中把保留字的正规式定义为A -> if | else | while,那么你总得写个函数来校验某个字符是否是保留字。
/**
* @param str to be checked from code.
* @param regex is the expression for checking the assigned str.
* @return true express checked successully, otherwise return false.
*/
fun check(str: String): Boolean {
val validWords = "if | else | while".split("|")
for(word in validWords) {
if(word == str) {
return true
}
}
return false
}
那么形如这样的函数就可以称为自动机,所以自动机通俗解释,就是自动识别某个符号或语法是否满足某个正规集。
根据上面的解释来看,自动机与正规集是一一对应的,而正规集是由正规式产生的,所以正规式与自动机也是一一对应的(未验证)。
比如上面保留字的正规式,可以画出一个自动机。
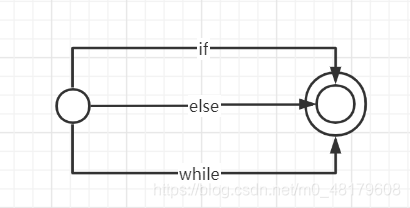
它表示从左边的开始状态到右边结束态只有if/else/while三种串。
这是比较简单的自动机,我们再举个复杂的粟子。
比如说变量一般是字母或字母+<单纯数字或单纯字母或数字与字母的组合>,如abc,abc123,abc123def,那么就可以先画一个自动机。
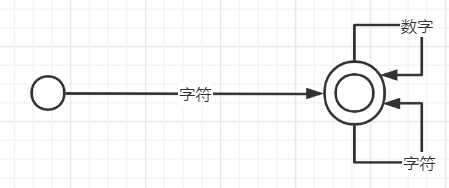
那么这个自动机上的路径就是它能识别出来的字符,比如我:
输入a,它是一个字符,所以能到达终点,状态机能识别;
输入123,它是一个数字,所以不能到达终点,状态机不能识别;
输入abc123,前半部分abc就可以到终点,123可以理解为终点上的追加(数字),所以能识别。
输入a1b2c3,a可以到终点,1b2c3是对a这个终点上的追加。
如果写成正规式,可以写成:
A -> 字符|(数字|字符)*
像上面这种输入一个相同的条件只会到达一个目标点的结构,称为确定的有限自动机,英名叫DFA(Deterministic Finite Automata)。
如果相同条件到达不同目标点(同个起点出发,相同文字对应的箭头指向的圆圈),又叫什么呢?
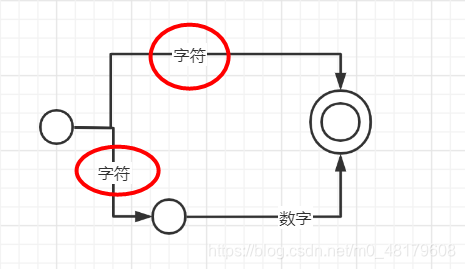
那就叫不确定的有限自动机,名字取得也很直接,就是目标点不确定嘛,英名叫NFA(Nondeterministic Finite Automata)。
其实我认为NFA才是人脑中对于规则的第一反应。比如说我们定义一个字符中的输入规则:
1、首字母为@,结尾也为@,中间无任何字符
2、@和@中间只能为一个数字。
那么下面这种格式无疑是满足要求的:
@@,@1@
针对这种情况我们大脑中第一想到的自动机如下图所示。
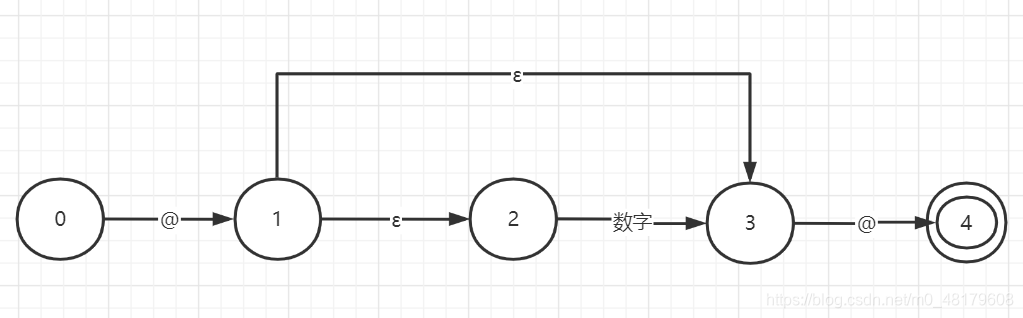
其中ε可以理解为分支,上面分支表示@@,下面分析适配@1@。
那么带有分支的NFA可以转化为下面的DFA。
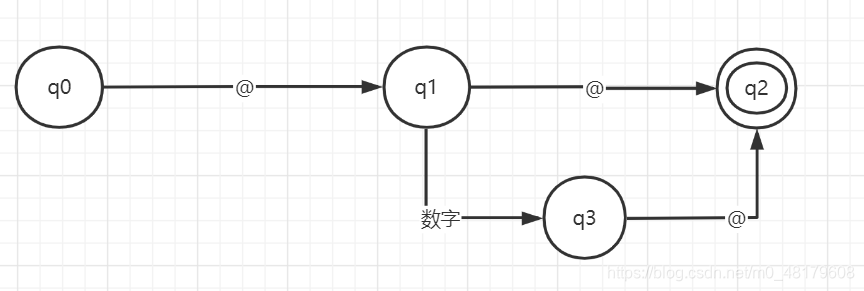
至于转换方式可以这样:
ε_CLOSURE({0}) = {0}记为q0
ε_CLOSURE(q0,@) = {1,2,3},记为q1,ε_CLOSURE(q0,数字) = {}。标记q0。 ε_CLOSURE(q1,@) =
{4},记为q2(终态); ε_CLOSURE(q1,数字) = {2,3},记为q3。标记q1。 ε_CLOSURE(q2,@) =
{};ε_CLOSURE(q2,数字) = {},标记q2。 ε_CLOSURE(q3,@) = {4},即q2。
ε_CLOSURE(q3,数字) = {2,3},即q3。
其中ε_CLOSURE({0})就表示经过从0点出发经过ε所到达的所有点的集合,包括0点。
因为0点没有经过ε的出口,所以ε_CLOSURE({0})只有一个0点,即ε_CLOSURE({0}) = {0};
上面q0、q1等为集合,那ε_CLOSURE(q0,@) 为什么是{1,2,3}呢?
ε_CLOSURE(q0,@) = ε_CLOSURE(T(q0,@))
而T(q0,@)为q0上每个点经过@所到达的点的集合,为{1},那么1经过ε可以到达2和3,所以结果为{1,2,3}(加上起始点1)。
关于具体流程大家可以看教材中说明,这里仅作补充。
将NFA转换成DFA进行最小化处理,然后根据这个最小化的DFA来指导写编译器中的校验代码。


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











