







简单说两句
最近看到教材第二章关于汇编的内容,说实话,头皮发麻,主要还是自己非计算机出身,并且一上来学的就是java,反正这么多年看到汇编两个字都是绕着走,更别说汇编原理了。
还记得当年在大学的时候有本选修课发的这玩意儿。

完全是不敢翻的那种。。。
**基础不牢,地动山摇。**想再系统性地学习一番,时间上也来不及,但是教程上对汇编程序这一节只有寥寥几百个字,什么符号表、指令表、记忆码、助记符、LC、POT1、两次扫描,看完完全不知道说的啥,只能脑补了。
没办法,只能借助百度慢慢啃,理解多少是多少,尽管考试内容占得不多,但多了解也是极好的。
第一次扫描
大概意思是,程序中有一些符号使用在前,定义在后。
在高级语言比如java中, 我们可以写出这样的代码:
class A {
void getValue() {
return value;
}
int value = 0;
}
所以说只有把整个代码扫描完,才知道value是什么。
那么在汇编语言中,也可以这样理解吗?

有点懵。
网上随便找了个汇编语句。
Mov AX [BX]
听说这样可以把BX所指向的内容写到AX中,那么BX可以在后面定义?

但不管怎样,标号的确是可以上面使用,在下面定义。比如标号S_T中,使用了下面才定义的C_S。

所以以目前的认知,我姑且认为,扫描第一遍就是把标号全部统计出来,然后形成类似这样一张表:
| 符号 | 偏移地址 |
|---|---|
| C_S | 1 |
| S_T | 2 |
| P_S | 3 |
至于偏移地址怎么得到的,就是根据一个计数器LC,当扫描到机器指令或者伪指令时就把LC+1,那么LC的值就可以标记机器指令或标号的位置。
其实教材中也让描述了第一次扫描的步骤:

可以看出,的确只是把标号记到符号表中了(存疑)。
除了填表以外,第一次扫描还执行了伪指令(分配存储单元、赋值等)。
最后我们结局一张图总结下,即利用上述步骤来扫描一个简单的汇编代码。

第二次扫描
教材里说了,第二次扫描是为了产生目标程序,汇编的目标程序无非就是一坨0和1,即:
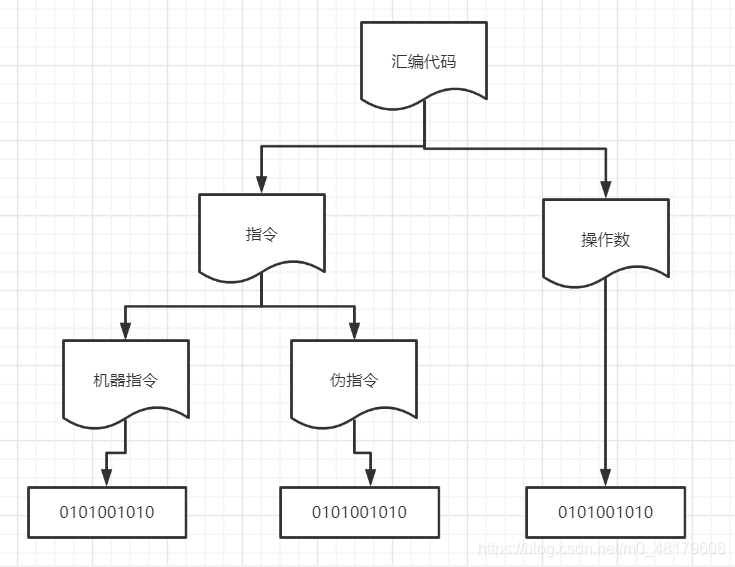
也就是说只要能建议字符(指令、操作数等)到机器码的映射就可以了。
1. 机器指令 -> 01
根据一个叫MOT2的表:
| 助记符 | 机器指令二进制 | 格式 | 长度 |
|---|---|---|---|
| MOV | 01xx | ||
| … | xxx |
2. 伪指令 -> 01
根据一个叫POT2的表:
|助记符 | 机器指令二进制| 格式 | 长度 |
| 伪指令记忆码 | 子程序入口 |
|---|---|
| ORG | 01xx |
| … | xxxx |
3. 操作数到 -> 01
这块内容书上没写,但我感觉与第一次扫描后拿到的符号表ST有关,如果说,第一次扫描记录了标号的偏移量,在第二次扫描执行伪指令时再根据这个偏移量分配内存,是不是有可能呢?
教材中不也说了嘛,第二次扫描伪指令有关完全不同的处理(存疑)。

剩下几个问题
- 两次扫描使用的MOT和POT表为什么不一样,都只有一张表不可以吗?
- 第一次扫描应该会对语句进行初步处理,如空格等,具体在哪儿处理的呢?没看见啊。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











