







 论文提出Vision Mamba(Vim),一种结合双向SSM进行全局视觉上下文建模,并使用位置嵌入进行位置感知的视觉表示学习方法。Vim在图像分类、语义分割、目标检测等任务上超越了优化的Transformer模型,如DeiT,同时在计算和内存效率上有显著提升,尤其在处理高分辨率图像时。Vim的提出旨在克服纯SSM在视觉任务中的挑战,有望成为下一代视觉基础模型的骨干网络。
论文提出Vision Mamba(Vim),一种结合双向SSM进行全局视觉上下文建模,并使用位置嵌入进行位置感知的视觉表示学习方法。Vim在图像分类、语义分割、目标检测等任务上超越了优化的Transformer模型,如DeiT,同时在计算和内存效率上有显著提升,尤其在处理高分辨率图像时。Vim的提出旨在克服纯SSM在视觉任务中的挑战,有望成为下一代视觉基础模型的骨干网络。
文章目录
摘要
https://arxiv.org/pdf/2401.09417v1.pdf
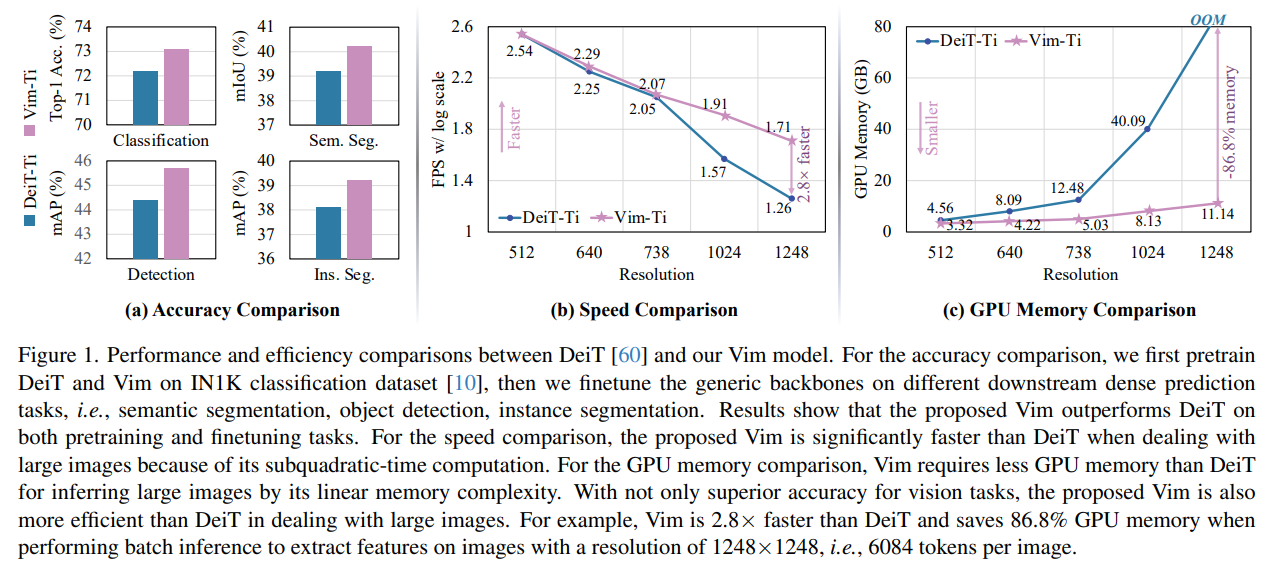
最近,具有高效硬件感知设计的状态空间模型(SSMs),例如Mamba,在长序列建模方面展现出了巨大潜力。纯粹基于SSMs构建高效和通用的视觉骨干网络是一个吸引人的方向。然而,由于视觉数据的空间敏感性和视觉理解的全局上下文需求,用SSMs表示视觉数据是一项挑战。本文表明,视觉表示学习对自注意力的依赖不是必需的,并提出了一个新的通用视觉骨干网络,该网络使用双向Mamba块(Vim),通过位置嵌入标记图像序列,并使用双向状态空间模型压缩视觉表示。在ImageNet分类、COCO目标检测和ADE20k语义分割任务上,Vim与DeiT等完善的视觉变换器相比性能更高,同时还显著提高了计算和内存效率。例如,Vim比DeiT快2.8倍,在执行批量推理以提取分辨率为1248×1248的图像特征时节省了86.8%的GPU内存。结果表明,Vim能够克服在执行高分辨率图像的Transformer风格理解时的计算和内存限制,并且有潜力成为下一代视觉基础模型的骨干网络。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











