









开始了
第一章 数据库基本概念
数据库(DataBase,简称DB ) : 用于存储和管理数据的仓库
数据库的特点
- 持久化存储数据. 数据库其实就是一个文件系统
- 可以方便存储和管理数据
- 使用了统一的方式来操作数据库 --SQL
常见的数据库软件
-
MYSQL: 开源免费的数据库,小型的数据库,已经被收购,从MYSQL 6.x版本开始也要收费
-
Oracle: 收费的大型数据库, Oracle公司的产品,收购MYSQL(要钱,30w)
-
DB2: IBM公司的数据库产品,收费. 常见在银行系统之中
-
SQLServer: 微软公司收费的中型数据库, c#, .net语言常用(要钱,3w)
-
SyBase: 已经淡出历史舞台,
-
SQLite: 嵌入式的效性数据库,应用在手机端
-
常用的数据库: MYSQL, Oracle
在web应用中,使用最多的就是MySQL数据库,原因如下
- 开源,免费
- 功能足够强大,足以应付web应用开发(最高支持千万级别的并发访问)
第二章 MySQL数据库软件
安装和卸载那些就不多说了
2.1 相关操作
MySQL的服务(服务就是没有页面的程序)
在cmd页面使用services.msc就打开windows系统的服务的页面,里面我们可以找到我们的mysql服务
-
net stop 服务名: 来停止服务(注意,cmd用管理员身份运行) -
netstart 服务名: 开启服务 -
当然,都可以通过鼠标来完成
2.2 MySQL的登录的登出
登录
在cmd页面下,我们使用管理员身份登录
mysql -uroot -proot
也可以
mysql -uroot -p
//然后输入密码
****
可以用全称
mysql --host=127.0.0.1 --user=root --password=root
我想在别人的电脑登录我的MySQL(前提是我的MYSQL设置了允许别人访问我的数据库这个设置)
mysql -h目标电脑的IP地址 -uroot -p目标电脑设的MySQL的密码
退出
在cmd页面下,我们通过关闭页面或者输入exit来退出服务
2.3 MySQL目录结构
MySQL的安装目录
安装目录就是在你安装MySQL的时候的目录
MySQL的数据目录
在C:\ProgramData\MySQL\MySQL Server 5.5\data
数据的结构
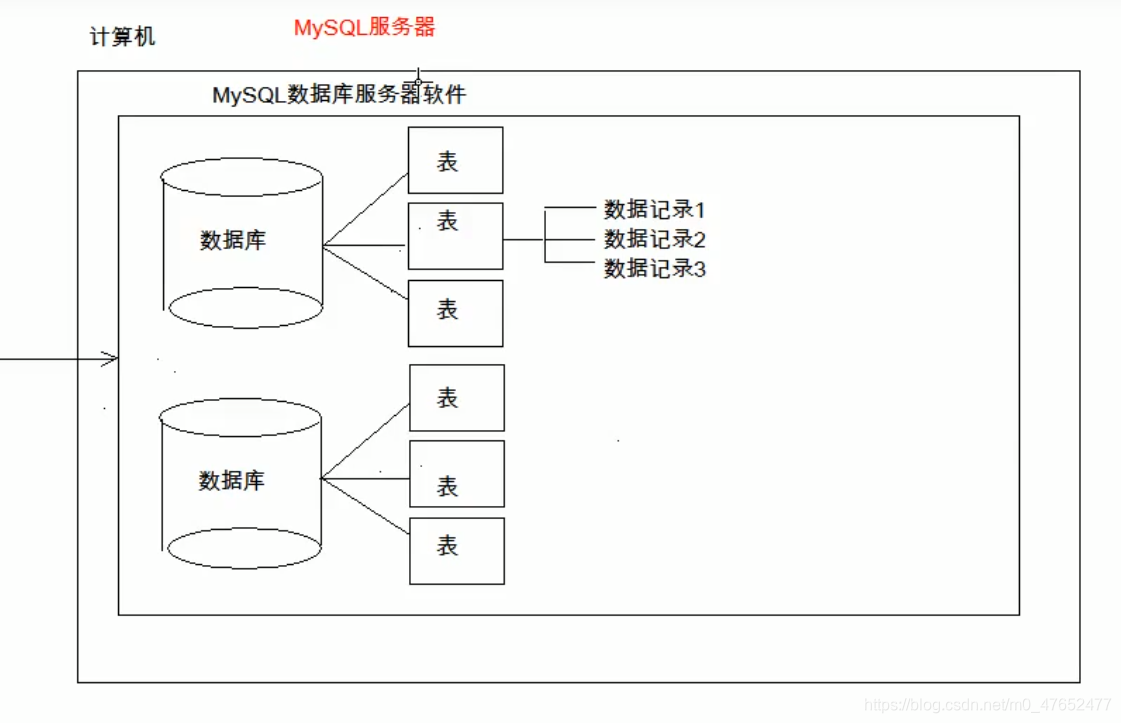
几个概念
- 数据库: 文件夹
- 表: 文件
- 数据: 文件里面存储的数据
2.4 SQL基本概念
SQL(Structured Query Language): 结构化查询语言, SQL其实就是定义了操作所有关系型数据库的规则.每一种数据库操作的方式存在不一样的地方,我们称为"方言",而SQL的通用语句其实就是"普通话",所有关系型数据库都能够用
2.5 SQL通用语法
一些书写提示
- SQL语句可以单行或者多行书写,以分号结尾
- 可使用空格和缩进来增强语句的可读性.
- MySQL数据库的SQL语句一般不区分大小写,但是关键字我们建议用大写
- 3种注释
- 单行注释:
-- +空格+空格,后面写内容 - 单行注释:
#后面写内容,这个是MySQL的特有注释格式 - 多行注释:
/* 内容 */
- 单行注释:
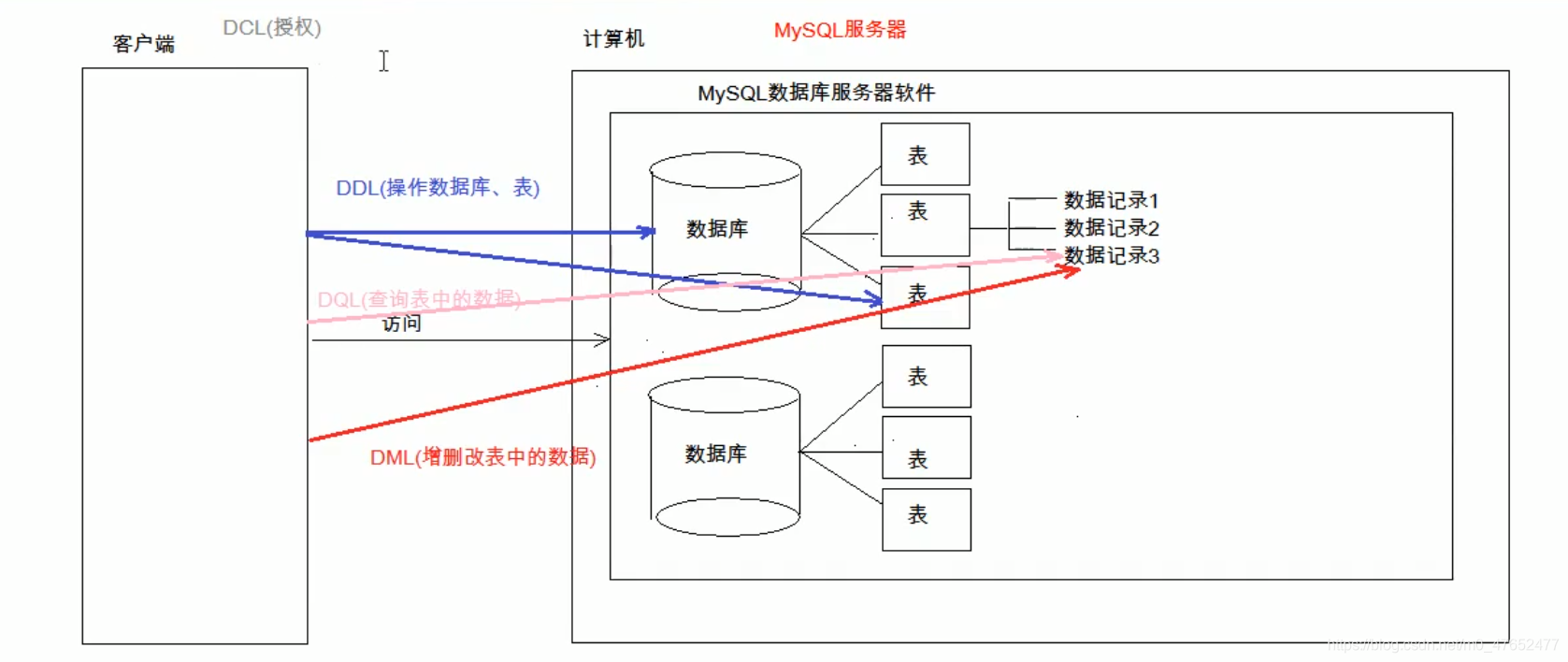
2.6 SQL的分类
-
DDL(Data Definition Language): 数据定义语言
- 用来定义数据库对象: 数据库,表,列等.关键字:
create, drop,alter等
- 用来定义数据库对象: 数据库,表,列等.关键字:
-
DML(Data Manipulation Language): 数据操作语言
- 用来对数据库中表的数据进行增删改.关键字:
insert,delete,update等
- 用来对数据库中表的数据进行增删改.关键字:
-
DQL(Data Query Language): 数据查询语言
- 用来查询数据库中表的记录(数据). 关键字:
select,where等
- 用来查询数据库中表的记录(数据). 关键字:
-
DCL(Data Control Language) 数据控制语言(了解)
- 用来定义数据库访问权限和安全级别,及创建用户. 关键字:
GRANT,REVOKE等
图解
- 用来定义数据库访问权限和安全级别,及创建用户. 关键字:
2.7 DDL(Data Definition Language)
2.7.1 操作数据库: CRUD
CRUD(对应增删改查操作)
- C(Create): 创建
- R(Retrieve): 查询
- U(Update): 修改
- D(Delete): 删除
创建&查询数据库
查询所有数据库的名称: show databases;
查询某个数据库的字符集show create database
例:

这里告诉我们mysql这个数据库是怎么创建的,同时注释告诉我们这个数据库的字符集是 utf-8,这里和我们对mysql的配置有关
创建数据库: create database 数据库名称;
为了防止创建了同名的数据库而报错,我们使用下面的语句
create database if not exists 数据库名称
创建指定字符集的数据库:create database 数据库名称 character set 字符集名称
例: `create database CJY character set gbk;`
修改&删除&使用数据库
修改数据库的字符集: alter database 数据库名称 character set 字符集名称;
例: alter database cjy character set utf-8
删除数据库: drop database 数据库名称;
为了防止要删的数据库不存在而报错,我们使用
drop database if exists 数据库名称来做一个判断,防止报错
使用数据库
-
查询当前使用的数据库的名称:
select database(); -
使用数据库:
use 数据库名称;
2.7.2 操作表:CRUD
同样也是有增删改查四个功能
查询表
查询某个数据库中所有表的名称: show tables;
查询表结构:desc 表名;
创建表(重点!)
这个操作是使用的很频繁的操作,需要比较熟练
我们要规定表的姓名,还要规定里面的所有需要的东西(几行几列,存储什么类型数据)
创建表:
create table 表名(
列名1 数据类型1,
列名2 数据类型2,
...
列名n 数据类型n
);
注意: 最后一列不要加逗号
数据库的数据类型
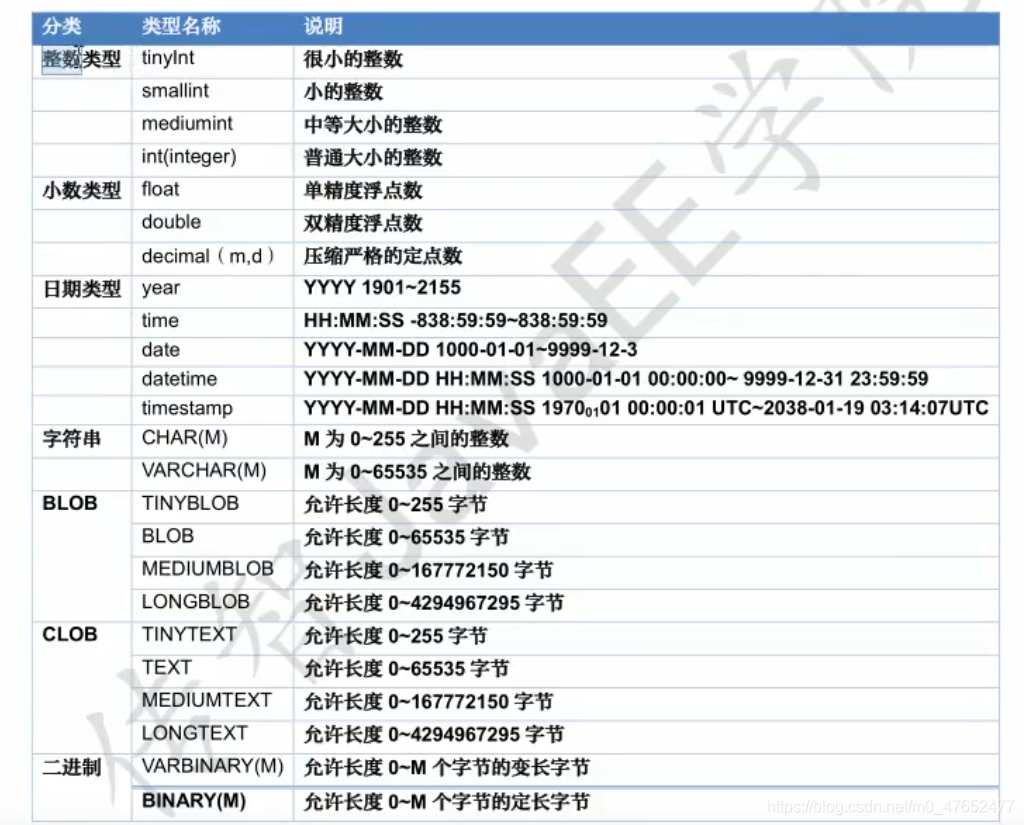
常用数据类型
-
整数类型: int
-
小数类型:
double (x,y)其中x是最大位数,y是小数后面几位- 举例
double(5,2)就是最大999.99
- 举例
-
日期类:
date只包含年月日yyyy-MM-dddatetime:哪怕年月日时分秒 yyyy-MM-dd HH:mm:sstimestamp:时间戳类型,如果将来这个字段不赋值,则默认使用当前系统时间自动赋值
-
字符串类型:
varchar(最大字符长度)
来我们创建一个学生表
表的结构
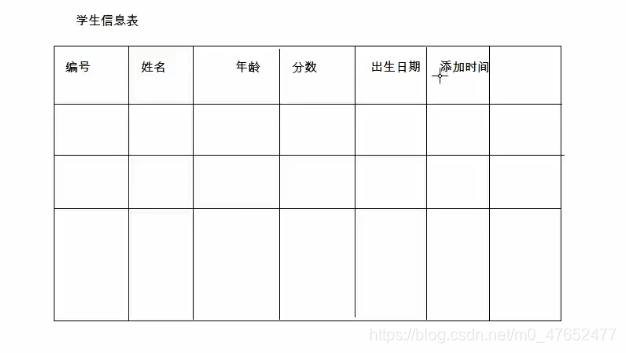
用下列语句创建
create table student(
id int,
name varchar(32),
age int,
score double(4,1),
birthday date,
insert_time timestamp
);
复制一个表的结构然后创建一个新表
create table stu like student;这句话的意思就是创建一个结构和student一毛一样的表stu
删除表
drop table 表名;
为了防止报错,那么我们加一个判断条件
drop table if exists 表名;
修改表
-
修改表的名称
alter table 表名 rename to 新的表名;
-
修改表的字符集
alter table 表名 character set 要修改的字符集名称;
-
表中添加一列
alter table 表名 add 新列名 数据类型;
-
修改列的名称 类型
-
既改名字,又改类型:
alter table 表名称 change 要修改的列名 修改后的名称 修改后的数据类型 -
只改类型:
alter table 表名称 modify 要修改的目标列名 修改后的数据类型
-
-
删除列
alter table 表名 drop 要删除的列名;
2.8 DML(data Manipulation Language)(重要 )
2.8.1 客户端图形化工具 : SQLyog
因为我们在cmd里面使用很不方便,所以我们需要一个图形化页面工具来方便我们查看和操作数据库的数据
所以我们选择了这个,过程就不多说了
2.8.2 添加数据
insert into 表名(列名1,列名2,...,列名n) values(值1,值2,....,值n)
注意: date类,字符串类要加上’ ',这里单双引号都可以
例: 我输入INSERT INTO stu (id,NAME,age,score,birthday,sex) VALUES(1,"你爹",20,100,'1992-11-19','男');
那么就可以看到表中添加了如下数据

注意事项
- 列名和值要一 一对应
- 如果表名后不定义列名,则默认给所有列添加值
- 给所有列名添加值
insert into 表名 values(值1,值2,....,值n)这里注意要一 一对应,不想给值就写个null,特别对于timestamp,输入null他就会自动插入当前系统时间
- 给所有列名添加值
2.8.3 删除数据
delete from 表名 [where 条件]
例:删除stu表中id是1的数据
DELETE FROM stu WHERE id=1;
注意:
- 如果不加条件,那么将会删除表中所有数据(不建议使用,因为用这个删除的方式,时间复杂度是O(N) )
- 删除表的所有数据我们就先删除表再重新创建一个一模一样的表,使用
truncate table 表名就可以了,这个方法时间复杂度只有1
2.8.4 修改数据
update 表名 set 列名1 = 值1, 列名2 = 值2,....,列名n = 值n [where 条件]
例: 修改id为2 的成绩改为88分
update stu set score = 88 where id =2;
注意
- 如果不加条件,那么将会将表中的所有数据都更改
2.9 DQL(Data Query Language)
语法
select
字段列表
from
表名列表
where
条件列表(多个条件)
group by
分组字段
having
分组之后的条件
order by
排序
limit
分页限定
别慌,很多都是可选的
2.9.1 基础查询
我们先看看,表中的数据原来长什么样子

-
多个字段的查询
-
所有字段的查询
select * from stu; -
select name,age,id from stu -
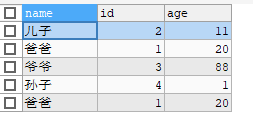
-
-
去除重复
select distinct name,age,id from stu;- 我们发现两个爸爸没了,只剩一个爸爸

-
计算列
-
一般可以使用四则运算来计算一些值
-
计算score +10的分数
SELECT NAME, 10+ IFNULL(score,0) FROM stu;IFNULL(x,y)是一个函数,如果x是null那么这个函数输出y,否则还是x -
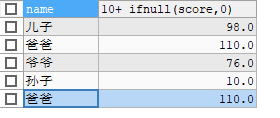
-
-
起别名
-
刚才那个加出来的结果的列起一个别名
SELECT NAME, 10 + IFNULL(score,0) AS 总分 FROM stu; -
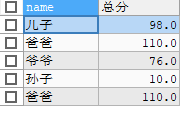
-
还可以
SELECT NAME 姓名,id 编号,age 年龄 FROM stu;(即as可以省略) -
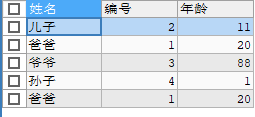
-
2.9.2 条件查询
常见运算符

注意! SQL中等于用 = 而不是==
举例:
- 我们查询stu中分数大于60的人
select * from stu where score>60;
我们发现孙子没了

逻辑运算符

2.9.3 模糊查询
当我们不知道我们要查的数据具体是什么的时候,我们就可以用模糊查询,比如说,我想查一个叫李XX,的人,我只知道它姓李,那就使用模糊查询
- LIKE: 模糊查询
- 占位符
- _: 单个任意字符
- %: 多个任意字符,也可以是0个
- 占位符
例:
- 查询name开头是"爸"的数据
SELECT * FROM stu WHERE NAME LIKE '爸%';
查询结果

-
查询年龄是两位数且个位数是0的数据
SELECT * FROM stu WHERE age LIKE '_0';
我们发现,就算age的类型是整数类型,但是查询的时候还是要加上""符号
- 查询名字是2个字的人
SELECT * FROM stu WHERE NAME LIKE '__';
- 查询名字中包含子的人(最常用)
SELECT * FROM stu WHERE NAME LIKE '%子%';
询,比如说,我想查一个叫李XX,的人,我只知道它姓李,那就使用模糊查询
- LIKE: 模糊查询
- 占位符
- _: 单个任意字符
- %: 多个任意字符,也可以是0个
- 占位符
例:
- 查询name开头是"爸"的数据
SELECT * FROM stu WHERE NAME LIKE '爸%';
查询结果
[外链图片转存中…(img-7bDzsLNr-1618566050870)]
-
查询年龄是两位数且个位数是0的数据
SELECT * FROM stu WHERE age LIKE '_0';[外链图片转存中…(img-lZR4sGCQ-1618566050870)]
我们发现,就算age的类型是整数类型,但是查询的时候还是要加上""符号
- 查询名字是2个字的人
SELECT * FROM stu WHERE NAME LIKE '__';
- 查询名字中包含子的人(最常用)
SELECT * FROM stu WHERE NAME LIKE '%子%';

2.9.4 排序查询
语法:
-
select XX FROM table名order by 子句 [可选 排序方式](默认ASC) -
order by 排序字段1 排序方式1 , 排序字段2 排序方式2
排序方式
- ASC: 升序排列
- DESC: 降序排列
例子: 我们按照score降序排名,如果分数一样,那就比年龄(降序)
数据库里的数据

我们使用SELECT * FROM stu ORDER BY score DESC,age DESC;

注意
- 如果有多个排序条件,则第一个条件的值一样时,才会判断第二个
2.9.5 聚合函数
将一列数据作为一个整体,进行纵向的计算,我们可以利用它求平均值等
- count: 计算个数
- 一般选择非空的列: 主键
SELECT COUNT(NAME) FROM stu;SELECT COUNT(*) FROM stu;这句话的意思就是计算不全为空的列数
- max: 计算最大值
SELECT NAME,MAX(score) FROM stu;
- min: 计算最小值
SELECT NAME,MIN(score) FROM stu;
- sum: 求和
SELECT NAME,SUM(score) FROM stu;
- avg: 计算平均值
SELECT AVG(score) FROM stu;
注意: 聚合函数会排除null的数据
-
SELECT COUNT(address) FROM stu;我们会发现给出的值是0- 为了解决这个问题,我们老样子,使用IFNULL(x,y)函数
SELECT COUNT(IFNULL(address,1)) FROM stu;
- 为了解决这个问题,我们老样子,使用IFNULL(x,y)函数
2.9.6 分组查询
语法
group by 分组字段
举例: 现在我们要查询男女score的平均分
表原来的数据
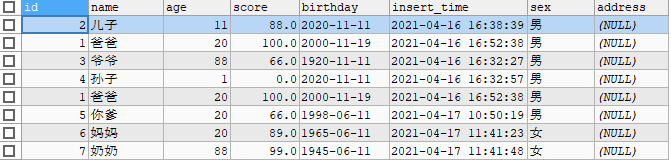
使用select sex,avg(score) from stu group by sex;
得出结果
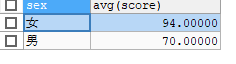
- 注意
- 分组之后查询的字段: 分组字段,聚合函数 ,语法上来讲就是
select 分组字段,聚合函数 from 表名 group by 分组字段注意,这里的聚合函数是分组的,他计算的是分组字段分组之后,组内的聚合函数的结果(就像例题) - 我们还可以组合,比如说我们根据性别分组,并且只找分数大于70的同时分组出来的人数大于2,并计算平均分
SELECT sex,AVG(score) FROM stu WHERE score > 70 GROUP BY sex HAVING count(NAME) > 2; - where和having 的区别在哪?
- where在分组之前进行限定,having在分组之后进行限定
- where 后面不可以跟聚合函数,但是having可以
- 分组之后查询的字段: 分组字段,聚合函数 ,语法上来讲就是
2.9.7 分页查询
语法: limit 开始的索引,每页查询的条数;
公式: 开始的索引 = (当前页码数 -1) * 每条显示的条数
例:
SELECT * FROM stu LIMIT 0,3; -- 第一页
SELECT * FROM stu LIMIT 3,3; -- 第二页
SELECT * FROM stu LIMIT 6,3; -- 第三页
注意
- 分页操作limit语法是一个MySQL的"方言",MySQL的语法和其他数据库软件的语句是不一样的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









