






Datawhale提供的pandas学习的开源地址:Joyful Pandas
pandas基础
文件的读取和写入
文件读取
数据写入
基本数据结构
Series
DataFrame
常用基本函数
汇总函数
特征统计函数
唯一值函数
替换函数
排序函数
apply方法
窗口对象
滑窗对象
扩张窗口
练习
口袋妖怪数据集
指数加权窗口
一、文件的读取和写入
1.文件的读取
主要介绍常用的csv、txt、excel文件的读取。
这里先介绍csv的读取,txt和excel文件读取方式相同。
df_csv = pd.read_csv('C:/Users/ASUS/Desktop/joyful-pandas-master/data/my_csv.csv')
df_csv
col1 col2 col3 col4 col5
0 2 a 1.4 apple 2020/1/1
1 3 b 3.4 banana 2020/1/2
2 6 c 2.5 orange 2020/1/5
3 5 d 3.2 lemon 2020/1/7
df_txt = pd.read_table('C:/Users/ASUS/Desktop/joyful-pandas-master/data/my_txt.txt')
df_excel = pd.read_excel('C:/Users/ASUS/Desktop/joyful-pandas-master/data/my_excel.excel')
注意括号中的路径直接在文件属性中找就可以,把\改成/.
读取格式中有些常用的公共参数:
header=None 第一行不作为列名
df_csv = pd.read_csv('C:/Users/ASUS/Desktop/joyful-pandas-master/data/my_csv.csv', header=None)
df_csv
0 1 2 3 4
0 col1 col2 col3 col4 col5
1 2 a 1.4 apple 2020/1/1
2 3 b 3.4 banana 2020/1/2
3 6 c 2.5 orange 2020/1/5
4 5 d 3.2 lemon 2020/1/7
index_col 把某一列或几列作为索引
pd.read_csv('C:/Users/ASUS/Desktop/joyful-pandas-master/data/my_csv.csv', index_col=['col1','col3'])
col2 col4 col5
col1 col3
2 1.4 a apple 2020/1/1
3 3.4 b banana 2020/1/2
6 2.5 c orange 2020/1/5
5 3.2 d lemon 2020/1/7
usecols 读取列的集合,默认读取所有的列
pd.read_csv('C:/Users/ASUS/Desktop/joyful-pandas-master/data/my_csv.csv',usecols=['col1','col5'])
col1 col5
0 2 2020/1/1
1 3 2020/1/2
2 6 2020/1/5
3 5 2020/1/7
parse_dates 需要转化时间的列
pd.read_csv('C:/Users/ASUS/Desktop/joyful-pandas-master/data/my_csv.csv',parse_dates=['col5'])
col1 col2 col3 col4 col5
0 2 a 1.4 apple 2020-01-01
1 3 b 3.4 banana 2020-01-02
2 6 c 2.5 orange 2020-01-05
3 5 d 3.2 lemon 2020-01-07
nrows 读取的数据行数
pd.read_csv('C:/Users/ASUS/Desktop/joyful-pandas-master/data/my_csv.csv',nrows=2)
col1 col2 col3 col4 col5
0 2 a 1.4 apple 2020/1/1
1 3 b 3.4 banana 2020/1/2
读取txt文件时我们可以自定义分隔符号
pd.read_table('C:/Users/ASUS/Desktop/joyful-pandas-master/data/my_txt.txt', sep=' ',engine='python')
其中sep就是分割参数,engine是需要指定的引擎。
2.数据的写入
一般在数据写入中,最常用的操作是把 index 设置为 False ,特别当索引没有特殊意义的时候,这样的行为能把索引在保存的时候去除。
df_csv.to_csv('data/my_csv_saved.csv', index=False)
df_excel.to_excel('data/my_excel_saved.xlsx', index=False)
由于pandas中没有定义to_table函数,但我们可以to_csv来保存txt文件,使用中我们可以自定义分隔符sep,常用制表符\t进行分割。
df_txt.to_csv('data/my_txt_saved.txt', sep='\t', index=False)
二、基本数据结构
pandas中有两种的基本数据储存结构,一维的Series和二维的DataFrame。
1.Series
Series一般由四个部分组成,序列的值data(我们要写入的)、索引index(我们可以指定索引的名字,也可以不指定,默认为空)、储存类型dtype、序列的名字name。
s = pd.Series(data = [100, 'a', {'dic1':5}],
index = pd.Index(['id1', 20, 'third'], name='my_idx'),
dtype = 'object',
name = 'my_name')
s
my_idx
id1 100
20 a
third {'dic1': 5}
Name: my_name, dtype: object
其中object是一种混合的类型,上面存储了整数、字符串和字典数据结构。
我们可以通过s.的方式来获取s的属性。
如:s.values\index\dtype\name\shape
想要获取单个索引值可以通过s[‘index_item’]取出。
2.DataFrame
DataFrame就是在Series的基础上加上了列索引,一个数据可以由二维的data与列索引来构造:
data = [[1, 'a', 1.2], [2, 'b', 2.2], [3, 'c', 3.2]]
df = pd.DataFrame(data = data,
index = ['row_%d'%i for i in range(3)],
columns=['col_0', 'col_1', 'col_2'])
df
col_0 col_1 col_2
row_0 1 a 1.2
row_1 2 b 2.2
row_2 3 c 3.2
我们一般都会采取索引对应数据的映射来构造数据框:
df = pd.DataFrame(data = {'col_0': [1,2,3], 'col_1':list('abc'),
'col_2': [1.2, 2.2, 3.2]},
index = ['row_%d'%i for i in range(3)])
在 DataFrame 中可以用 [col_name] 与 [col_list] 来取出相应的列与由多个列组成的表,
结果分别为 Series 和 DataFrame。
与 Series 类似,在数据框中同样可以取出相应的属性。
三、常用函数
为了进行举例说明,在接下来的部分和其余章节都将会使用一份 learn_pandas.csv 的虚拟数据集,它记录了四所学校学生的体测个人信息。

上述列名依次代表学校、年级、姓名、性别、身高、体重、是否为转系生、体测场次、测试时间、1000 米成绩。现在我们取出其中的前七列。
df = df[df.columns[:7]]
1.汇总函数
a.head()和tail(),分别表示取出前n行和后n行。默认n值为5。

b.info, describe 分别返回表的 信息概况和表中 数值列对应的主要统计量:

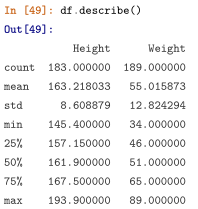
2.特征统计函数
在 Series 和 DataFrame 上定义了许多统计函数,最常见的是 sum, mean, median, var, std, max, min 。例如,选出身高和体重列进行演示:

quantile, count, idxmax 这三个函数,它们分别返回的是分位数、非缺失值个数、最大值对应的索引:

上面这些所有的函数,由于操作后返回的是标量,所以又称为聚合函数,它们有一个公共参数 axis ,默认为0 代表逐列聚合,如果设置为 1 则表示逐行聚合。
3.唯一值函数
对序列使用 unique 和 nunique 可以分别得到其唯一值组成的列表和唯一值的个数:
value_counts 可以得到唯一值和其对应出现的频数:

如果想要观察多个列组合的唯一值,可以使用 drop_duplicates 。其中的关键参数是 keep ,默认值 first 表示每个组合保留第一次出现的所在行,last 表示保留最后一次出现的所在行,False 表示把所有重复组合所在的行剔除。

4.替换函数
一般而言,替换操作是针对某一个列进行的,因此下面的例子都以 Series 举例。pandas 中的替换函数可以归纳为三类:映射替换、逻辑替换、数值替换。其中映射替换包含 replace 方法、第八章中的str.replace 方法以及第九章中的 cat.codes 方法,此处介绍 replace 的用法。
在 replace 中,可以通过字典构造,或者传入两个列表来进行替换:

另外,replace 还有一种特殊的方向替换,指定 method 参数为 ffill 则为用前面一个最近的未被替换的值进行替换,bfill 则使用后面最近的未被替换的值进行替换。从下面的例子可以看到,它们的结果是不同的:

逻辑替换包括了 where 和 mask ,这两个函数是完全对称的:where 函数在传入条件为 False 的对应行进行替换,而 mask 在传入条件为 True 的对应行进行替换,当不指定替换值时,替换为缺失值。


数值替换包含了 round, abs, clip 方法,它们分别表示取整、取绝对值和截断:


5.排序函数
sort_values 值排序
sort_index 索引排序
升降序排列的默认参数ascending=True为升序
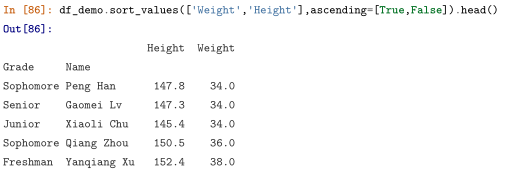
6.apply方法
pply 方法常用于 DataFrame 的行迭代或者列迭代, 它的 axis 含义与第 2 小节中的统计聚合函数一致, apply的参数往往是一个以序列为输入的函数。例如对于 .mean() ,使用 apply 可以如下地写出:

同样的,可以利用 lambda(匿名函数) 表达式使得书写简洁,这里的 x 就指代被调用的 df_demo 表中逐个输入的序列,其中还可以用axis参数来设置传入函数是行还是列:
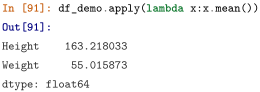

apply 的自由度很高,但这是以性能为代价的。一般而言,使用pandas 的内置函数处理和 apply 来处理同一个任务,其速度会相差较多,因此只有在确实存在自定义需求的情境下才考虑使用 apply 。
四、窗口对象
pandas 中有 3 类窗口,分别是滑动窗口 rolling 、扩张窗口 expanding 以及指数加权窗口 ewm 。需要说明的是,以日期偏置为窗口大小的滑动窗口将在第十章讨论,指数加权窗口见本章练习。
1.滑窗对象
滑窗对象是对一个序列使用.rolling得到,其中最重要的参数就是窗口大小window。

在得到了滑窗对象后,能够使用相应的聚合函数进行计算,需要注意的是窗口包含当前行所在的元素,例如在第四个位置进行均值运算时,应当计算 (2+3+4)/3,而不是 (1+2+3)/3。
我所理解的就是因为窗口大小是3,所以从数字3开始才满足窗口的大小才能进行运算,相对的是最后一个窗口就是[3,4,5]的数组。所以窗口大小为3的时候就会得到两个窗口[2,3,4]、[3,4,5]。


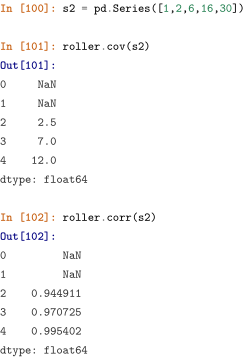
以上例子建议大家自己去算一下能够更好的理解窗口。
此外,还支持使用 apply 传入自定义函数,其传入值是对应窗口的 Series 。
shift, diff, pct_change 是一组类滑窗函数,它们的公共参数为 periods=n ,默认为 1,分别表示取向前第 n个元素的值、与向前第 n 个元素做差(与 Numpy 中不同,后者表示 n 阶差分) 、与向前第 n 个元素相比计算增长率。这里的 n 可以为负,表示反方向的类似操作。
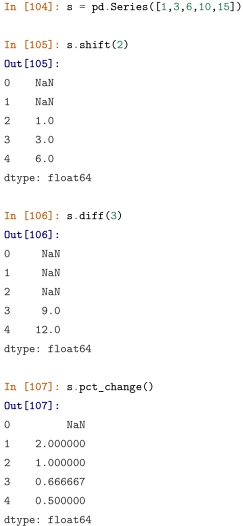
将其视作类滑窗函数的原因是,它们的功能可以用窗口大小为 n+1 的 rolling 方法等价代替:

2.扩张窗口
扩张窗口又称累计窗口,可以理解为一个动态长度的窗口,其窗口的大小就是从序列开始处到具体操作的对应位置,其使用的聚合函数会作用于这些逐步扩张的窗口上。具体地说,设序列为 a1, a2, a3, a4,则其每个位置对应的窗口即 [a1]、[a1, a2]、[a1, a2, a3]、[a1, a2, a3, a4]。

五、练习
1.口袋妖怪数据集
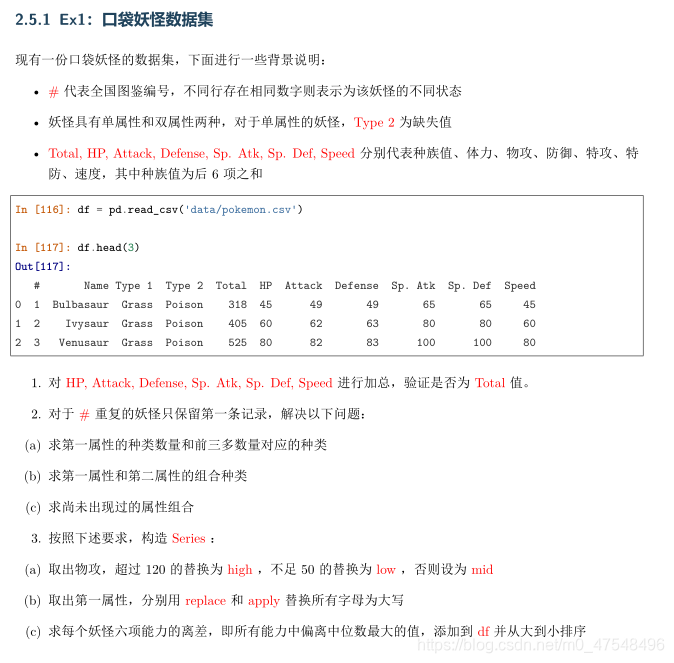
1.自己的解:
df = pd.read_csv('C:/Users/ASUS/Desktop/joyful-pandas-master/data/pokemon.csv')
df_one = df[df.columns[5:12]]
df_one.sum(axis=1)
0 318
1 405
2 525
3 625
4 309
...
795 600
796 700
797 600
798 680
799 600
Length: 800, dtype: int64
s = df_one.sum(axis=1)
a = s - df_two
0 0
1 0
2 0
3 0
4 0
..
795 0
796 0
797 0
798 0
799 0
Length: 800, dtype: int64
答案的解:

2.
a.自己的解:
df['Type 1'].value_counts().head(3)
Water 112
Normal 98
Grass 70
Name: Type 1, dtype: int64
a.答案的解:

b.自己的解:
df_demo.drop_duplicates(keep = False)
Type 1 Type 2
7 Fire Dragon
196 Electric Dragon
237 Fire Rock
245 Steel Flying
271 Psychic Grass
275 Grass Dragon
307 Bug Water
316 Bug Ghost
366 Dragon Fairy
424 Ground Fire
434 Grass Ground
440 Water Steel
445 Normal Water
490 Ghost Dark
501 Poison Bug
530 Ice Ghost
531 Electric Ghost
532 Electric Fire
533 Electric Water
534 Electric Ice
536 Electric Grass
540 Steel Dragon
542 Fire Steel
553 Psychic Fire
589 Ground Steel
679 Ground Electric
699 Steel Fighting
700 Rock Fighting
706 Dragon Fire
707 Dragon Electric
728 Normal Ground
743 Fighting Dark
760 Poison Water
761 Poison Dragon
771 Fighting Flying
772 Electric Fairy
797 Psychic Ghost
798 Psychic Dark
799 Fire Water
b.答案的解:

c.答案的解:


a.自己的答案:
df['Attack']
a = df['Attack'].mask(df['Attack'] > 120, 'high')
c = a.mask(df['Attack']<50, 'low')
d = c.mask((50<=df['Attack']) & (df['Attack']<=120), 'mid').head()
0 low
1 mid
2 mid
3 mid
4 mid
Name: Attack, dtype: object
a.答案的解:

b.答案的解:
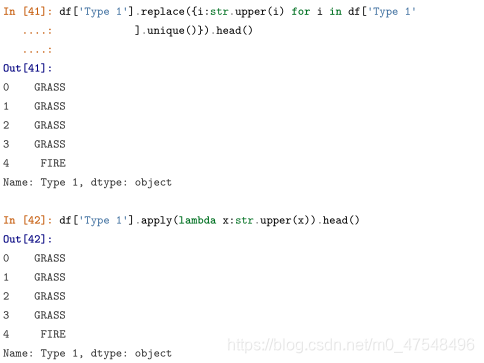
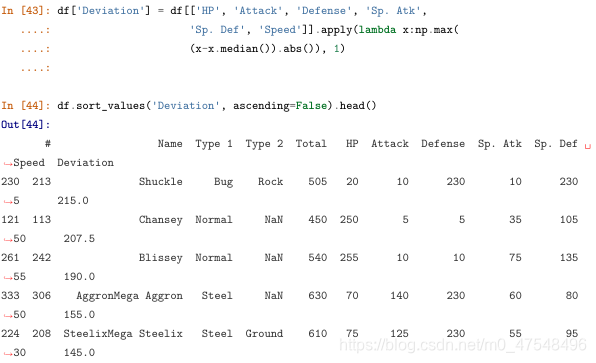
c.答案的解:
EX2:指数加权窗口


请用expanding窗口实现
参考答案:



坚持就是胜利虽然还有很多题目不会做。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









