







Java基础
Java编译运行过程:
编译期:
.java源文件,经过编译,生成.class字节码文件
运行期:
JVM加载.class并运行.class(0和1)
java的特点:
跨平台、一次编译到处运行
名词解释:
JVM:Java虚拟机
java虚拟机加载.class并运行.class
JRE(Java Runtime Environment):java运行环境
JRE包括Java虚拟机JVM(Java Virtual Machine)和Java程序所需的核心类库等
JRE = JVM + Java SE标准类库
JDK(Java Development Kit):Java开发工具包
JDK是提供给Java开发人员使用的,其中包含了JRE和java的开发工具集(编译工具(javac.exe)、打包工具(jar.exe)等)
JDK = JRE + 开发工具集
说明:
运行java程序的最小环境为JRE
开发java程序的最小环境为JDK
注释:
java规范的三种注释方式:
1. 单行注释: //
2. 多行注释:/* */
3. 文档注释:/** */(Java特有)
单行注释和多行注释的作用:
① 对所写的程序进行解释说明,增强可读性。方便自己,方便别人
② 调试所写的代码(找错)
特点:单行注释和多行注释,注释了的内容不参与编译。
换句话说,编译以后生成的.class结尾的字节码文件不包含注释掉的信息
文档注释的使用:
注释内容可以被JDK提供的工具 javadoc 所解析,生成一套以网页文件形式体现的该程序的说明文档。
操作方式:cmd-> javadoc -d 文件名(生成的文件) -author -version 源文件.java
变量
变量存数的,可以理解为一个代词,代表它所存的数。
变量的概念
- 内存中的一个存储区域
- 该区域的数据可以在同一类型范围内不断变化
- 变量是程序中最基本的存储单元。包含变量类型、变量名和存储的值
变量的作用
- 用于在内存中保存数据
变量按数据类型分类

基本数据类型变量存的是数据本身,而引用类型变量存的是保存数据的空间地址
变量按声明位置不同分类
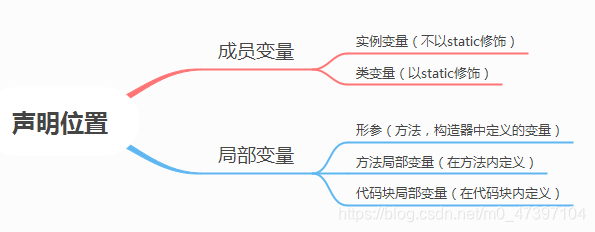
注:局部变量除形参外,需显式初始化
使用变量注意
- Java中每个变量必须先声明,后使用
- 使用变量名来访问这块区域的数据
- 变量的作用域:其定义所在的一对{ }内
- 变量只有在其作用域内才有效
- 同一个作用域内,不能定义重名的变量
- 变量的操作必须与数据类型匹配
声明变量
语法:<数据类型> <变量名称>
int a; //声明一个整型的变量,名为a
int b,c,d; //声明三个整型的变量,名为b,c,d(同一类型的变量才可以同时声明)
初始化:第一次赋值
语法:<变量名称> = <值>
声明并赋值,语法: <数据类型> <变量名> = <初始化值>
int a = 250; //声明整型变量a并赋值为250
int a; //声明整型变量a
a = 250; //给声明的变量a赋值为250
给变量赋值的三种方式:
//1.赋一个固定的值:
int a = 10
//2.接收用户输入的值:Scanner(小零件)
pack day01;
import java.util.Scanner;
public class Test{
public static void main(String[] args){
Scanner scan = new Scanner(System.in);
System.out.println("请输入");
int num = scan.nextInt();//scan要与上面的保持一致,是可更改的变量
double num = scan.nextDouble();
}
}
//3.系统随机生成的值,java提供了两种生成随机数的方式:
//方式一:
int num = Math.random()//随机生成0.0到0.999999999999··之间的数
//方式二:
pack day01;
import java.util.Random;
public class Test{
public static void main(String[] args){
Random rand = new Random();
int num = rand.nextInt(2);//随机0到括号里减1之间的数,举例是0到1之间的数
}
}
变量的使用
/*
变量的使用
1. Java定义变量的格式:数据类型 变量名 = 变量值;
2. 说明
①变量必须先声明,后使用
②变量都定义在其作用域内。在作用域内,它是有效的。换句话说,出了作用域,就失效了
③同一个作用域内,不可以声明两个同名的变量
*/
class VariableTest{
public static void main(String[] args){
//变量的定义
int myAge = 12;
int a = 5;
//变量的使用
System.out.println(myAge);
int b = a + 10; //取出a的值5,加10后,再赋值给整型变量b
System.out.println(b); //输出变量b的值15
System.out.println(“b”); //输出b,双引号中的内容原样输出
a = a + 10; //取出a的值5,加10后,再赋值给a
System.out.println(a); //15
int a = 3.14; //编译错误,数据类型不匹配
//编译错误:使用myNumber之前并为定义过myNumber
//System.out.println(myNumber);
//变量的声明
int myNumber;
//编译错误:使用myNumber之前并未赋值过myNumber
//System.out.println(myNumber);
//变量的赋值
myNumber = 1001;
//编译不通过,不在myClass作用域之内
//System.out.println(myClass);
//不可以在同一个作用域内定义同名的变量
//int myAge = 22;
}
public void method(){
int myClass = 1;
}
}
标识符
1. 标识符:Java 对各种变量、方法和类等要素命名时使用的字符序列称为标识符
技巧:凡是自己可以起名字的地方都叫标识符。
比如:类名、变量名、方法名、接口名、包名…
- 定义合法标识符规则:如果不遵守如下的规则,编译不通过!需要严格遵守
1. 由26个英文字母大小写,0-9 ,_或 $ 组成
2. 数字不可以开头。
3. 不可以使用关键字和保留字,但能包含关键字和保留字。
4. Java中严格区分大小写,长度无限制。
5. 标识符不能包含空格。
Java中的名称命名规范:
- 包名:多单词组成时所有字母都小写:
xxxyyyzzz;多级包时用.隔开,如:com.demo.controller - 类或者接口(帕斯卡命名法):多单词组成时,所有单词的首字母大写:
XxxYyyZzz - 变量名、方法名(驼峰命名法):多单词组成时,第一个单词首字母小写,第二个单词开始每个单词首字母大写:
xxxYyyZzz - 常量名:所有字母都大写。多单词时每个单词用下划线连接:
XXX_YYY_ZZZ
注意1:在起名字时,为了提高阅读性,要尽量有意义,“见名知意”。
注意2:java采用unicode字符集,因此标识符也可以使用汉字声明,但是不建议使用。
关键字和保留字
关键字(keyword)的定义和特点
定义:被Java语言赋予了特殊含义,用做专门用途的字符串(单词)
特点:关键字中所有字母都为小写
官方地址:https://docs.oracle.com/javase/tutorial/java/nutsandbolts/_keywords.html
true、false和null可能看起来像关键字,但它们实际上是文字。不能在程序中将它们用作标识符
| 用于定义数据类型的关键字 | ||||
| class | interface | enum | byte | short |
| int | long | float | double | char |
| boolean | void | |||
| 用于定义流程控制的关键字 | ||||
| if | else | switch | case | default |
| while | do | for | break | continue |
| return | ||||
| 用于定义流程控制的关键字 | ||||
| private | protected | public | ||
| 用于定义类,函数,变量修饰符的关键字 | ||||
| abstract | final | static | synchronized | |
| 用于定义类与类之间关系的关键字 | ||||
| extends | implements | |||
| 用于定义建立实例以及引用实例,判断实例的关键字 | ||||
| new | this | super | instanceof | |
| 用于异常处理的关键字 | ||||
| try | catch | finally | throw | throws |
| 用于包的关键字 | ||||
| package | import | |||
| 其他修饰符关键字 | ||||
| native | strictfp | transient | volatile | assert |
| *用于定义数据类型值的字面值 | ||||
| true | false | null | ||
保留字(reserved word)
Java保留字:现有Java版本尚未使用,但以后版本可能会作为关键字使
用。自己命名标识符时要避免使用这些保留字
goto、const
8种基本数据类型:
| 基本类型 | 占的内存(1字节是8位) | 最小值 | 最大值 | 默认值 |
|---|---|---|---|---|
| byte(字节型) | 1字节 | -128 | 127 | (byte)0 |
| short(短整型) | 2字节 | -2^15 | 2^15-1 | (short)0 |
| int(整型) | 4字节 | -2^31 | 2^31-1 | 0 |
| long(长整型) | 8字节 | -2^63 | 2^63-1 | 0L |
| float(单精度浮点型) | 4字节 | 1.4E-45 | 3.4028235E38 | 0.0F |
| double(双精度浮点型) | 8字节 | 4.9E-324 | 1.7976931348623157E308 | 0.0 |
| char(字符型) | 2字节 | 0x0000(0) | 0xffff(65535) | 空格 |
| boolean(布尔型) | 1字节 | - | false |
注意:声明变量类型时,会给变量分配内存,按类型的所占空间数来分配,实际开发中尽量用字节空间少的。
例如:如果年龄应该使用什么类型呢?最佳是byte,0~100,能活100岁很了不起,非常高寿了。当然也有习惯的因素,开发者习惯int age来定义
byte,1个字节
short 短整型,2个字节
int 整型,4个字节-----取值范围:-21个多亿到21个多亿
- 整数直接量默认位int 类型,但不能超范围,若超范围则发生编译错误
- 两个整数相除,结果还是整数,小数位无条件舍弃(不会四舍五入)
- 整数运算时,若超范围,会发生溢出(溢出不是错误,但需要避免)
long 长整型,8个字节
- 长整型直接量需在数字后加L或l
- 运算时若有可能溢出,建议在第一个数字后加L
float 浮点型,4个字节
double 浮点型,8个字节
- 浮点数直接量默认为double型,若想表示float需在数字后加F或f
- double和float型数据在运算时,有可能发生舍入误差(精确场合不能使用)
boolean 布尔型,1个字节
- 只能赋值为true或false
char 字符型,2个字节
- java中的char采用的是Unicode字符集编码格式,每个字符都对应一个码(是0~65535之间的码段)
表现的形式是字符char,本质上是码int(ASCII码:‘a’-97 ‘A’-95 ‘0’-48)
Unicode:万国码/统一码/通用码—世界级通用的定长字符集(16位) - 字符型直接量必须放在单引号中,且只能有一个
- 特殊字符需通过\来转义 例:char c = ‘ \’
类型的转换
数据类型从小到大依次为:
byte<short<int<long<float<double
char<int
两种方式
- 自动/隐式类型转换:小类型到大类型
- 强制类型转换:大类型到小类型(强转有可能会溢出或丢失精度)
语法:(要转换的数据类型)变量double b = 3.14 int a = (int)b
两点规则
- 整数直接量可以直接赋值给byte,short,char,但不能超出范围
byte: -128~127; short:-328~327; char:0~65535 - byte,short,char型数据参与运算时,会先转换为int再运
byte b1 = 5;//整数直接量可以直接赋值给byte,short,char,但不能超出范围 byte b2 = 5; //byte b4 = b1+b2;//编译错误,byte,short,char型数据参与运算时,会先转换为int型再运算 byte b3 = (byte)(b1+b2);//byte强转比运算优先级高,运算要括起来
运算符
数学运算与逻辑运算与关系运算一起使用时,优先级为:非>数学运算>关系运算>与>或
算术运算符:
+,-,*,/,%,++,- -
在java中整数除以整数结果还是整数,所有小数都会被忽略。
int h = 10 / 4;
System.out.println(h);//2 整数除以整数结果还是整数,所有小数都会被忽略。
double j = 10 / 3; //10和3都是int型的直接量,因此整数除以整数结果还是整数,所有结果是3。
double k = 10.0 / 3;//10.0是double型的直接量,那么运算结果就是小数了。
% :取模/取余,余数为0即为整除
int a = 10%3;
System.out.println(a);//1 10除以3余1,当计算结果为0时,表示可以整除
自增运算和自减运算:
++,-- :自增1/自减1,可在变量前也可以在变量后
- 单独使用时,在前在后都一样
- 被使用时,在前在后不一样
int m = 1;
System.out.println(m);//1
//单独使用
m++;//等效于: m = m + 1; m 自增1
System.out.println(m);//2
++m;//单独使用时与m++效果一样。
System.out.println(m);//3
//与赋值语句一起使用,在计算表达式中使用
int a = 1;
int b = 2;
int o1 = a++;
int o2 = ++b;
/*
* a++,是先将 a 的值赋值给o1,再将 a 自增。 ++在后的是先赋值再自增。
* ++b,是先将 b 自增,再将 b 的值赋值给o2 ++在前的是先自增再赋值。
*/
System.out.println(o1);//1
System.out.println(o2);//3
System.out.println(a);//2
System.out.println(b);//3
关系运算符:
>(大于) <(小于) >=(大于或等于) <=(小于或等于)
==(等于)!=(不等于)
关系运算的结果为boolean型,关系成立则为true,关系不成立则为false
逻辑运算符:
| 逻辑运算符 | 逻辑功能 |
|---|---|
| &(并且) | 有false则false |
| |(或者) | 有true则true |
| ! (非) | 非false则true,非true则false |
| ^(异或) | 相同为false,不同为true |
| &&(短路与) | 有false则false,若&&左边表达式或者值为false,则右边不进行计算 |
| ||(短路或) | 有true则true,若||左边表达式或者值为true,则右边不进行计算 |
逻辑运算是建立在关系运算的基础之上的,逻辑运算的结果也是boolean型
短路案例:
int a = 5,b = 10, c = 5;
System.out.println(a > b && c++>1);//false&&true
System.out.println(c); //上面发生短路,c++>1没执行,c没自增,还是5
System.out.println(a < b || c++>3);//true||true
System.out.println(c); //上面发生短路,c++>3没执行,c没自增,还是5
异或案例:
public class ketanglianxi {
public static void main(String[] args) {
Boolean a=3>2; //结果为true
Boolean b=4>5; //结果为false
Boolean c=a^b; //c=true^false, 不相同,所以结果为true
System.out.println(c);
}
}
赋值运算符:
简单赋值运算符:=
扩展赋值运算符(自带强转功能):+=,-=,*=,/=,%=
面试题:如下三句话哪句话错了?如何改?
short s = 5;
s += 10;//相当于s=(short)(s+10)
//s = s+10;//编译错误,此处需强转,改成:s=(short)(s+10)
字符串连接运算符:+
- 若两边为数字,则做加法运算
- 若两边出现了字符串,则做字符串连接
String s1 = 2 + 3 + "hello" ;
System.out.println(s1);//5hello 优先级,先算的2+3=5以后才跟后面的字符串连接
String s = "hello" + 2 + 3;
System.out.println(s);//hello23 这里的+是连接字符串的操作
条件/三目运算符:
语法:boolean?数1:数2
嵌套写法:boolean?数1: (boolean?数1:数2)
执行过程:计算boolean的值:
- 若为true,则整个表达式的值为?号后面的数1
- 若为false,则整个表达式的值为:号后面的数2
注意!!!
当数1,数2都为基本数据类型时,整个表达式的运算结果由容量高的决定!
int a = 5;
int flag = a > 0?1:-1;
System.out.println(flag);//a>0为true,表达式的值为?号后面的1
int b = 8,c = 5;
int max = b > c ? b : c;//b大于c为true,结果为b
System.out.println("最大值:" + max);
程序的三种基本结构
顺序结构:
代码依次从上往下执行
分支结构:
根据判断,有些代码执行,有些代码不执行
if结构:
有条件的执行某语句一次,并非每句必走
if(boolean){
语句块;
}
If…else结构:
if(boolean){
语句块1;
}else{
语句块2
}
if…else if结构:
if(boolean1){
语句块1;
}else if(boolean2){
语句块2;
}else if(boolean3){
语句块3;
}else{
语句块4;
}
Switch…case结构:
只要是对整数判断相等的,首选switch…case
优点:效率高、结构清晰
缺点:只能对整数判断相等的操作
Switch…case一般不会单独使用,会搭配break(跳出Switch)使用
注意:case值后不写break,会被穿透,程序直到找到break才返回
所有的switch语句都可以用 if…else if 语句来替换,但是 if…else if 不是都可以用switch替换(因为区间里值的个数是无限的并且switch所接受的值只能是整型或枚举型,所以不能用case来一答一列举)
Switch(整型变量){//byte、short、int、char、String(jdk1.7开始支持的
case 1://相当于if(num==1)
语句块1;
break;
case 2:
语句块2;
break;
default://以上条件都不满足时,走这个
语句块3;
}
循环结构
反复执行一段代码
循环三要素:
- 循环变量的初始化
- 循环的条件(以循环变量为基础)
- 循环变量的改变(向着循环的结束变)
循环变量:是指在整个循环过程中反复改变的那个数
三种循环结构的选择规则:
先看是否与次数相关
-
若与次数相关--------直接上for
-
若与次数无关,看要素1与要素3是否相同
- 若相同--------直接上do…while
- 若不相同------直接上while
while结构:
先判断后执行,有可能一次都不执行
while(boolean){
语句块;----反复执行的代码
}
执行过程:
判断boolean的值,若为true则执行语句块,
再判断boolean的值,若为true则再执行语句块,
再判断boolean的值,若为true则再执行语句块,
…如此反复…
直到判断boolean值为false,停止循环
do…while结构:
先执行后判断,至少执行一次(要素1与要素3相同时,首选do…while)
do{
语句块;
}while(boolean);
执行过程:
先执行语句块,再判断boolean的值,若为true则再执行语句块,
再判断boolean的值,若为true则再执行语句块,
再判断boolean的值,若为true则再执行语句块,
…如此反复…
直到boolean为false,循环结束
for结构:
与次数相关的、应用率最高…for中的循环变量作用范围仅在for中
执行过程:1243243243…2432
1 2 3
for(要素1;要素2;要素3){
语句块;(称为循环体)//4
}
/*
要素1 可以放外面,要素3 可以放里面,但分号必须要有
要素2 也可以省略,但无条件为死循环,需要避免!
*/
int i=1;
for(;i<9;){
语句块;
i++;
}
//要素1和要素3可以用逗号写多个,要素2只能有一个boolean值
for(int a=1,b=2;a<10;a+=2,b+=2){
语句块;
}
嵌套循环
- 循环中套循环,一般多行多列时使用,外层控制行,内层控制列
- 执行过程:外层循环走一次,内层循环走完
- 建议:嵌套层数越少越好,能用一层就不用两层,能用两层就不用三层
若业务必须通过三层以上的循环来解决,说明设计有问题 - break:只能跳一层循环
关键字:break: 跳出循环 continue:跳过循环体中剩余语句,进入下一个循环
\t :水平制表位,固定占8位
数组:
数组的定义
int[ ] a = new int[5]//声明整型数组a,包含5个元素,每个元素都是int类型,默认值为0
数组是相同数据类型的一组数据的集合,是一组固定长度的数据类型(引用类型),一旦被初始化,长度不可更改。
public class ddd {
public static void main(String[] args){
int num=5;
Student[] s2=new Student[num];
System.out.println(s2.length);//输出结果为:5
num=6;
System.out.println(s2.length);//输出结果为:5
}
}
由上代码段可以看出数组有定长特性,长度一旦指定,不可更改
和水杯道理一样,买了一个2升的水杯,总容量就为2升,不能多也不能少
除非你再买一个4升的水杯,这样才能装更多容量的水
public class ddd {
public static void main(String[] args){
Student[] s1=new Student[10];//买了一个10升的水杯
System.out.println(s1.length);//水杯能装10升的水
s1=new Student[20];//觉得10升少,去买了个20升的水杯
System.out.println(s1.length);//水杯能装20升的水了
}
}
s1=new Student[20]并不是改变了原数组的长度,而是重新在堆中创建了一个新的数组,把标签s1撕下来贴到了新数组上面而已。原来的数组长度并没有改变,没有标签的原数组内存空间会按照回收机制被回收。
如果对需要用的数组的长度不确定,有两种解决办法:
第一种:是在数组初始化的时候长度申请的足够大,但这样做会造成内存空间的浪费,一般不推荐使用。
第二种:用java中提供集合的方式存储数据,如List,Set和Map类型的对象存储数据,一方面这些类型的对象长度都是动态增长的,另一方面这些类中提供了很多便于操作数据的方法,因此在对所需存储数据的多少不确定的时候,第二种方法比第一种方法更优秀
数组的初始化
静态初始化:初始化时由程序猿显示指定每个数组元素的初始值,由系统决定数组的长度
动态初始化:在初始化的时候指定数组长度(这时已经分配内存)
//静态初始化
int[ ]arr = new int[ ]{1.4.7} //声明,创建,初始化
//静态初始化的分开写法
int[] arr ;//声明数组标识符
arr = new int[] {1,2,3,4,5};//创建数组对象,并初始化
//静态初始化的简单写法
int[] arr2 = {1,2,3,4,5};//这种不能分开写
int []arr;
arr = {1,4,7}//编译错误
//动态初始化
int[ ] arr = new int[3];//声明,创建---声明整型数组a,包含3个元素,每个元素都是int类型,默认值为0
arr[0] = 0;//初始化
arr[1] = 1;
arr[2] = 2;
数组的访问
通过(数组名 .length )可以获取数组的长度(元素的个数)
通过下标/索引来访问数组中的元素
下标从0开始,最大到(数组的长度-1)
int[ ]arr = new int[3];
System.out.println(arr.length);//3
System.out.println(arr.length-1); 输出最后一个元素的值。
arr[0];//代表arr中的第一个元素
arr[1];//代表arr中的第二个元素
arr[2];//代表arr中的第三个元素
arr[0]=100;//表示给arr第一个元素赋值100
//arr[3]=400;//数组下标越界异常 ArrayIndexoutof Bounds ExcePtion;
int[] arr;
System.out.println(arr.length);//数组空指针异常Null Pointer ExcePtion;
数组的遍历:
方法一:
int[ ] arr = new int[10];
for(int i =0;i<10;i++){//遍历arr数组
arr[i];//表示arr中的每一个元素
arr[i]=100;//给每个元素赋值为100
System.out.println(arr[i]);//输出每个元素的值
}
方法二:
int[] b = new int []{1,2,3,4,5}
for(int c:b) {//变量名:需要遍历的数组名
System.out.println(c);//输出变量名
}
数组的复制
方法一:
System.arraycopy(源数组,源下标,目标数组,目标下标,要复制元素个数)
int[] a = {10,20,30,40,50};
int[] b = new int[6]; //0,0,0,0,0,0
System.arraycopy(a, 1, b, 0, 4);
for(int i = 0; i<b.length;i++){
System.out.println(b[i]) // 20,30,40,50,0,0
}
/*
复制从a数组的第2元素开始复制4个元素到b数组的第一个元素
a-------源数组src
1-------源数组起始下标srcPos
b-------目标数组dest
0-------目标数组的起始下标destPos
4-------要复制的元素个数length
*/
方法二:
package test;
import java.util.Arrays;
public class Test{
public static void main(String[] args){
int[] a = {10,20,30,40,50};
Int[] b = Arrays.copyOf(a,3);//10,20,30
//a:源数组 b:目标数组 3:目标数组长度
for(int i = 0;i < b.length;i++) {
System.out.println(b[i]);
}
}
}
注意:
此方法源长度小于目标数组长度,则尾部补默认值,若大于则尾部截取
此方法不能选下标,也不能选个数----灵活性较差
数组的扩容/缩减:
所谓扩容是创建一个更大的新数组,并将源数组数据复制进去
package test;
import java.util.Arrays;
public class Test{
public static void main(String[] args){
int[] a = {10,20,30,40,50};
a = Arrays.copyOf(a,a.length+1);
//新数组 源数组,源数组长度上加1
for(int i = 0;i < a.length;i++) {
System.out.println(a[i]);//10,20,30,40,50,0
}
}
}
数组的排序:
升序(从小到大)降序(从大到小)
package test;
import java.util.Arrays;
public class Test {
public static void main(String[] args) {
int[] a = {30,40,10,20,60};
Arrays.sort(a);//对数组a进行升序排列
for(int i = 0;i < a.length;i++) {
System.out.println(a[i]);
}
for(int i = a.length-1;i>=0;i--){//反向遍历,降序排列
System.out.println(a[i]);
}
}
}
//降序排列
package exercises;
import java.util.Arrays;
import java.util.Collections;
//1. 利用Collections的reverseOrder
public class Test{
public static void main(String[] args){
//注意这里是Integer,不是int
Integer[] arr={9,8,7,6,5,4,3,2,1};
Arrays.sort(arr,Collections.reverseOrder());
for(int i:arr){
System.out.println(i);
}
}
}
方法:
函数、过程
1. 封装一段特定的业务逻辑功能
2. 尽可能独立,建议一个方法只干一件事
3. 方法可以被反复多次调用
4. 减少代码重复,有利于代码的维护
方法的定义(五个要素)
修饰词 返回值类型 方法名(参数列表){
方法体;
}
返回值类型:
方法可以有返回值,也可以没有返回值
- 无返回值:返回值类型写成void
- 有返回值:返回值类型写成特定的数据类型
何时有返回值?何时没用返回值?
方法执行完以后,若后期还需要用到方法中的某个数据-------有返回值
若后期不再需要用到方法中的某个数据-----无返回值
方法名:
- 命名要符合变量的命名规则(驼峰命名法),见名知意
参数列表:
- 方法中可以有参数,也可以没有参数
- 有参数可以使方法更加灵活,无参数意味着数据都是写死的
方法体:
- 具体的业务逻辑功能实现代码
方法的调用
- 无返回值:方法名(有参数传参数)
- 有返回值:数据类型 变量名 = 方法名(有参数传参数)
return 值; —— 用在有返回值的方法中
- 结束方法的执行
- 返回结果给调用方
return; —— 用在无返回值的方法中
- 只做结束方法的执行
package day0508;
//方法的演示
public class MathodDemo {
public static void main(String[] args) {
//无参无返回值
say();
//有参无返回值
// sayHi();编译错误,有参数则必须传参数
// sayHi(250);编译错误,参数类型必须匹配
sayHi("舒婳");//调用方法sayHi并给name赋值为舒婳,相当于String name="舒婳"
sayHello("舒婳",26);//相当于String name="舒婳",int age=27
//无参有返回值
int a = getNum();//有返回值的必须声明一个同类型变量去接收
System.out.println(a);
//有参有返回值
int b = plus(3,7);
System.out.println(b);
int m=3,n=5;
int c = plus(m,n);//传的不是m和n,而是m和n里面的那个数,m和n一般称之为实参(实际参数----有具体的值)上面的3,7也是
System.out.println(c);
}
//无参数无返回值
public static void say() {
System.out.println("安安小笨蛋");
}
//有参数无返回值
public static void sayHi(String name) {
System.out.println("大家好,我叫"+ name );
}
//提前结束方法的演示
public static void sayHello(String name,int age) {
if(age >= 35) {//在某种特定情况下,提前结束方法
return;//结束方法的执行
}
System.out.println(name + "今年" + age + "岁了");
}
//无参数有返回值
public static int getNum() {
//return;//编译错误,return后必须跟一个值
//return"abc";//编译错误,返回值类型必须匹配
return 10;//1)结束方法的执行,2)返回结果给调用方
//若方法有返回值,则方法中必须用return来返回,并且return后的值必须与返回值类型匹配
}
//有参数有返回值
public static int plus(int num1,int num2) {//num1和num2,一般称之为形参(形式参数---仅仅是个变量,没有值)
int sum = num1 + num2;
return sum;//返回的是sum里面的那个数
//return num1+num2;//返回的是num1和num2的和
}
方法的嵌套调用:
从方法中调方法
public class Test {
public static void main(String[] args) {
a();//111,222,333
}
public static void a() {
System.out.println("111");
b();
System.out.println("333");
}
public static void b() {
System.out.println("222");
}

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









