







函数参数
数组作为参数
数组名是第一个元素的地址,因此传给函数时,实际传递的是地址,因此定义函数时有两种形式。例如
int arr[] {1,2,3}
int sum(int array[]){// 这里实际上是arr地址
...
}
int sum(int* array){
}
int *array和 int array[]含义在函数定义中是相同的。
由于传递的是地址因此修改其中一项会影响原数组,传递地址减少拷贝原始数据的系统开销。
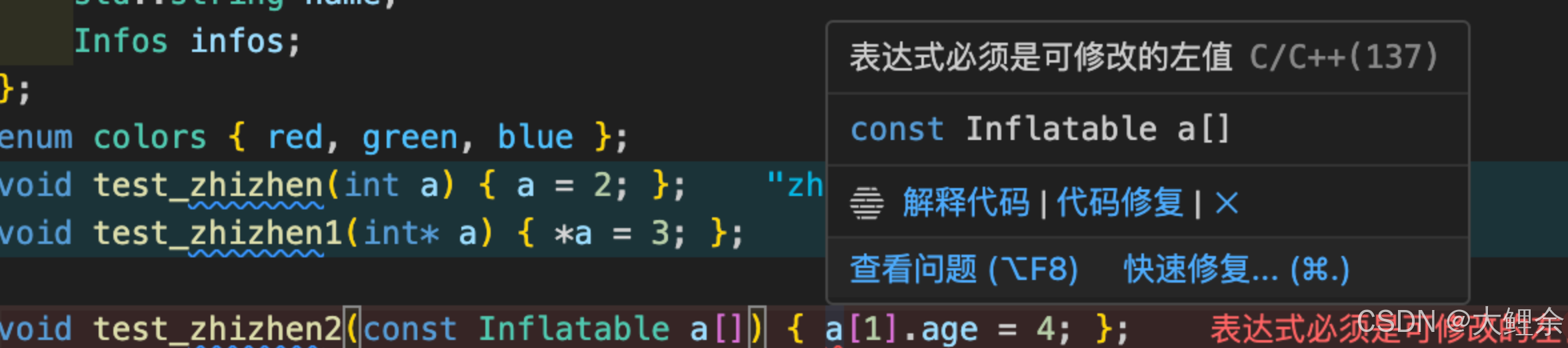
void test_zhizhen2(Inflatable a[]) { a[1].age = 4; };
struct Infos {
std::string address;
std::string email;
};
struct Inflatable {
int age;
std::string name;
Infos infos;
};
Inflatable inf[3] = {
{1, "a", {"地址1", "1331@1331.com"}},
{2, "b", {"地址1", "1331@1332.com"}},
{3, "c", {"地址1", "1331@1333.com"}},
};
cout << inf[1].age << endl; //2
test_zhizhen2(inf);
cout << inf[1].age << endl; //4
如果想避免修改原数组,可以在参数类型前加const。
const
const参数
在函数参数中使用 const 修饰指针,表示指针指向的内容是常量,不可修改。我们希望声明一个带有参数的函数,并明确表明该函数不会修改传入的参数的值。这时可以使用 const 修饰函数的参数。在函数声明和定义中,将参数声明为 const表示该参数是只读的,即函数内部不能修改这个参数的值。这样的声明和定义使得函数更安全,因为它确保了在函数内部不会无意间修改传入的参数。
可以将const修饰的参数理解为ts中的readonly只读
const常量函数
被const修饰的函数不能显示修改内部的变量,且只能调用同样被const修饰的函数。
void baseFunction() const
{
this->name = "asd";// 报错
std::cout << this->name << std::endl;
}
函数指针
C++的函数指针是为了实现函数式编程,使得函数称为一等公民,让用户能够通过高阶函数维护代码。即通过传递函数的地址,让函数可以接受 或返回函数的地址,实现高阶函数的函数调用。
声明指向函数的指针时也必须要指定指针类型。
函数指针的类型建议使用typedef去定义来简化声明。
高阶函数-参数为函数
int sum2(int a, int b) { return a + b + 2; }
//函数范围类型 (*函数名)(参数类型, 参数类型)
int test_callback(int a, int b, int (*cb)(int, int)) {
return a + b + cb(a, b);
}
cout << test_callback(2, 3, &sum2) << endl;
高阶函数返回值为函数
int sum2(int a, int b) { return a + b + 2; }
// 定义一个返回函数指针的函数
int (*test_return_cb())(int, int) { return &sum2; }
int (*sum_cb)(int, int) = test_return_cb();
cout << sum_cb(3, 4) << endl; // 9
内联函数
内联函数是为了提升程序运行速度的一项改进。为什么? 我们知道程序最终会被编译为机器语言指令,程序运行时操作系统会将这些指令放到内存中,每条指令都有对应的内存地址,对于循环和分支语句会执行向前/向后跳到特定地址的操作,当程序执行常规函数时程序会从一个地址跳到另一个地址,并在函数结束时返回,此外如果函数有返回值还需要将函数的返回值放到寄存器中,**这样来回跳转和记录跳跃位置都需要开销。**而内敛函数c++编译器会将相应内联函数代码块替换函数调用,内联函数运行速度快,但会占用更多内存(因为如果程序中10个地方调用内敛函数,则这10个地方将包含函数10个副本。)
inline int sum(int a ,int b){ return a+b; }
Lambda表达式
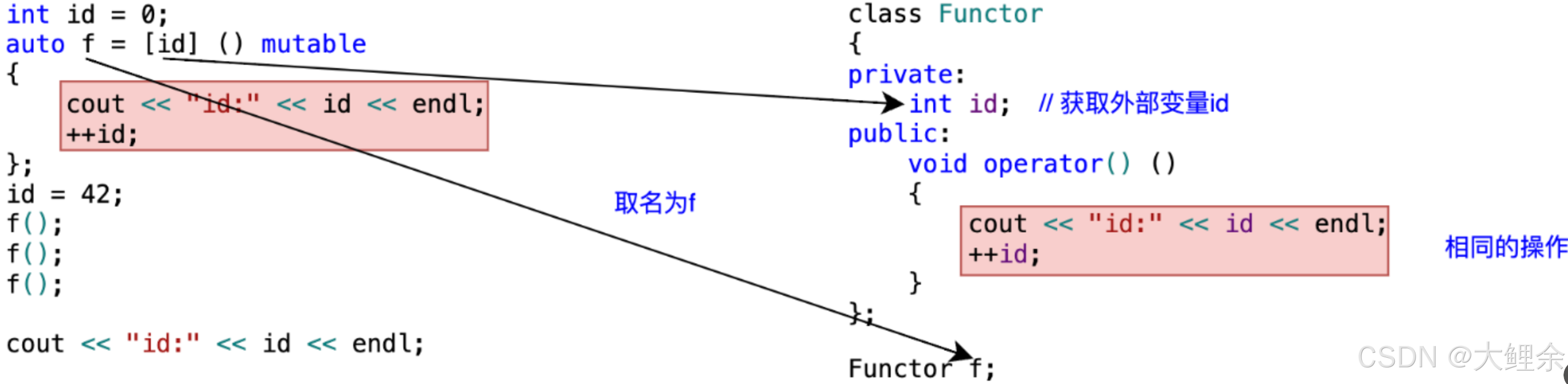
Lambda 表达式(通常称为 Lambda)是一种在被调用的位置或作为参数传递给函数的位置定义匿名函数对象(闭包)的简便方法。
lambda表达式实际上是一个匿名类的成员函数,该类由编译器为lambda创建,该函数被隐式地定义为内联。lambda表达式的一般形式是:[capture clause] (parameters) mutable -> return-type { function body }
[captureclause]:捕捉列表。该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略。
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
->return-type:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可以省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
int main()
{
int id = 0;
auto f = [id] () mutable // mutable表示可以修改捕捉的变量,那么也就可以执行自增语句
{
cout << "id:" << id << endl;
++id;
};
id = 42;
f(); // 0
f(); // 1
f(); // 2
cout << "id:" << id << endl;//42
}
lambda表达式会将id进行拷贝,以类似于闭包形式访问外部变量id
示例二:去掉了mutable,以传引用方式捕捉变量,新增参数param。
int main()
{
int id = 0;
auto f = [&id] (int param)
{
cout << "id:" << id << ", ";
cout << "param:" << param << endl;
++id; // 编译报错 -》不能赋值给一个非可变的(non-mutable)变量
++param;
};
id = 42;
f(7); // id:42, param:7
f(7); // id:43, param:7
f(7); // id:44, param:7
cout << "id:" << id << endl; // id:45
return 0;
}
//[&id],表示以引用方式捕捉变量id。那么匿名函数内部和外界处理的变量id就是同一个,函数内部和外部都会互相影响。因此在调用lambda表达式之前变量id被更新为42仍然会影响lambda表达式内部。
// 参数param是值传递,每次传值都是一次临时拷贝。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











