







报错原文:
2024-12-28 00:11:33.375 [parallel-11] INFO d.c.b.a.s.s.StatusUpdater - [logError,127] - Couldn't retrieve status for Instance(id=9443b6016116, version=2, registration=Registration(name=gmall-admin, managementUrl=http://192.168.10.7:20100/actuator, healthUrl=http://192.168.10.7:20100/actuator/health, serviceUrl=http://192.168.10.7:20100, source=discovery), registered=true, statusInfo=StatusInfo(status=UP, details={reactiveDiscoveryClients={status=UP, details={Simple Reactive Discovery Client={status=UP, details={services=[]}}}}, mail={status=UP, details={location=smtp.163.com:465}}, nacosConfig={status=UP}, diskSpace={status=UP, details={total=1024191361024, free=429419630592, threshold=10485760, exists=true}}, ping={status=UP}, discoveryComposite={status=UP, details={discoveryClient={status=UP, details={services=[service-gateway, service-item, service-product, gmall-admin, web-all]}}}}, refreshScope={status=UP}, nacosDiscovery={status=UP}}), statusTimestamp=2024-12-27T16:11:07.687Z, info=Info(values={}), endpoints=Endpoints(endpoints={caches=Endpoint(id=caches, url=http://192.168.10.7:20100/actuator/caches), loggers=Endpoint(id=loggers, url=http://192.168.10.7:20100/actuator/loggers), logfile=Endpoint(id=logfile, url=http://192.168.10.7:20100/actuator/logfile), nacosconfig=Endpoint(id=nacosconfig, url=http://192.168.10.7:20100/actuator/nacosconfig), health=Endpoint(id=health, url=http://192.168.10.7:20100/actuator/health), refresh=Endpoint(id=refresh, url=http://192.168.10.7:20100/actuator/refresh), env=Endpoint(id=env, url=http://192.168.10.7:20100/actuator/env), nacosdiscovery=Endpoint(id=nacosdiscovery, url=http://192.168.10.7:20100/actuator/nacosdiscovery), heapdump=Endpoint(id=heapdump, url=http://192.168.10.7:20100/actuator/heapdump), features=Endpoint(id=features, url=http://192.168.10.7:20100/actuator/features), scheduledtasks=Endpoint(id=scheduledtasks, url=http://192.168.10.7:20100/actuator/scheduledtasks), mappings=Endpoint(id=mappings, url=http://192.168.10.7:20100/actuator/mappings), archaius=Endpoint(id=archaius, url=http://192.168.10.7:20100/actuator/archaius), beans=Endpoint(id=beans, url=http://192.168.10.7:20100/actuator/beans), configprops=Endpoint(id=configprops, url=http://192.168.10.7:20100/actuator/configprops), threaddump=Endpoint(id=threaddump, url=http://192.168.10.7:20100/actuator/threaddump), metrics=Endpoint(id=metrics, url=http://192.168.10.7:20100/actuator/metrics), conditions=Endpoint(id=conditions, url=http://192.168.10.7:20100/actuator/conditions), service-registry=Endpoint(id=service-registry, url=http://192.168.10.7:20100/actuator/service-registry), info=Endpoint(id=info, url=http://192.168.10.7:20100/actuator/info)}), buildVersion=null, tags=Tags(values={}))
java.util.concurrent.TimeoutException: Did not observe any item or terminal signal within 10000ms in 'map' (and no fallback has been configured)
at reactor.core.publisher.FluxTimeout$TimeoutMainSubscriber.handleTimeout(FluxTimeout.java:288)
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
Error has been observed at the following site(s):
|_ checkpoint ⇢ Request to GET health [DefaultWebClient]
Stack trace:
at reactor.core.publisher.FluxTimeout$TimeoutMainSubscriber.handleTimeout(FluxTimeout.java:288)
at reactor.core.publisher.FluxTimeout$TimeoutMainSubscriber.doTimeout(FluxTimeout.java:273)
at reactor.core.publisher.FluxTimeout$TimeoutTimeoutSubscriber.onNext(FluxTimeout.java:395)
at reactor.core.publisher.StrictSubscriber.onNext(StrictSubscriber.java:89)
at reactor.core.publisher.FluxOnErrorResume$ResumeSubscriber.onNext(FluxOnErrorResume.java:73)
at reactor.core.publisher.MonoDelay$MonoDelayRunnable.run(MonoDelay.java:117)
at reactor.core.scheduler.SchedulerTask.call(SchedulerTask.java:68)
at reactor.core.scheduler.SchedulerTask.call(SchedulerTask.java:28)
at java.util.concurrent.FutureTask.run$$$capture(FutureTask.java:266)
at java.util.concurrent.FutureTask.run(FutureTask.java)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
连接超时的情况只发生在监控自身服务上,具体原因尚不清楚,由报错信息可知,默认超时时间为10s
解决方案:
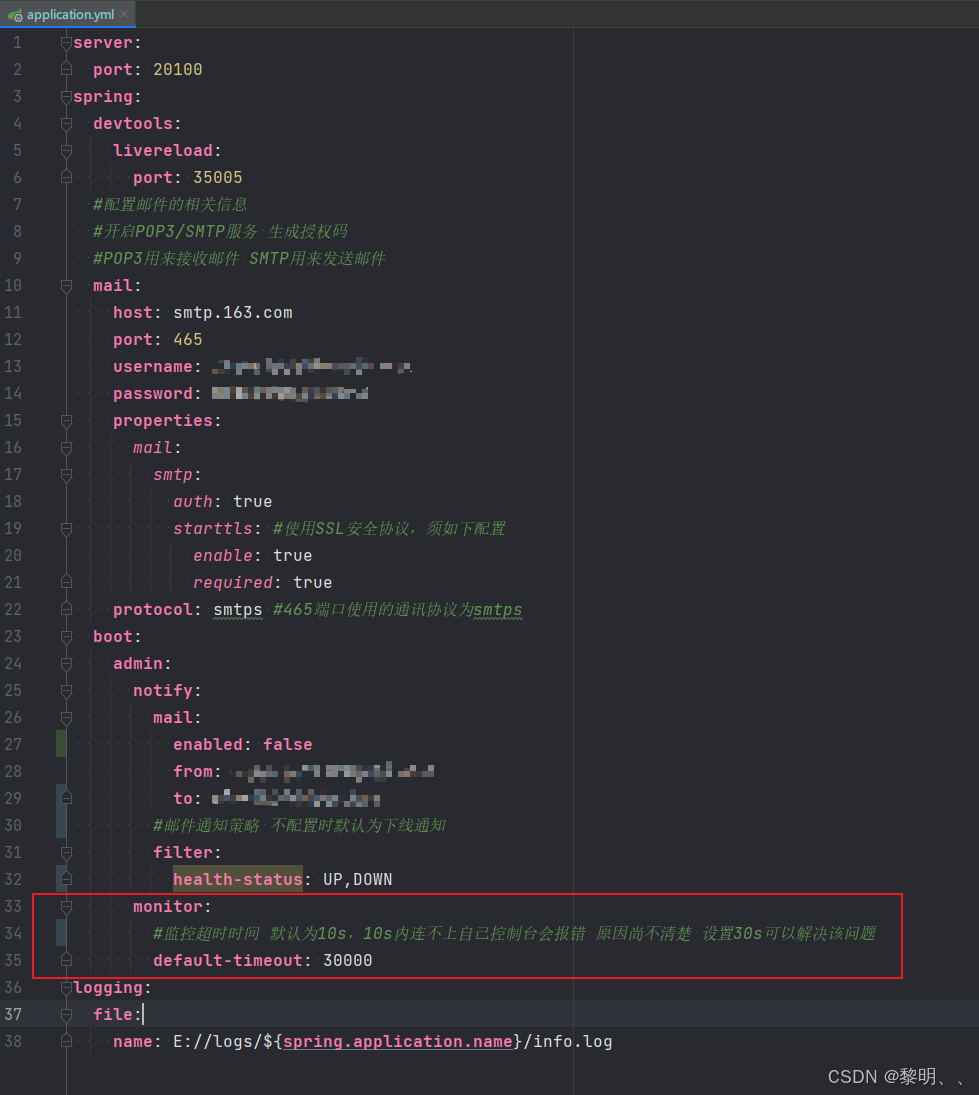
添加监控超时时间配置,设置30s可以解决该问题
网上也有其他方案:https://blog.youkuaiyun.com/muyiyangyang/article/details/109482314,但实测无法解决,也可能和我环境有关


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









