







 本文介绍了网络请求的基础知识,包括GET和POST的区别、URL解析、User-Agent和Referer的作用。详细讲解了状态码及其意义,并探讨了抓包工具的使用。此外,文章深入讨论了Python内置库urllib的功能,包括urllib.request的headers参数设置方法,以及urllib.parse的url编码应用。最后,通过构建URL和项目实操展示了如何利用这些知识进行实际的网络请求操作。
本文介绍了网络请求的基础知识,包括GET和POST的区别、URL解析、User-Agent和Referer的作用。详细讲解了状态码及其意义,并探讨了抓包工具的使用。此外,文章深入讨论了Python内置库urllib的功能,包括urllib.request的headers参数设置方法,以及urllib.parse的url编码应用。最后,通过构建URL和项目实操展示了如何利用这些知识进行实际的网络请求操作。
文章目录
第二章 网络请求模块
1. 几个概念
1.1 get和post
爬虫有两种主要的请求方式就是get和post,get的请求方式,请求参数都会在url里面显示出来,而post则不会。一般post会对服务器数据产生影响,比如登录的时候会提交账户和密码,这个时候需要用post请求。
1.2 全球统一资源定位符
通称URL
例如下面是一个新闻网页的url:
https://news.cctv.com/2020/12/13/ARTILDC3agyCVhXCYNdc8Alu201213.shtml?spm=C94212.P4YnMod9m2uD.E7v7lEZZ0WEM.4
我们研究一下他的组成部分
http: 协议
news.cctv.com: 主机名 这里省略了一个端口443
2020/12/13/ARTILDC3agyCVhXCYNdc8Alu201213.shtml?spm=C94212.P4YnMod9m2uD.E7v7lEZZ0WEM.4 这是我们所访问资源的一个路径
anchor 拓展,这个是锚点,做导航的,定位到某个目录 (拓展知识点)
浏览器去请求一个url的时候,除了英文字母,数字和部分符号外,其他的都采用%加16进制来进行编码。因为网站只能识别ascall码。如果携带中文的时候,会被编码。
1.3 User-Agent
用户代理,记录了用户的操作系统,浏览器版本等信息,为了让用户获得更好的页面浏览效果。爬虫时将User-Agent作为header加入,会增加成功率。
User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0
Gecko 这个时指浏览器的内核
1.4 Referer
我们在header里面还发现了Referer: https://www.lagou.com/这是一个跳转记录,显示本页面是由哪个页面跳转来的。也是和反爬虫有关的,如果你请求的时候,没有这个元素,则服务器认为你是爬虫程序,而不是从浏览器跳转来到这个页面的。所以这个元素也要添加到header里面,可以增加请求的成功率。
当然,后面还有关于Cookie、seccion等中还要知识点,后面专题来讲。
2. 状态码
200 请求成功
301 永久重定向
302 临时重定向
404 服务器无法响应
500 服务器内部请求
3. 抓包工具里的选项
elements: 元素,网页源代码,用于提取数据和分析数据(注意,有些数据是经过处理的,并不准确)
Console: 控制台,可以编码,打印信息。
Sources: 是整个网站资源的加载来源。
Network: 可以看见很多的请求信息,可以用来分析数据接口
4. urllib
- 有些比较老的爬虫项目用的还是urllib技术,如果没有见过,你不知道怎么更新。
- 有时候在爬取有些数据的时候,需要urllib+requests一起使用的。
- 而且urllib是内置的。
- urllib在某些方面作用还是比较强大的。
基于以上四个原因,我们还是有必要学习一下urllib
下面我爬取一张图片
import requests
url = 'https://c-ssl.duitang.com/uploads/item/202007/19/20200719141153_kyfng.jpg'
res = requests.get(url)
tu = open(r'C:\Users\MI\OneDrive\桌面\pic.jpg','wb')
tu.write(res.content)
tu.close()
执行结果是在我的桌面上出现了一张名为pic的图片。
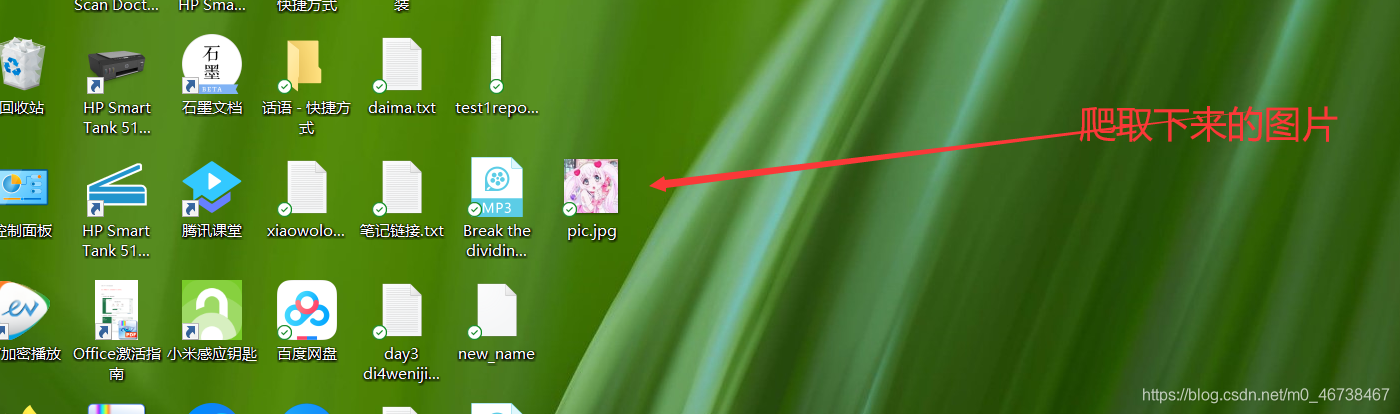
当然,也可以这样子写:
import requests
url 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









