







文章目录
- 1.基础知识
-
- 1.1 基本想法
- 1.2 主要性质及定理
-
- 1.2.1 主成分的表示方法
- 1.2.2 主成分的总体性质
- 1.2.3 什么是因子负荷量
- 1.2.4 主成分的方差贡献率
- 1.3 规范化变量的总体主成分与样本主成分步骤
- 1.4 举例理解主成分分析
- 2. python代码实现PCA
-
- 2.1 手动实现PCA
-
- 2.1.0 导入所需库包和数据集
- 2.1.1 数据规范化处理
- 2.1.2 计算相关矩阵
- 2.1.3 求相关矩阵的特征值及其对应的单位特征向量
- 2.1.4 主成分的累计方差贡献率
- 2.1.5 主成分的分析结果
- 2.1.6 主成分的因子负荷量
- 2.1.7 将数据投影到新特征上
- 2.2 scikit-learn实现PCA
-
- 2.2.1 StandardScaler标准化处理
- 2.2.2 利用sklearn.decomposition的 PCA降维
- 2.2.3 原始数据在新特征上的展现
最近在学习李航老师的《统计学习方法》第16章-主成分分析(PCA),结合运用python代码实现,记录一下。
1.基础知识
1.1 基本想法



1.2 主要性质及定理
1.2.1 主成分的表示方法

1.2.2 主成分的总体性质

1.2.3 什么是因子负荷量


1.2.4 主成分的方差贡献率

1.3 规范化变量的总体主成分与样本主成分步骤
总体主成分分析是定义在样本总体上的。在实际问题中,需要在观测数据上进行主成分分析,这就是样本主成分分析。

假设对m维随机变量【既有m个特征变量】进行n次独立观测,下面的m、n 同假设。


1.4 举例理解主成分分析


2. python代码实现PCA
2.1 手动实现PCA
参考的一些优秀的文章
如何通俗理解PCA(主成分分析)算法的数学原理和代码实现
Python机器学习——主成分分析PCA
审稿人:PCA的误区就是"分类",但Python可以画得很漂亮!
2.1.0 导入所需库包和数据集
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from matplotlib.patches import Ellipse
import seaborn as sns
plt.rcParams['font.sans-serif'] = ['SimHei']#解决图表中中文显示问题
plt.rcParams['axes.unicode_minus']=False# 解决图表中负号不显示问题
import warnings
warnings.filterwarnings("ignore")
# 设置Seaborn风格
sns.set(style="whitegrid", palette="muted", font_scale=1.2)
# 加载Iris数据集
data = load_iris()
X = data.data # 特征矩阵
y = data.target # 标签
target_names = data.target_names
2.1.1 数据规范化处理
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,stratify=y,random_state=0)
# 标准化
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.transform(X_test)
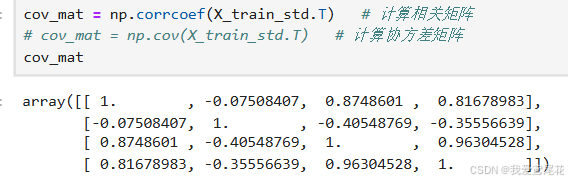
2.1.2 计算相关矩阵


由于这里已经把数据做了标准化,所以下面计算一下相关矩阵,
cov_mat = np.corrcoef(X_train_std.T) # 计算相关矩阵
# cov_mat = np.cov(X_train_std.T) # 计算协方差矩阵
cov_mat
2.1.3 求相关矩阵的特征值及其对应的单位特征向量
#计算相关矩阵的特征值和特征向量
eigen_vals,eigen_vecs = np.linalg.eig(cov_mat)
eigen_vals_sorted =eigen_vals [np.argsort(-eigen_vals)] # 把特征值从大到小排序
print('特征值从大到小排序',eigen_vals_sorted,'\n')
eigen_pairs = [(np.abs(eigen_vals[i]), eigen_vecs[:, i]) for i in range(len</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









