






 本文详细介绍了MySQL数据查询的各种操作,包括基本查询语句、单表查询、多表查询、连接查询、子查询以及各种查询条件如WHERE、LIKE、BETWEEN等。通过实例解析了如何使用SELECT语句进行字段筛选、数据分组、排序和过滤,帮助读者掌握数据库查询技巧。
本文详细介绍了MySQL数据查询的各种操作,包括基本查询语句、单表查询、多表查询、连接查询、子查询以及各种查询条件如WHERE、LIKE、BETWEEN等。通过实例解析了如何使用SELECT语句进行字段筛选、数据分组、排序和过滤,帮助读者掌握数据库查询技巧。
数据库管理系统的一个最重要的功能就是数据查询,数据查询不应只是简单查询数据库中存储的数据,还应该 根据需要对数据进行筛选,以及确定数据以什么样的格式显示。MySQL提供了功能强大、灵活的语句来实现这 些操作。
基本查询语句
mysql从数据表中查询数据的基本语句为select语句。select语句的基本格式是:
SELECT {* | } [ FROM , .... [ where ] [ group by ] [ having ] [ order by ] [ limit ]
{*|}包含星号通配符选择字段列表,表示查询的字段,其中字段列至少包含一个字段名称,如 果要查询多个字段,多个字段之间用逗号隔开,最后一个字段后不要加逗号。
FROM,...:表1和表2表示查询数据的来源,可以是单个或多个。
WHERE子句是可选项,如果选择该项,将限定查询必须满足的查询条件。
GROUP BY,该子句告诉MySQL按什么样的顺序显示查询出来的数据,可以进行的排序有:升序 (asc)、降序(desc)。
[limit],该子句告诉mysql每次显示查询出来的数据条款。
我们先创建个表,来做我们的实验。

查点数据进去。
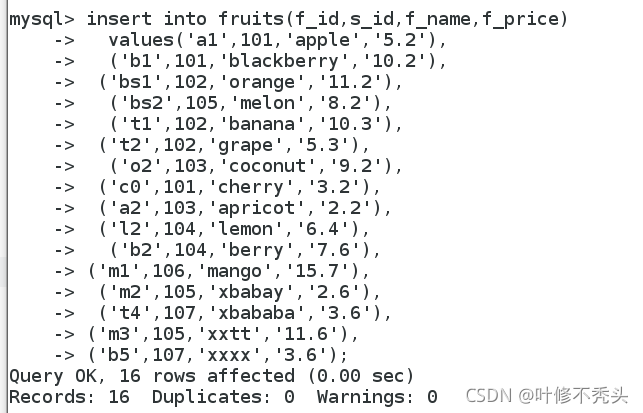
1 单表查询
查看表的全部数据。 语句: select * from 表面;
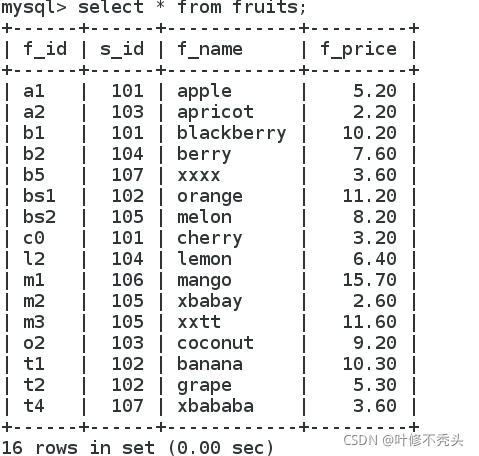
2 查询指定字段
语句:select 字段名 from 表名;

查询多个字段
查询多个字段 使用select声明,可以获取多个字段下的数据,只需要在关键字select后面指定要查询的字 段的名称,不同字段名称之间用逗号分隔,最后一个字段后面不需要加逗号
语句:select 字段1,字段2,字段3 ....,字段n from 表名;
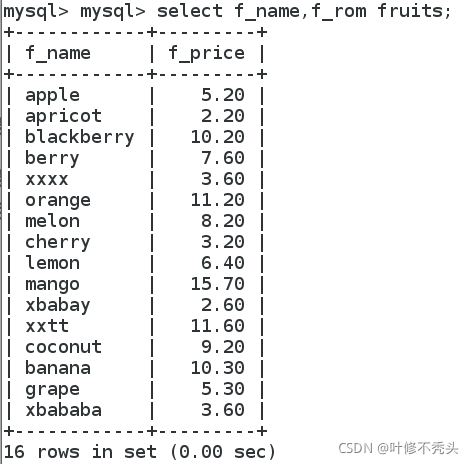
查询指定记录
数据库中包含大量的数据,根据特殊要求可能只需要查询表中的指定数据,相当于对数据的过滤。在select语句 中,通过where子句可以对数据进行过滤。\

select 字段1,字段2....字段n from 表名 where 查询条件;


带in关键字的查询
in操作符用来查询满足指定范围内的条件的记录,使用IN操作符,将所有检索条件用括号括起来,检索条件之 间用逗号分隔开。只要满足条件范围内的一个值即为匹配项。
语句 select 字段1,字段2,.... from 表明 where 查询的列的字段 in (你要查询的数据1,2,3) order by 字段;

带between and的范围查询
Between and用来查询某个范围内的值,该操作符需要两个参数,即范围的开始值和结束值,如果字段值满足 指定的范围查询条件,则这些记录被返回。
语句 select 字段1,字段2,... from 表名 where 查询字段名 between 范围1 and 范围2;


带like的字符匹配查询
通配符是一种在SQL的where条件子句中拥有特殊意思的字符,SQL语句中支持多种通配符,可以和like一起使 用的通配符有‘%’和‘_’。
百分号(%)通配符,匹配任意长度的字符,甚至包括零字符
下划线(__)通配符,一次只能匹配任意一个字符


查询空值
数据表创建的时候,设计者可以指定某列中是否可以包含空值(NULL)。空值不同于0,也不同于空字符串。空 值一般表示数据未知、不适用或将在以后添加数据。在select语句中使用IS NULL子句,可以查询某字段内容为 空的记录。
语句 select 字段1,字段2,.... from 表明 where 你要查询列的字段 is null;

这里显示我这是没有加null,想学添加约束删除的可以看这个。(24条消息) centos7mysql数据库表的添加约束和删除_m0_46648661的博客-优快云博客
带and的多条件查询
使用select查询时,可以增加查询的限制条件,这样可以使查询的结果更加精确。MySQL在where子句中使用 and操作符限定只有满足所有查询条件的记录才会被返回。可以使用and连接两个甚至多个查询条件,多个条件 表达式之间用and分开。

带or的多条件查询
与and相反,在where声明中使用or操作符,表示只需要满足其中一个条件的记录即可返回。or也可以连接两个 甚至多个查询条件,多个条件表达式之间用or分开。

查询结果不重复


单列排序
语句:select 字段 from表名 order by 显示的字段;

多列排序
语句:select 字段1,字段2 from表名 order by 显示的字段1,显示的字段2;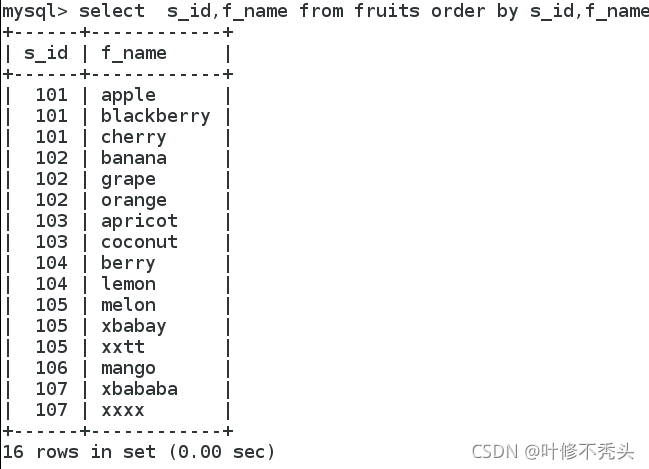
指定排序方向
默认情况下,查询数据按字母升序进行排序(从A~Z),但数据的排序并不仅限于此,还可以使用order by对查 询结果进行降序排序(从Z~A),这可以通过关键字DESC实现,与DESC相反ASC是升序。

分组查询
分组插叙是对数据按照某个或多个字段进行分组,MySQL中使用group by关键字对数据进行分组,基本语法形 式为:group by 字段 1、创建分组 Group by 关键字通常和集合函数一起使用,例如:MAX()、MIN()、COUNT()、SUM()、AVG()。 根据s_id对 fruits表中的数据进行分组
语句:select 字段,count(*) as 起个名字 from 表名 group by 字段;
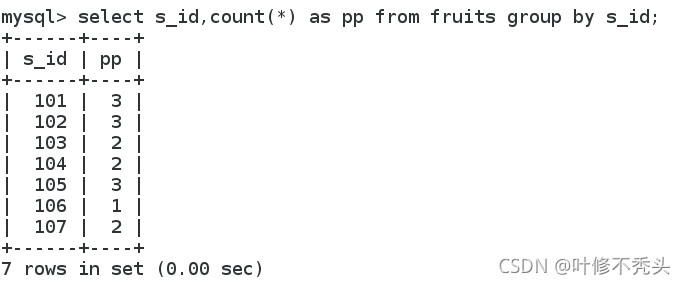
这里看到101里面有3个,102也是3个......这里就分组了,相同的数据是一组。
根据s_id对fruits表中的数据进行分组,将每个供应商的水果名称显示出来
语句:select 字段,group_concat(字段) as 起个名字 from 表名 group by 字段;
 使用having过滤分组 根据s_id对fruits表中的数据进行分组,并显示水果种类大于1的分组信息
使用having过滤分组 根据s_id对fruits表中的数据进行分组,并显示水果种类大于1的分组信息

在group by 子句中使用with rollup 使用with rollup关键字之后,在所有查询出的分组记录之后增加一条记 录,该记录计算查询出的所有记录的总和,即统计记录数量。
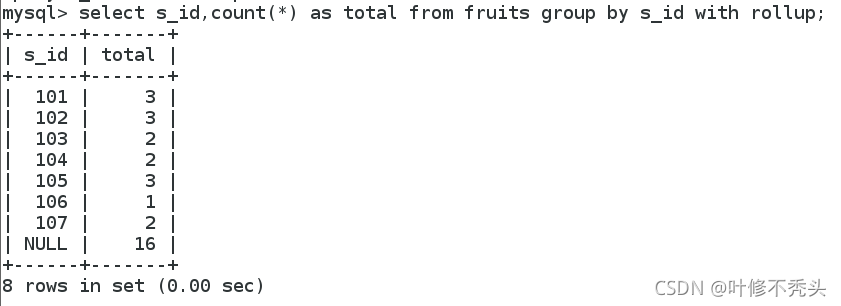
连接查询
连接是关系数据库模型的主要特点。连接查询是关系数据库中最主要的查询,主要包括内连接、外连接。通过 连接运算符可以实现多个表查询。在关系数据库管理系统中,表建立时各数据之间的关系不必确定,常把一个 实体的所有信息存放在一个表中。当查询数据时,通过连接操作查询出存放在多个表中的不同实体的信息。当 两个或多个表现中存在相同意义的字段时,便可以通过这些字段对不同的表进行连接查询。
内连接查询
内连接(inner join)使用比较运算符进行表间某些列数据的比较操作,并列出这些表中与连接条件相匹配的数 据行,组合成新纪录,也就是说,在内连接查询中,只有满足条件的记录才能出现在结果关系中。
先创建个表,用作我们的实验
create table suppliers
(
s_id int not null auto_increment,
s_name char(50) not null,
s_city char(50) null,
s_zip char(10) null,
s_call char(50) not null,
primary key(s_id)
);

insert into suppliers(s_id,s_name,s_city,s_zip,s_call)
values(101,'FastFruit Inc.','tianjin','300000','48075'),
(102,'LT Supplies','chongqing','400000','44333'),
(103,'acme','shanghai','200000','90046'),
(104,'fnk inc.','zhongshan','528437','11111'),
(105,'good set','taiyuang','030000','22222'),
(106,'just eat ours','beijing','010','45678'),
(107,'dk inc.','zhengzhou','450000','33332');

如果在一个连接查询中,涉及的两个表都是同一个表,这种查询称为自连接查询。自连接是一种特殊的内连 接,它是指相互连接的表在物理上为同一张表,但可以在逻辑上分为两张表。
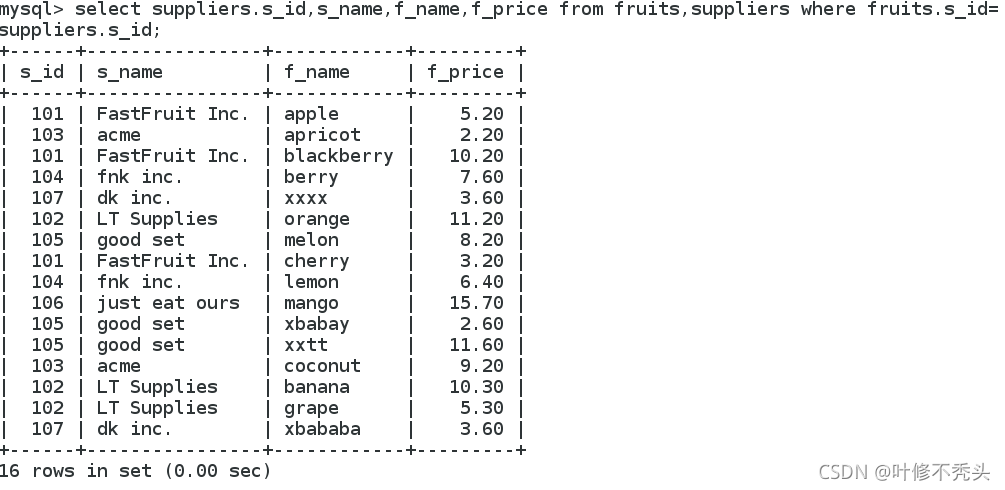
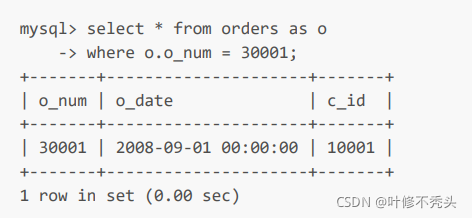
注意:连接查询必须用表名.字段声明不然找不到(.)。
语句: select a表明.字段,b字段,b字段 from b表名 , a表名 where b表名.字段=a表名.字段;
 如果在一个连接查询中,涉及的两个表都是同一个表,这种查询称为自连接查询。自连接是一种特殊的内连 接,它是指相互连接的表在物理上为同一张表,但可以在逻辑上分为两张表。
如果在一个连接查询中,涉及的两个表都是同一个表,这种查询称为自连接查询。自连接是一种特殊的内连 接,它是指相互连接的表在物理上为同一张表,但可以在逻辑上分为两张表。

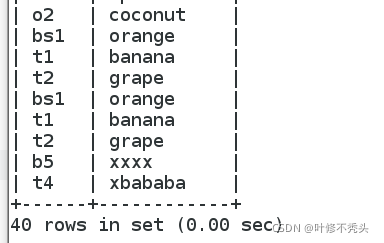
我们先分开验证看看这个是怎么得出来的,太多了,就截个头和尾部把。

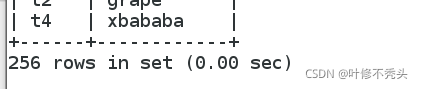
这里可以看到叉开是256条,本来我们是16条它每条都打印了16次所以是256我们继续。

外连接查询
外连接查询将将查询多个表中相关联的行,内连接时,返回查询结果集合中的仅是符合查询条件和连接 条件的行。但有时候需要包含没有关联的行中数据,即返回查询结果集合中的不仅包含符合连接条件的 行,而且还包含左表(左外连接或左连接)、右表(右外连接或右连接)或两个连接表(全外连接)中 的所有数据行。外连接分为左外连接或左连接和右外连接或右连接。
Left join(左连接):返回包括左表中的所有记录和右表中连接字段相等的记录。 Right join(右连接):返回 包括右表中的所有记录和左表中连接字段相等的记录。
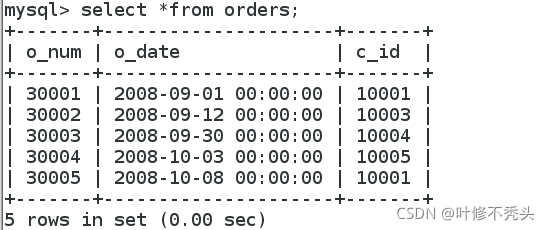
我们先创建个表。
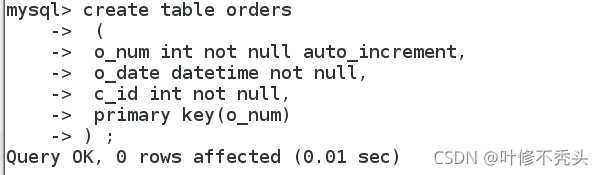
create table orders
(
o_num int not null auto_increment,
o_date datetime not null,
c_id int not null,
primary key(o_num)
) ;

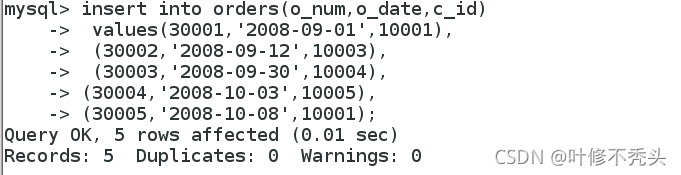
insert into orders(o_num,o_date,c_id)
values(30001,'2008-09-01',10001),
(30002,'2008-09-12',10003),
(30003,'2008-09-30',10004),
(30004,'2008-10-03',10005),
(30005,'2008-10-08',10001);
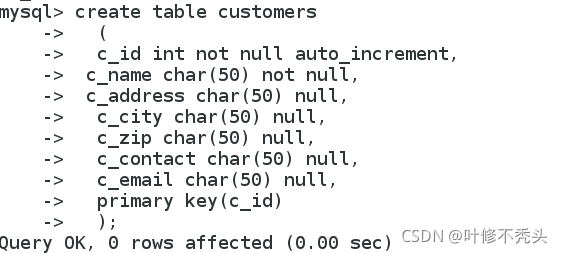
create table customers
(
c_id int not null auto_increment,
c_name char(50) not null,
c_address char(50) null,
c_city char(50) null,
c_zip char(50) null,
c_contact char(50) null,
c_email char(50) null,
primary key(c_id)
);
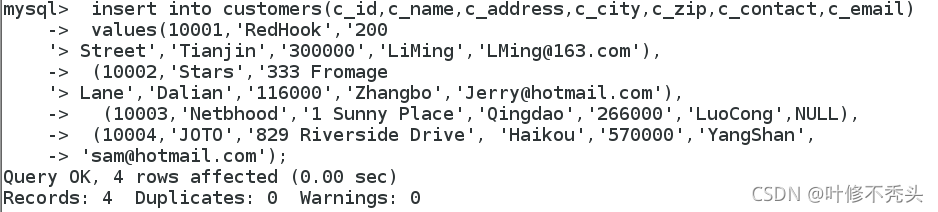
insert into customers(c_id,c_name,c_address,c_city,c_zip,c_contact,c_email)
values(10001,'RedHook','200
Street','Tianjin','300000','LiMing','LMing@163.com'),
(10002,'Stars','333 Fromage
Lane','Dalian','116000','Zhangbo','Jerry@hotmail.com'),
(10003,'Netbhood','1 Sunny Place','Qingdao','266000','LuoCong',NULL),
(10004,'JOTO','829 Riverside Drive', 'Haikou','570000','YangShan',
'sam@hotmail.com');
左连接:Left join

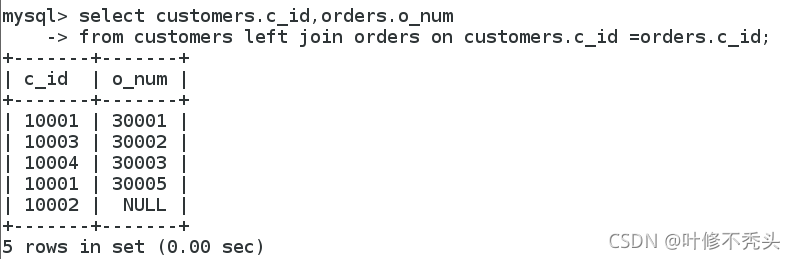
返回包括左表中的所有记录和右表中连接字段相等的记录
右连接
Right join

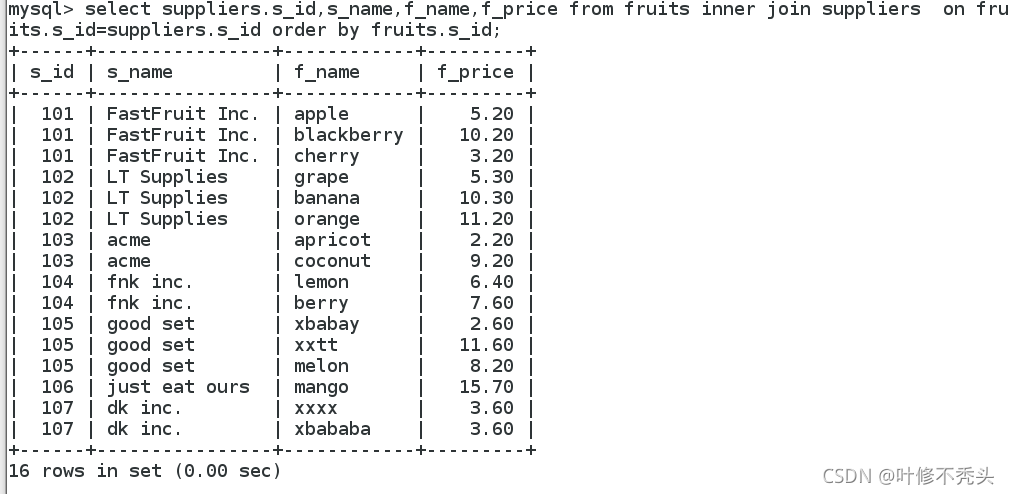
复合条件连接查询
inner join
复合条件连接查询是在连接查询的过程中,通过添加过滤条件,限制查询的结果,使查询的结果更加准确。

 子查询
子查询
子查询指一个查询语句嵌套在另一个查询语句内部的查询,这个特性从mysql4.1开始引入。在select子句中先计 算子查询,子查询结果作为外层另一个查询的过滤条件,查询可以基于一个表或者多个表。子查询中常用的操 作符有any(some)、all、in、exists。子查询可以添加到select、update和delete语句中,而且可以进行多层嵌 套。子查询中也可以使用比较运算符,如“”,“>=”和“!=”等。
带any、some关键字的子查询
any和some关键字是同义词,表示满足其中任一条件,它们允许创建一个表达式对子查询的返回值列进行比 较,只要满足内层子查询中的任何一个比较条件,就返回一个结果作为外层查询的条件。

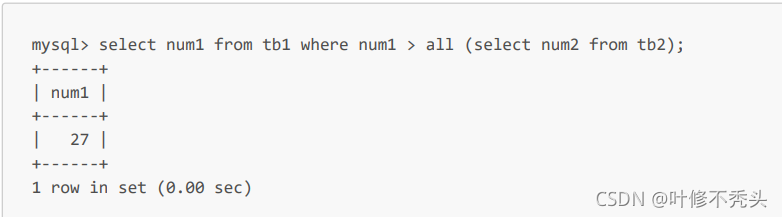
带all关键字的子查询
all关键字与any和some不同,使用all时需要同时满足所有内层查询的条件。
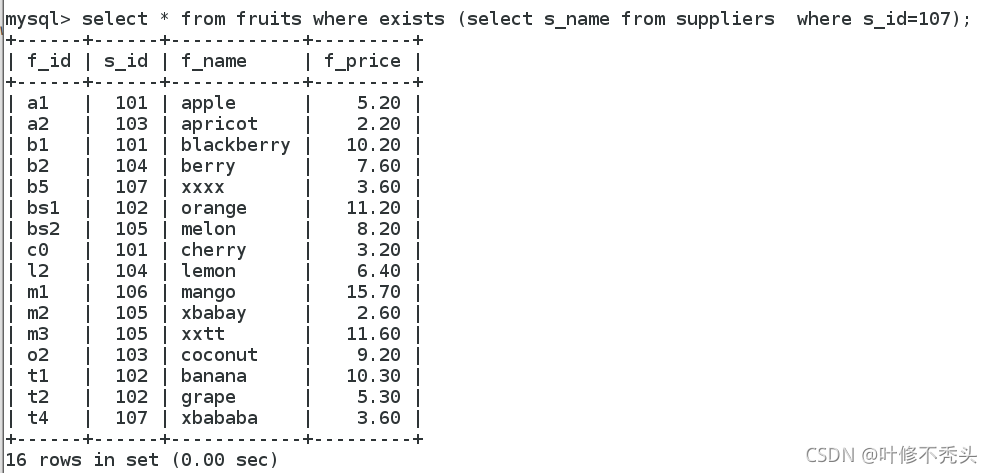
带exists关键字的子查询
exists关键字后面的参数是一个任意的子查询,系统对子查询进行运算以判断它是否返回行,如果至少返回一 行,那么exists的结果为true,此时外层查询语句将进行查询;如果子查询没有返回任何行,那么exists返回的 结果是false,此时外层语句将不进行查询。
右边是真的,所以左边可以执行。
带in关键字的子查询
in关键字进行子查询时,内层查询语句仅仅返回一个数据列,这个数据列里的值将提供给外层查询语句 进行比较操作。

带比较运算符的子查询

合并查询结果
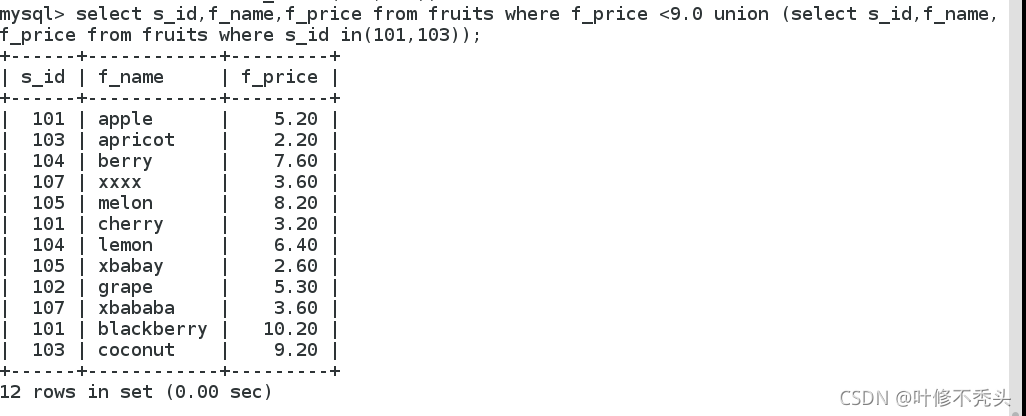
利用union关键字,可以给出多条select语句,并将它们的结果组合成单个结果集。合并时,两个表对应的列数 和数据类型必须相同。各个select语句之间使用union或union all关键字分隔。union不使用关键字all,执行的时 候删除重复的记录,所有返回的行都是唯一的;使用关键字all的作用是不删除重复行也不对结果进行自动排 序。
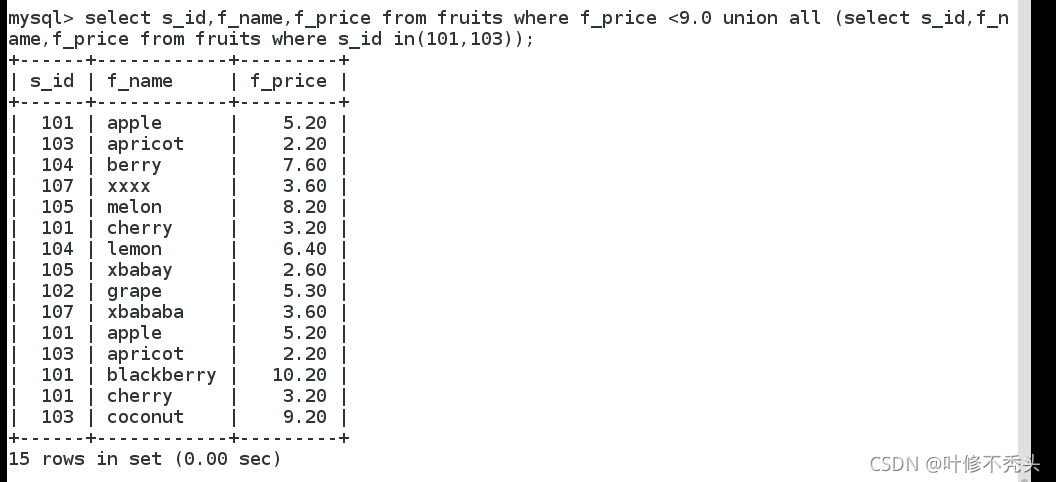
union和union all的区别:使用union all的功能是不删除重复行,加上all关键字语句执行时所需要的资源少,所 以尽可能地使用它,因此知道有重复行但是想保留这些行,确定查询结果中不会有重复数据或者不需要去掉重 复数据的时候,应当使用union all以提高查询效率。
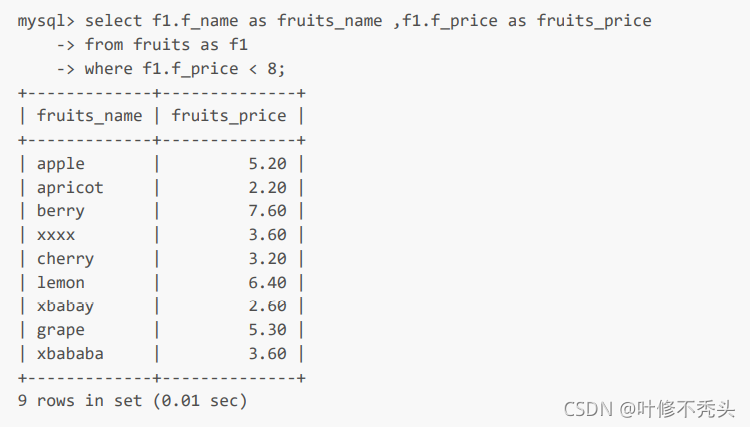
为表和字段取别名
前面介绍了分组查询、聚合函数查询和嵌套子查询,取别名使用关键字as为查询结果中的某一列指定一个特别 的名字。可以为字段或者表分别取别名,在查询时,使用别名替代指定的内容。
为字段取别名


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









