







1.什么是缓存
缓存就是数据交换的缓冲区(Cache),一般读写性能较高
作用:
- 降低后端负载
- 提高读写效率,降低响应时间
成本: - 数据一致性成本
2.添加redis缓存
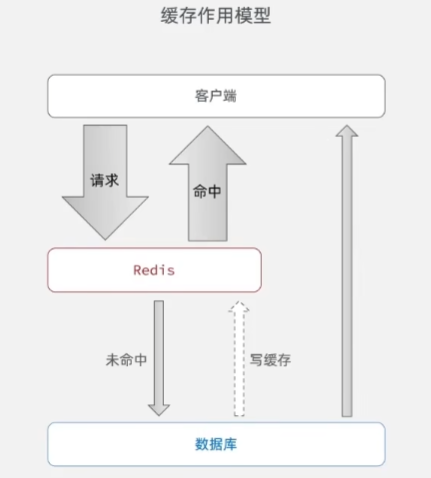
缓存作用模型:
添加redis缓存流程:
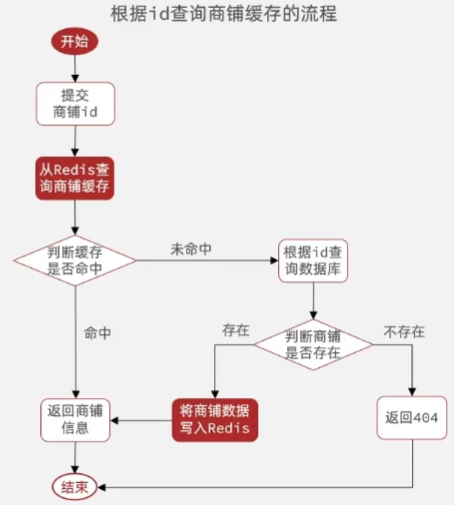
2.1 给商铺信息添加缓存
//1.从redis查询商铺缓存
String key = RedisConstants.CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
//2.判断缓存是否命中
if (StrUtil.isNotBlank(shopJson)) {
//3.存在,直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
return Result.ok(shop);
}
//4.不存在,根据id查询数据库
Shop shop = getById(id);
//5.判断商铺是否存在
if (shop == null) {
//6.不存在,返回不存在
return Result.fail("店铺不存在");
}
//7.存在,将商铺数据写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);
return Result.ok(shop);
2.2 (作业)给商店类型添加缓存
//1.从redis查询商铺类型缓存
Set<String> shopSetJsonSet = stringRedisTemplate.opsForZSet().range(CACHE_SHOP_TYPE_LIST_KEY, 0, -1);
//2.命中,转换格式返回
if (shopSetJsonSet.size() != 0) {
List<ShopType> shopTypes = new ArrayList<>();
for (String jsonStr : shopSetJsonSet) {
shopTypes.add(JSONUtil.toBean(jsonStr, ShopType.class));
}
return Result.ok(shopTypes);
}
//3.未命中,根据数据库查询
List<ShopType> shopTypeList = query().orderByAsc("sort").list();
//4.判断商铺类型是否存在
if (shopTypeList == null || shopTypeList.isEmpty()) {
return Result.fail("404 商店分类不存在");
}
//5.不存在,返回404
//6.存在,写入redis
for (ShopType shopType : shopTypeList) {
stringRedisTemplate.opsForZSet().add(CACHE_SHOP_TYPE_LIST_KEY, JSONUtil.toJsonStr(shopType), shopType.getSort());
}
return Result.ok(shopTypeList);
3.缓存更新策略
3.1 缓存更新策略
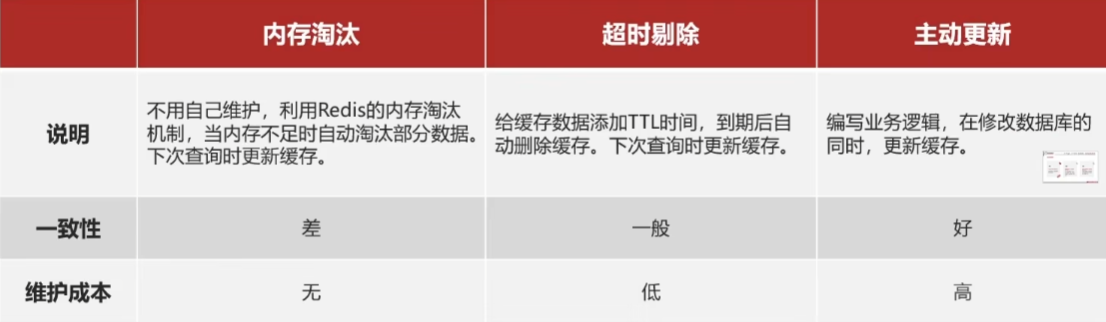
业务场景:
- 低一致性需求:使用内存淘汰机制,例如店铺类型的查询缓存
- 高一致性需求:主动更新,并以超市提出作为兜底方案,例如店铺详情查询的缓存
操作缓存和数据库时有三个问题需要考虑
- 删除缓存还是更新缓存?
- 更新缓存
- 删除缓存
- 如何保证缓存与数据库的操作的同时成功或失败
- 单体系统,将缓存与数据库操作放在同一个事务
- 分布式系统,利用TTC等分布式事务方案
- 先操作缓存还是先操作数据库
3.2 最佳实践方案
- 低一致性需求:使用redis自带的内存淘汰机制
- 高一致性需求:主动更新,并以超时剔除作为兜底方案
- 读操作
- 缓存命中则直接返回
- 缓存未命中则查询数据库
- 写操作:
- 先写数据库,然后删除缓存
- 要确保数据库与缓存操作的原子性
3.3 给查询商铺的缓存添加超时剔除和主动更新的策略
修改ShopController中的业务逻辑:
- 根据id查询店铺时,如果缓存未命中,则查询数据库,将数据库结果写入缓存,并设置超时时间
- 根据id修改店铺时,先修改数据库,再删除缓存
修改ShopController中的updateShop:
@Override
@Transactional
public Result update(Shop shop) {
Long id = shop.getId();
if (id == null) {
return Result.fail("店铺id为空");
}
updateById(shop);
stringRedisTemplate.delete(RedisConstants.CACHE_SHOP_KEY + id);
return Result.ok();
}
调试方式:
使用postman
方法类型为PUT,地址为http://localhost:8081/shop
header中加入Authorization,值就是token
body为json格式:(把不要的都删除了,不然封装会报错)
{
"area": "大关",
"openHours": "10:00-22:00",
"sold": 4215,
"address": "金华路锦昌文华苑29号",
"comments": 3035,
"avgPrice": 80,
"score": 37,
"name": "103茶餐厅",
"typeId": 1,
"id": 1
}
4. 缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会失效,这些请求都会打到数据库。
常见的解决方案有两种:
-
缓存空对象
- 优点:实现简单,维护方便
- 缺点
- 额外的内存消耗
- 可能造成短期的不一致
-
布隆过滤
- 布隆过滤器(Bloom Filter)是一种概率型数据结构,用于判断一个元素是否存在于一个集合中,具有高效的查询速度和低内存消耗。它基于哈希函数和位数组实现
- 布隆过滤器适用于需要快速判断一个元素是否存在于集合中,并且可以容忍一定的误判率的场景,如缓存穿透防护、URL去重、拦截恶意请求等。
- 优点:内存占用较少,没有多余key

4.1 解决方法
解决方法
- 缓存null值
- 布隆过滤
- 增强id的复杂度,避免被猜测id规律
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流
5.缓存雪崩
缓存雪崩是指在统一时段大量的缓存key同时失效或者redis服务宕机,导致大量请求到达数据库,造成巨大压力
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性(如Redis哨兵)
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
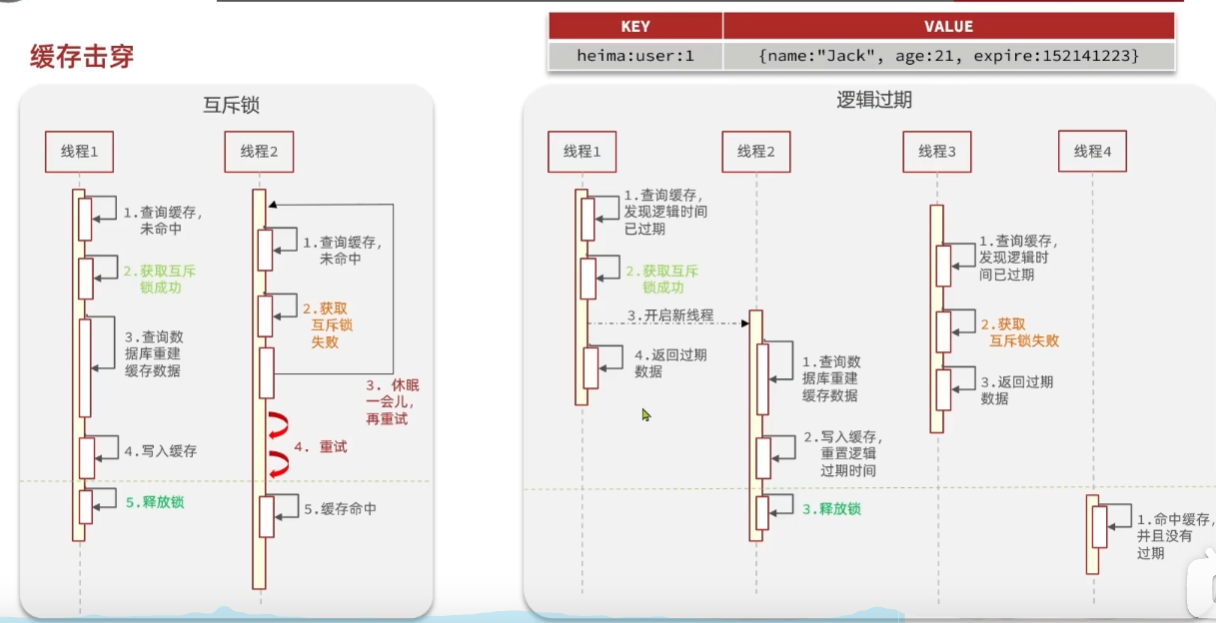
6.缓存击穿
缓存击穿问题也叫热点key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击
常见的解决方案:
- 互斥锁
- 优点
- 没有额外的内存消耗
- 保证一致性
- 实现简单
- 缺点
- 线程需要等待,性能受影响
- 可能有死锁风险
- 优点
- 逻辑过期
- 优点
- 线程无需等待,性能较好
- 缺点
- 不保证一致性
- 有额外内存消耗
- 实现复杂
- 优点
基于互斥锁解决缓存击穿
业务逻辑:
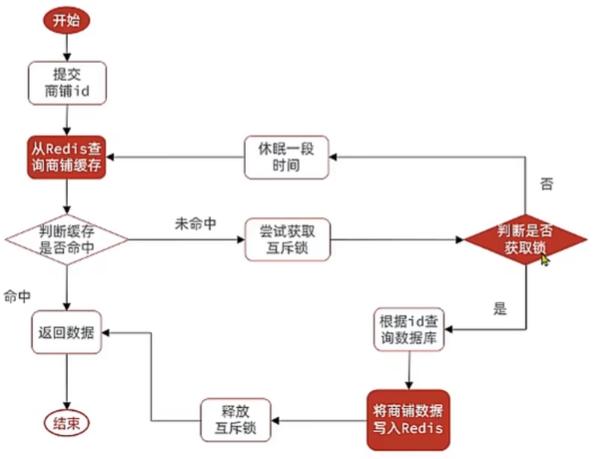
逻辑:
先查询缓存,判断缓存命中没,命中直接返回,再判断命中的是不是空值。
下面就添加缓存重建的逻辑:
- 获取互斥锁
- 判断是否获取成功
- 失败,休眠并重试
- 成功,根据id查询数据库(接原来的逻辑)
- try catch finally里面添加释放锁
//1.从redis查询商铺缓存
String key = RedisConstants.CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
//2.判断缓存是否命中
if (StrUtil.isNotBlank(shopJson)) {
//3.存在,直接返回
return JSONUtil.toBean(shopJson, Shop.class);
}
//判断命中的是否是空值
if (shopJson != null) {
return null;
}
//4.实现缓存重建
//4.1 获取互斥锁
String lockKey = "lock:shop:" + id;
Shop shop = null;
try {
boolean isLock = tryLock(lockKey);
//4.2 判断是否获取成功
//4.3失败,休眠并重试
if (!isLock) {
Thread.sleep(50);
return queryWithMutex(id);
}
//4.4成功,根据id查询数据库
shop = getById(id);
//5.判断商铺是否存在
if (shop == null) {
//6.不存在,返回不存在
//将空值写入redis
stringRedisTemplate.opsForValue().set(key, "", RedisConstants.CACHE_NULL_TTL, TimeUnit.MINUTES);
return null; }
//7.存在,将商铺数据写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//释放互斥锁
unLock(lockKey);
}
return shop;
基于逻辑过期解决缓存击穿
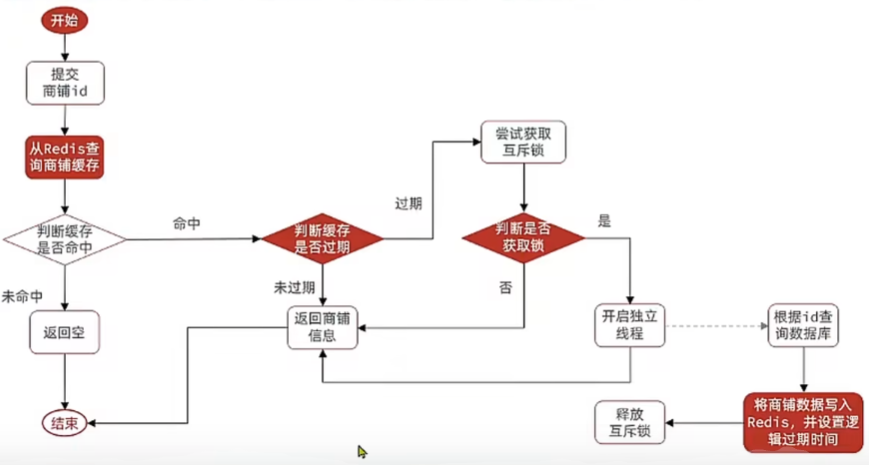
新建一个RedisData类,存储字段过期时间和数据,我在这里用的是泛型
逻辑跟通过互斥锁的差不多,多了要检查缓存是否过期,这个很重要,而且要在获取成功后double check一下。
//1.从redis查询商铺缓存
String key = RedisConstants.CACHE_SHOP_KEY + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
//2.判断缓存是否命中
if (StrUtil.isBlank(shopJson)) {
//3.存在,直接返回
return null;
}
//4.命中,需要把json反序列化为对象
RedisData<Shop> redisData = JSONUtil.toBean(shopJson, RedisData.class);
Shop shop = redisData.getData();
LocalDateTime expireTime = redisData.getExpireTime();
//5.判断是否过期
if (expireTime.isAfter(LocalDateTime.now())) {
//5.2 未过期,直接返回店铺信息
return shop;
}
//5.1 已过期,需要进行缓存重建
//6.缓存重建
//6.1获取互斥锁
String lockKey = RedisConstants.LOCK_SHOP_KEY + id;
boolean islock = tryLock(lockKey);
//6.2 判断是否获取成功
if (islock) {
//double check
if (expireTime.isAfter(LocalDateTime.now())) {
//5.2 未过期,直接返回店铺信息
return shop;
}
//6.3获取成功,开启独立线程,进行缓存重建
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
saveShop2Redis(id, 20L);
} catch (Exception e) {
e.printStackTrace();
} finally {
unLock(lockKey);
}
});
}
//6.4 返回商铺信息
return shop;
封装Redis工具类
熟练使用泛型和lambda表达式来改装queryWithPassThrough等函数
例子:
public <R, ID> R queryWithPassThrough(String keyPrefix, ID id, Class<R> type, Function<ID, R> dbfallback, Long time, TimeUnit unit) {
//1.从redis查询商铺缓存
String key = keyPrefix + id;
String json = stringRedisTemplate.opsForValue().get(key);
//2.判断缓存是否命中
if (StrUtil.isNotBlank(json)) {
//3.存在,直接返回
R r = JSONUtil.toBean(json, type);
return r;
}
//判断命中的是否是空值
if (json != null) {
return null;
}
//4.不存在,根据id查询数据库
R r = dbfallback.apply(id);
if (r == null) {
stringRedisTemplate.opsForValue().set(key, "", RedisConstants.CACHE_NULL_TTL, TimeUnit.MINUTES);
return null; }
this.set(key, r, time, unit);
return r;
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











