







原文链接:https://arxiv.org/pdf/1804.02767v1.pdf
2018年发表
论文阅读,加上自己的理解。
1 YOLOv3是什么
对YOLO做了一些改进,还训练了一个新的分类器网络。
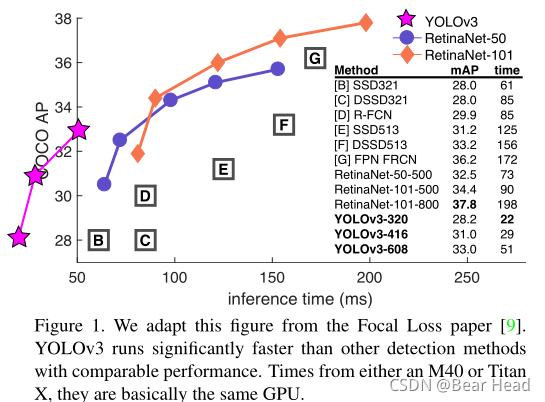
YOLOv3的运行速度明显快于其他检测方法,且性能相当。
1.1 边框预测
和YOLO9000一样,使用维度集群作为锚框来预测边框(就是用Kmeans得到锚框)。每个边框预测4个坐标
t
x
,
t
y
,
t
w
,
t
h
t_x,t_y,t_w,t_h
tx,ty,tw,th。如果单元格从图像的左上角偏移
(
c
x
,
c
y
)
(c_x,c_y)
(cx,cy)并且锚框的宽度和高度为
p
w
,
p
h
p_w,p_h
pw,ph,则预测结果对应于:
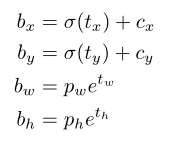
也就是每个网格对应的锚框的中心一开始在左上角,为了让锚框变成我们想要的预测框,所以得将锚框进行移动、拉伸。这样中心为
(
c
x
,
c
y
)
(c_x,c_y)
(cx,cy)、宽高为
p
w
,
p
h
p_w,p_h
pw,ph的锚框变成了中心为
(
b
x
,
b
y
)
(b_x,b_y)
(bx,by)、宽高为
b
w
,
b
h
b_w,b_h
bw,bh的预测框。而
t
x
,
t
y
,
t
w
,
t
h
t_x,t_y,t_w,t_h
tx,ty,tw,th正是我们要学习的。
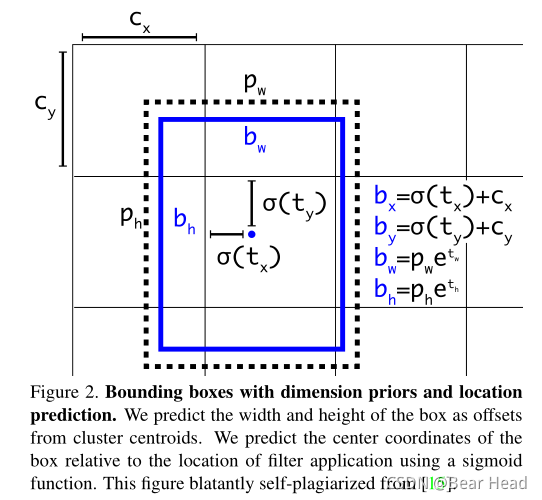
上图:具有维度先验和位置预测的边界框。预测出框的宽度和高度作为簇心的偏移量。使用sigmoid函数预测出相对于滤波器应用位置的框中心坐标。
用真实框得到监督信息。真实框是我们训练之前标注的,所以其中心、宽、高都是通过计算已知的,所以从锚框到真实框,利用上面的四个式子,就可以得出
t
x
,
t
y
,
t
w
,
t
h
t_x,t_y,t_w,t_h
tx,ty,tw,th。利用损失函数,使从锚框到预测框的这四个值不断接近从锚框到真实框的这四个值。
在训练中使用平方和误差损失。如果某个坐标预测的gt值是
t
^
∗
\hat{t}_*
t^∗,那么梯度就是gt值(从gt框计算出来的)减去预测:
t
^
∗
−
t
∗
\hat{t}_*-t_*
t^∗−t∗。
YOLOv3使用逻辑回归预测每个边界框的目标得分。如果先验框与真实目标的重叠比其他任何先验框都多,那这个客观得分应该是1,如果边界框先验不是最好的,但确实与真实目标重叠超过某个阈值,那就忽略预测。阈值我们使用0.5。此系统只为每个真实目标分配一个边界框。如果边界框没有分配给真实目标,那这个框就没有坐标损失和类预测损失了,只有有无目标损失,并且我们也就知道了,它的目标得分应该向着接近于0的方向训练。
1.2 类预测
每个框使用多标签分类来预测边界框可能包含的类,使用逻辑分类器。在训练过程中,使用二元交叉熵损失进行类预测。
这里为什么不使用softmax来分类呢?某些数据集中有重叠的标签,如人和女人,使用softmax会强加一个假设,即每个框只有一个类,但通常情况并非如此。多标签方法可以更好地模拟数据。
1.3 跨尺度预测
YOLOv3以3种不同的尺度来预测边界框。我们的系统使用和特征金字塔相似的概念,从3个尺度来提取特征。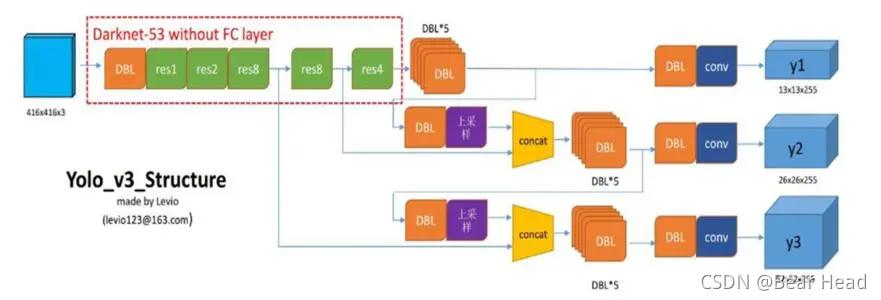
这里,我从网上找到了一张关于YOLOv3的结构图。通过这个图来看跨尺度特征融合,便可以一目了然。
在基本特征提取器后,添加几个卷积层,最后预测出三维向量。这三维向量是什么信息呢?下一段再说。在特征提取过程中,发生了5次下采样,我们刚刚得出的三维向量是32倍下采样再依次经过DBL、几个卷积层、DBL、卷积层的结果。将经过DBL后面那几个卷积层的过程中的特征向量取出来,进行DBL和2倍上采样后和经过16倍下采样的特征图按通道拼接,然后再进行后面的操作。和8倍下采样的特征图拼接同理。该方法使我们能够从上采样的特征中获得更有意义的语义信息,并从早期的特征图中获得更细粒度的信息。
所以最后的输出有三个分支,在COCO数据集上,分别输出[N,255,13,13]、[N,255,26,26]、[N,255,52,52]。N是batch_size,255即是通道维度上的长度。每个分支分配三种锚框,也就是每个网格对应3个锚框,每个预测框有坐标t_x,t_y,t_w,t_h,目标置信度和分类。所以锚框数3*(5+类别数80)=255。13、26、52则是最终输出的宽度和高度,同时13 * 13、26 * 26、52 * 52也是图像在逻辑上被划分的网格数。
1.4 特征提取器
用一种新的网络进行特征提取。使用了连续的3×3和1×1卷积层,但是现在也有一些shortcut连接并且明显更大。有53层。网络结构如下: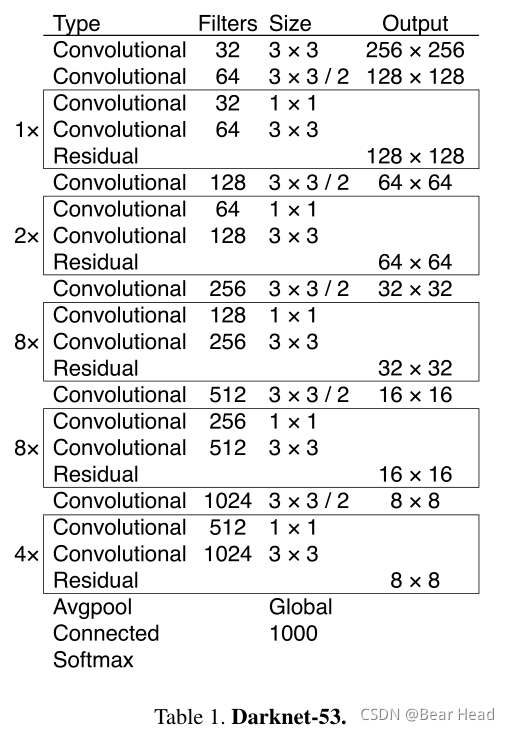
这个网络比Darknet19强大得多,比ResNet-101、ResNet-152更高效。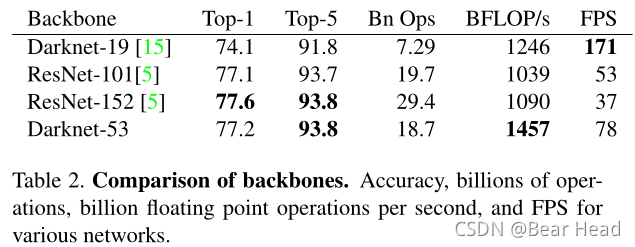
1.5 训练
用多尺度训练,大量的数据增强,批处理归一化。
2 对YOLOv3的分析
通过新的多尺度预测,可以看到YOLOv3对小目标有较好的表现。但是,它在中型和大型对象上的性能相对较差。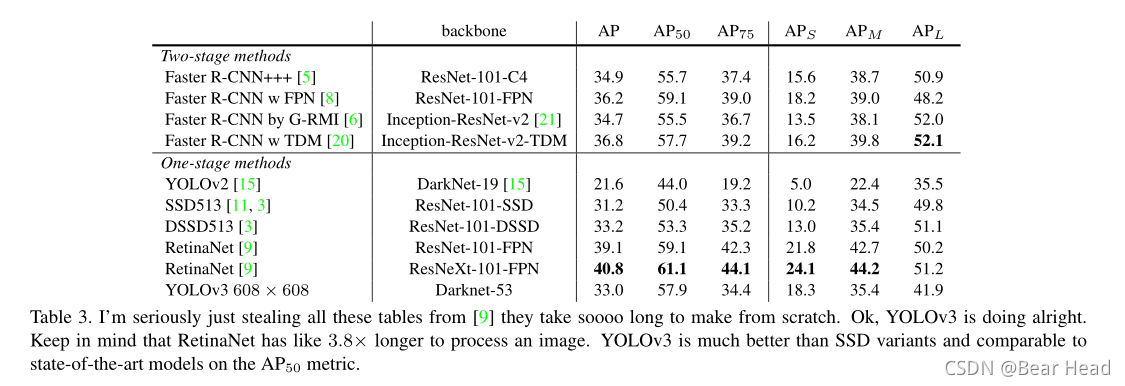

















 549
549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









