







测试周期:每周进行16次语言测试(Verbal)与7次视觉测试(Vision),数据更新至2025年2月3日。
评分标准:最终成绩取最近7次测试的平均值,确保结果反映模型的稳定性。
分数范围:横轴标有50至160的IQ分数区间,目前主流模型成绩集中在80至150之间。
图表将模型分为三组排列,可能对应不同测试类别或版本迭代。通过对比发现:
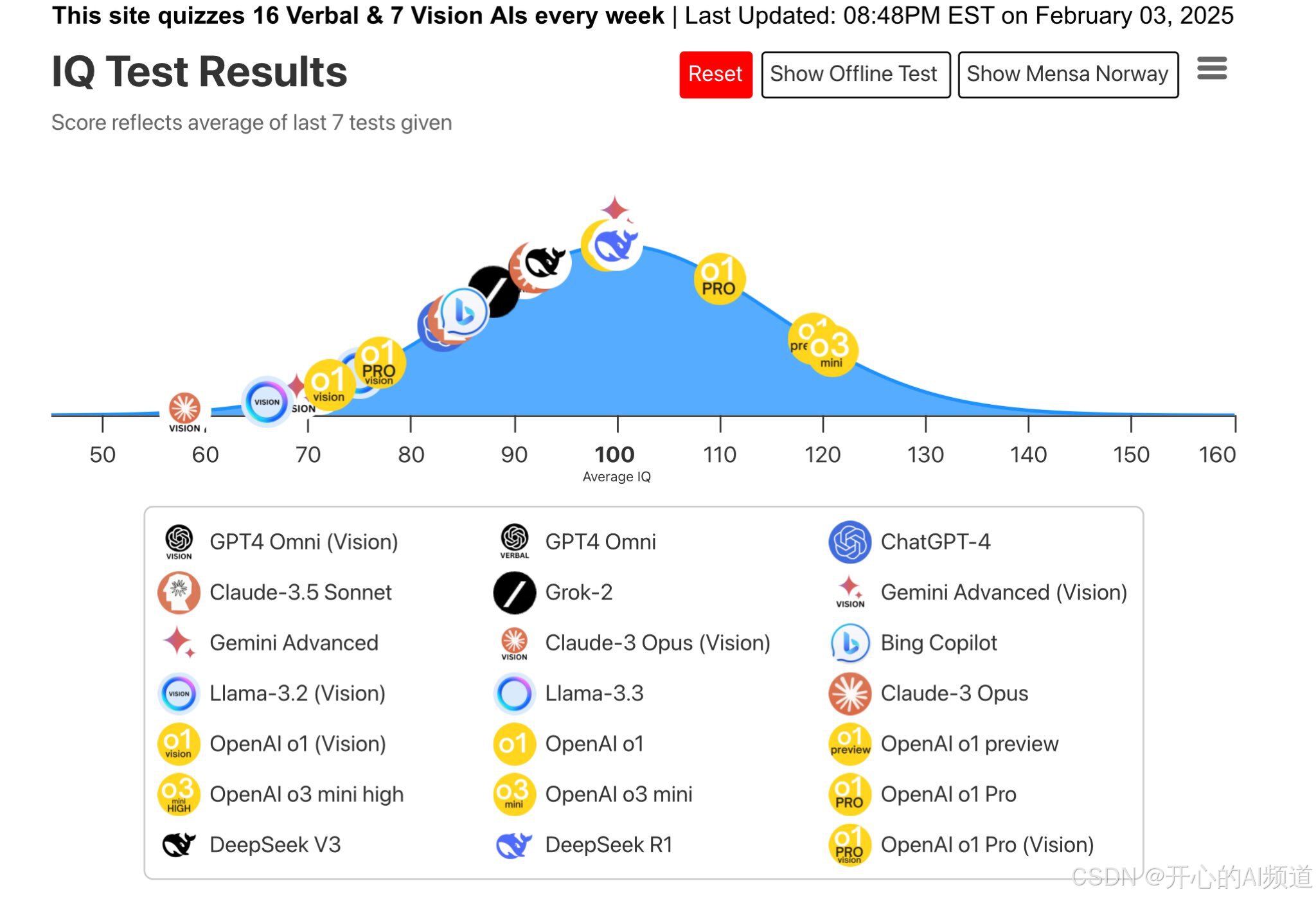
1.第一梯队:多模态模型优势显著
- 头部模型:GPT-4 Omni(Vision)、Claude-3.5 Sonnet、Gemini Advanced等位居前列,均具备视觉处理能力(标注“Vision”)。
- 关键能力:视觉与语言结合的“多模态”技术显著提升综合得分,例如GPT-4 Omni(Vision)可能通过图像理解增强逻辑推理表现。
2. 第二梯队:语言模型追赶中
- 纯语言模型:如Grok-2、Llama-3.3等未标注“Vision”的模型,分数略低于第一梯队,但仍保持80-120区间。
-迭代差异:Claude-3 Opus(Vision)等升级版通过加入视觉模块缩小差距,凸显技术更新的重要性。
3. 第三梯队:早期版本与细分产品
- 细分
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











