








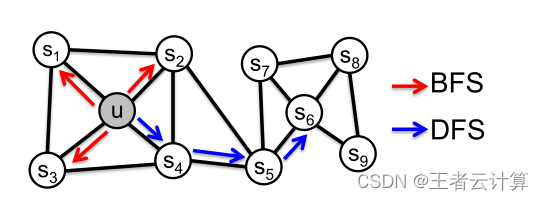
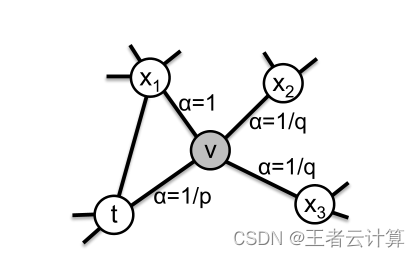
源码

import networkx as nx
from gensim.models import Word2Vec
import argparse
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import Node2Vec
# 读入命令行参数
def parse_args():
parser = argparse.ArgumentParser(description="Run node2vec.")
parser.add_argument('--input', nargs='?', default='aaa.txt',
help='Input graph path')
parser.add_argument('--output', nargs='?', default='karate.emb',
help='Embeddings path')
parser.add_argument('--dimensions', type=int, default=128,
help='Number of dimensions. Default is 128.')
parser.add_argument('--walk-length', type=int, default=80,
help='Length of walk per source. Default is 80.')
parser.add_argument('--num-walks', type=int, default=10,
help='Number of walks per source. Default is 10.')
parser.add_argument('--window-size', type=int, default=10,
help='Context size for optimization. Default is 10.')
parser.add_argument('--iter', default=1, type=int,
help='Number of epochs in SGD')
parser.add_argument('--workers', type=int, default=8,
help='Number of parallel workers. Default is 8.')
parser.add_argument('--p', type=float, default=1,
help='Return hyperparameter. Default is 1.')
parser.add_argument('--q', type=float, default=1,
help='Inout hyperparameter. Default is 1.')
parser.add_argument('--weighted', dest='weighted', action='store_true',
help='Boolean specifying (un)weighted. Default is unweighted.')
parser.add_argument('--unweighted', dest='unweighted', action='store_false')
parser.set_defaults(weighted=False)
parser.add_argument('--directed', dest='directed', action='store_true',
help='Graph beicansis (un)directed. Default is undirected.')
parser.add_argument('--undirected', dest='undirected', action='store_false')
parser.set_defaults(directed=False)
return parser.parse_args()
def read_graph():
if args.weighted:
G = nx.read_edgelist(args.input, nodetype=int, data=(('weight', float),), create_using=nx.DiGraph())
else:
G = nx.read_edgelist(args.input, nodetype=int, create_using=nx.DiGraph())
for edge in G.edges():
G[edge[0]][edge[1]]['weight'] = 1
if not args.directed:
G = G.to_undirected()
return G
if __name__ == "__main__":
args = parse_args()
nx_G = read_graph()
print("可视化原图")
pos = nx.spring_layout(nx_G, seed=5)
nx.draw(nx_G, pos, node_size=55, with_labels=False)
plt.show()
G = Node2Vec.Graph(nx_G, args.directed, args.p, args.q)
G.preprocess_transition_probs()
walks = G.simulate_walks(args.num_walks, args.walk_length)
walk_str = []
for walk in walks:
tmp = []
for node in walk:
tmp.append(str(node))
walk_str.append(tmp)
model = Word2Vec(walk_str, vector_size=args.dimensions, window=args.window_size, min_count=0, workers=args.workers)
model.wv.save_word2vec_format(args.output)
X = model.wv.vectors
cluster_labels = KMeans(n_clusters=3, random_state=9).fit(X).labels_
colors = []
nodes = list(nx_G.nodes)
for node in nodes: # 按 networkx 的顺序遍历每个节点
idx = model.wv.key_to_index[str(node)] # 获取这个节点在 embedding 中的索引号
print(idx)
colors.append(cluster_labels[idx]) # 获取这个节点的聚类结果
print("节点分类后的图")
pos = nx.spring_layout(nx_G, seed=5)
nx.draw(nx_G, pos, node_color=colors, node_size=55, with_labels=False)
plt.show()
import random
import numpy as np
class Graph():
def __init__(self, nx_G, is_directed, p, q):
self.G = nx_G
self.is_directed = is_directed
self.p = p
self.q = q
def get_alias_edge(self, src, dst):
'''
src:随机游走序列上一个节点
dst:当前节点
'''
G = self.G
p = self.p
q = self.q
unnormalized_probs = []
for dst_nbr in sorted(G.neighbors(dst)):
if dst_nbr == src:
unnormalized_probs.append(G[dst][dst_nbr]['weight'] / p)
elif G.has_edge(dst_nbr, src):
unnormalized_probs.append(G[dst][dst_nbr]['weight'])
else:
unnormalized_probs.append(G[dst][dst_nbr]['weight'] / q)
norm_const = sum(unnormalized_probs)
normalized_probs = [float(u_prob)/norm_const for u_prob in unnormalized_probs]
return alias_setup(normalized_probs)
def preprocess_transition_probs(self):
G = self.G
is_directed = self.is_directed
alias_nodes = {}
for node in G.nodes():
unnormalized_probs = [G[node][nbr]['weight'] for nbr in sorted(G.neighbors(node))]
norm_const = sum(unnormalized_probs)
normalized_probs = [float(u_prob) / norm_const for u_prob in unnormalized_probs]
alias_nodes[node] = alias_setup(normalized_probs)
alias_edges = {}
triads = {}
if is_directed:
for edge in G.edges():
alias_edges[edge] = self.get_alias_edge(edge[0], edge[1])
else:
for edge in G.edges():
alias_edges[edge] = self.get_alias_edge(edge[0], edge[1]) # 随机游走序列种的上一个结点 当前节点
alias_edges[(edge[1], edge[0])] = self.get_alias_edge(edge[1], edge[0])
self.alias_nodes = alias_nodes
self.alias_edges = alias_edges
print(self.alias_nodes)
print(self.alias_edges)
return
def node2vec_walk(self, walk_length, start_node):
G = self.G
alias_nodes = self.alias_nodes
alias_edges = self.alias_edges
walk = [start_node]
while len(walk) < walk_length:
cur = walk[-1]
cur_nbrs = sorted(G.neighbors(cur))
if len(cur_nbrs) > 0:
if len(walk) == 1:
walk.append(cur_nbrs[alias_draw(alias_nodes[cur][0], alias_nodes[cur][1])])
else:
prev = walk[-2]
next = cur_nbrs[alias_draw(alias_edges[(prev, cur)][0],
alias_edges[(prev, cur)][1])]
walk.append(next)
else:
break
return walk
def simulate_walks(self, num_walks, walk_length):
G = self.G
walks = []
nodes = list(G.nodes())
print('Walk iteration:')
for walk_iter in range(num_walks):
print(str(walk_iter + 1), '/', str(num_walks))
random.shuffle(nodes)
for node in nodes:
walks.append(self.node2vec_walk(walk_length=walk_length, start_node=node))
return walks
def alias_setup(probs):
k = len(probs)
q = np.zeros(k)
j = np.zeros(k)
smaller = []
larger = []
# kk事件概率 prob事件个数
for kk, prob in enumerate(probs):
q[kk] = k * prob
if q[kk] < 1.0:
smaller.append(kk)
else:
larger.append(kk)
while len(smaller) > 0 and len(larger) > 0:
small = smaller.pop()
large = smaller.pop()
j[small] = large
q[large] = q[large] - (1 - q[small])
if q[large] < 1.0:
smaller.append(large)
else:
larger.append(large)
return j, q
def alias_draw(j, q):
k = len(j)
kk = int(np.floor(np.random.rand() * k))
if np.random.rand() < q[kk]:
return kk
else:
return j[kk]
论文地址:https://dl.acm.org/doi/abs/10.1145/2939672.2939754


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









