







 本文深入探讨了垃圾回收(GC)的重要性,介绍了GC的基本原理,包括引用计数和可达性分析两种判定垃圾的方法及其优缺点。讨论了垃圾回收的目标——回收堆中的不再使用的对象,以及三种主要的内存回收策略:标记-清除、复制算法和标记-整理。最后,提到了Java中的分代回收策略和垃圾回收器的角色。理解这些概念对于优化程序性能至关重要。
本文深入探讨了垃圾回收(GC)的重要性,介绍了GC的基本原理,包括引用计数和可达性分析两种判定垃圾的方法及其优缺点。讨论了垃圾回收的目标——回收堆中的不再使用的对象,以及三种主要的内存回收策略:标记-清除、复制算法和标记-整理。最后,提到了Java中的分代回收策略和垃圾回收器的角色。理解这些概念对于优化程序性能至关重要。
文章目录
为什么要有垃圾回收及什么是垃圾回收机制(GC)
由于在早期的计算机语言,例如 C / C++,需要开发者手动的来跟踪内存,这种机制虽然内存分配和释放的效率很高,但是如果程序员不小心忘记释放内存,则会造成内存的泄露——申请内存之后,忘记释放了,导致可用的内容越来越少,最终无内存可用
新的编程语言,比如 JAVA,Go,Python,PHP… 现在市面上的大部分主流编程语言,都采取了一个方案,那就是 “垃圾回收机制”,它大概就是:由运行时环境(JVM,Python 解释器,Go运行时)来通过更复杂的策略判定内存是否可以回收,并进行回收的动作,它本质上是靠运行时环境,额外做了很多的工作,来完成自动释放内存的操作的,让程序猿的心智负担大大降低了。
垃圾回收机制的优缺点
优点:
- 不需要考虑内存管理
- 可以有效的防止内存泄漏,有效的利用可使用的内存
缺点:
- 消耗额外的开销(消耗资源更多了)
- 可能会影响程序的流畅运行(垃圾回收经常会引入STW问题)
垃圾回收要回收啥?
那肯定是回收内存鸭❗但是内存又包括:程序计数器 ,栈 (虚拟机栈,本地方法栈),堆 和方法区,那么到底哪一部分需要回收,哪一部分不需要呢❓🤔

由上图我们可知堆才是我们真正需要进行垃圾回收的,但是堆又分为下面这几种情况,这就好像,在任何组织里,人都分成了三个派别:积极派,消极派和中间摇摆派。而正在使用的内存中的对象就代表积极派,不再使用,但是尚未回收的内存中的对象代表消极派,中间部分为中间摇摆派,那么对于上述三个派别,哪些是要进行回收释放内存的呢❓🤔
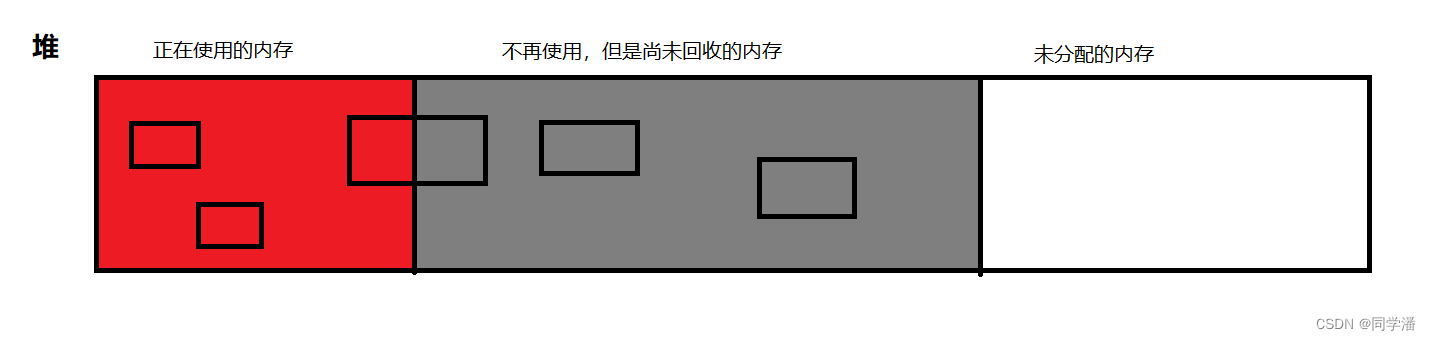
正在使用的积极派肯定是不能释放的,而不再使用的消极派是肯定要释放的,那中间摇摆派它一部分正在使用,而一部分又不再使用,要不要释放呢❓整体来说是不释放的❗❗等到这个对象彻底完全不使用,才真正释放❗❗❗
所以GC中就不会出现“半个对象”的情况,主要还是为了让垃圾回收实现起来更方便,更简单
以上总结起来就一句话:垃圾回收的基本单位是“对象”,而不是“字节”。
垃圾回收具体是如何回收的
可分为两个大的阶段:
- 找垃圾/判定垃圾
- 释放垃圾
找垃圾/判定垃圾
如何找垃圾/判定垃圾呢?当下主流的思路,有两种方案:
- 基于引用计数(不是Java中采取的方案,这是别的语言,像Python采取的方案)
- 基于可达性分析(这个是Java采取的方案)
基于引用计数
针对每个对象,都会额外引入一小块内存,保存这个对象有多少个引用指向它
例如:
Test t = new Test();, 由于t 是指向这个对象的引用,因此Test对象有一个引用,引用计数为1

如果再写个:Test t2 = t,那么就说明 t 和 t2 都是指向这个对象的引用,此时我们的引用计数就变成了2

那么接下来我们思考一下,这个内存什么时候释放呢❓
当这个内存不再使用的时候就释放了,而当引用计数为0的时候,就不再使用了
比如下面的这种情况:
void func(){
Test t=new Test();
Test t2=t;
}
func();
调用方法过程中,创建了对象(分配了内存),在方法执行过程中,引用计数是2,当方法执行结束,由于t和t2是局部变量,跟着栈帧一起释放了,这一释放就导致引用计数为0了(没有引用指向这个对象了,也就没有代码能够访问到这个对象了),此时就认为这个对象就是个垃圾❗❗❗也就相当于说是通过引用来决定对象的生死❗
引用计数的优缺点
引用计数虽然简单、可靠、高效,但是有两个致命的缺陷❗❗
- 空间利用率比较低!!每个 new 的对象都得搭配个计数器(计数器假设 4个字节),如果对象本身很大(几百个字节),多出来4个字节,就不算什么,但是如果本身对象很小(自己才4个字节),多出4个字节,相当于空间被浪费了一半
- 会有循环引用的问题
请看下列代码:
class Test {
// 成员变量
Test t = null;
}
// 创建实例
Test t1 = new Test();
Test t2 = new Test();
内存布局效果如下:
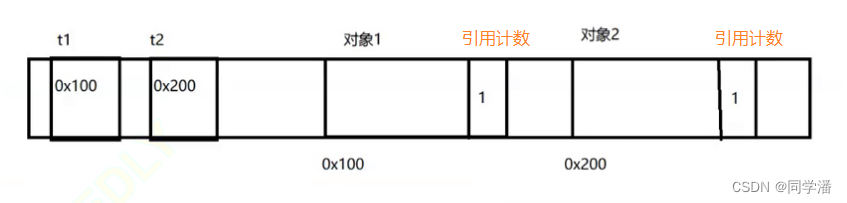
此时再执行t1.t = t2; ,这是把 t2 赋值给了 t1里面的 t 属性,此时对象2有两个引用,所以引用计数就变成了2
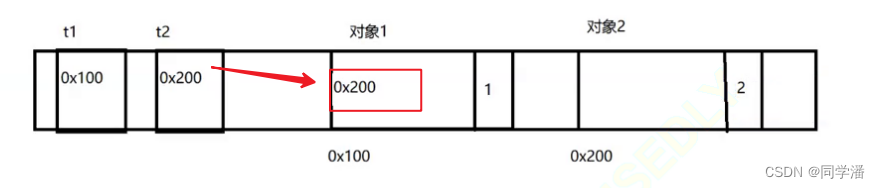
然后再来个类似的,t2.t = t1; 把 t1 赋值给 t2 里面的 t 属性,此时对象1 有两个引用,引用计数就变成了2
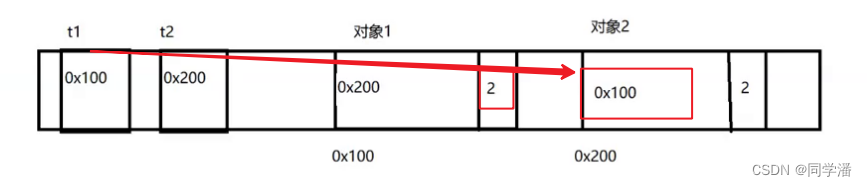
接下来,烧脑的时刻到了:
t1 = null
t2 = null
当执行完上面两行代码后,由于t1,t2两个引用都为null了,所以 各自对象的引用计数都减1,变成了1
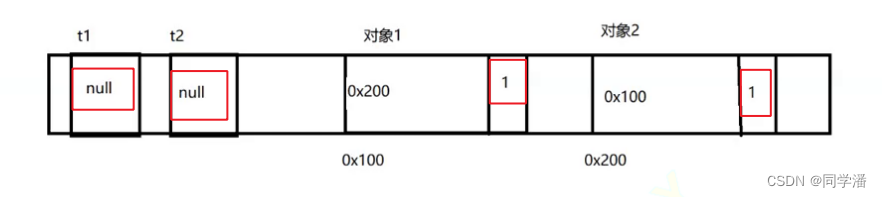
此时此刻,两个对象的引用计数,不为0,所以无法释放,但是由于引用长在彼此的身上,外界的代码也无法访问到这两个对象;此时此刻,这俩对象就被孤立了,既不能使用,又不能释放,就出现了“内存泄露”的问题。
所以,像 Python,PHP里进行GC也不只靠引用计数,还依赖其他的机制配合。而Java就不使用引用计数了,直接采用可达性分析❗
基于可达性分析
就是通过额外的线程,定期的针对整个内存空间的对象进行扫描,有一些起始位置(称为 GCRoots),会类似于 深度优先遍历一样,把可以访问到的对象都标记一遍(带有标记的对象就是可达对象),没有被标记的对象,就是不可达,也就是垃圾!
GCRoots:
- 栈上的局部变量
- 常量池中的引用指向的对象
- 方法区中的静态成员指向的对象
以上这几个全都算 GCRoots
比如:构造一棵我们常见的二叉树
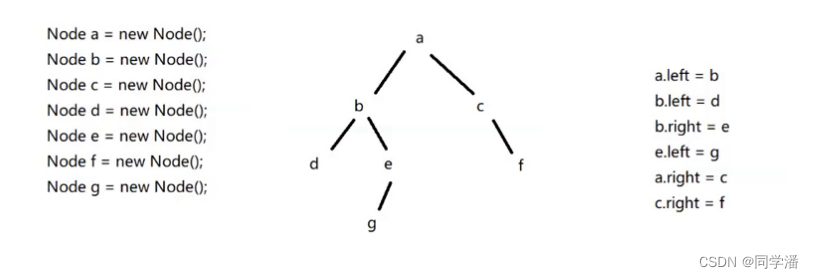
如果我们在外面的代码中来个:Node root = a;
代码中只要拿到树根节点,就可以掌握所有的节点,树上的任意节点,都可以通过 a 直接/间接的获取到
也就是说,GC在进行可达性分析的时候,当 GC 扫描到 a 的时候,就会把 a 能访问到的所有元素都去访问一遍,并且进行标记。
但是如果代码中,执行如下代码:
c.right = null
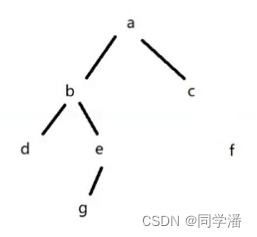
则此时意味着,从 a 出发,就访问不到 f了,f 就是 不可达,f 就是垃圾,f 就应该被回收掉❗❗
如果代码中是:
a.right = null
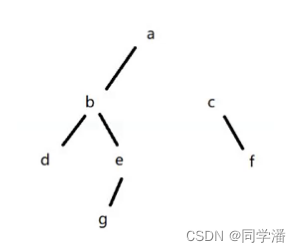
此时从 a 出发,c 和 f 都是不可达了,也就都被标记成垃圾了❗
可达性分析说直白点就是去遍历每一个对象,但是如果内存中的对象特别多,这个遍历就会很慢,因此 GC 还是比较消耗时间和系统资源的❗❗❗
可达性分析的优缺点
优点就是克服了引用计数的两个缺点:
- 空间利用率低
- 循环引用
缺点:
- 系统开销大,遍历一次可能比较慢
总结:找垃圾,核心就是确认这个对象未来是否还会使用,什么算不使用了?没有引用,就不使用了
回收垃圾(释放内存)
回收垃圾(释放内存)三种基本策略如下⬇️⬇️⬇️
标记 - 清除
如下图所示:这是一块内存,被切分为了多个小块,其中打勾的部分都是垃圾

这里的标记:就是可达性分析的过程,清除:就是直接释放内存 ,灰色区域代表释放内存

此时如果直接释放,虽然内存是还给系统了,但是被释放的内存是离散的(不是连续的),而分散开带来的问题就是:“内存碎片”。
内存碎片就是:比如空闲的内存有很多,假设一共是 1G,如果要申请 500M 内存,也是可能申请失败的,因为要申请 500M 的内存 必须是连续的,每次申请,都是申请的连续的内存空间,而这里的 1G 可能是多个 碎片加在一起 才 1G,可用的并不多
为了解决内存碎片因此我们引入了复制算法!
复制算法
如下图:把一块内存,分成两半,左边一半有很多对象,打钩的标记为垃圾,右边的是:把左边没有打勾的可用的对象拷贝过来的
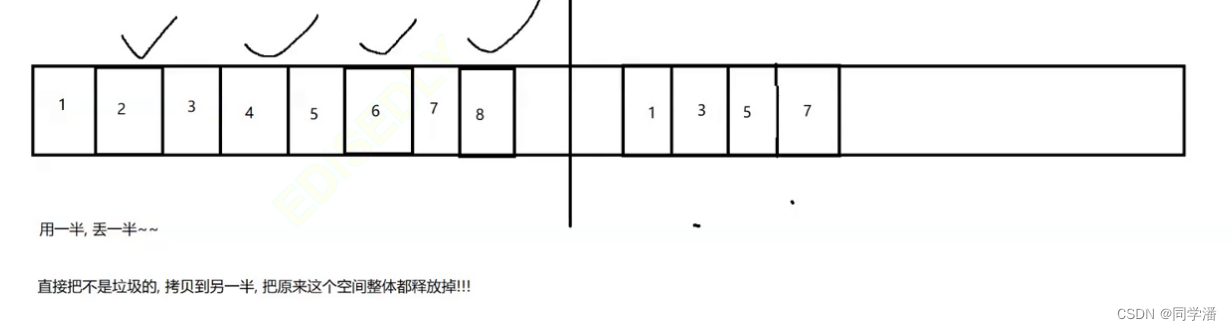
然后直接把原来这个空间整体全部都释放掉

此时内存碎片问题就迎刃而解了!
但是复制算法也有问题:
- 内存空间利用率低(只能用一般的空间)
- 如果要保留的的对象多,要释放的对象少,此时复制开销就很大
因此针对复制算法我们再进行改进—>标记 - 整理
标记 - 整理
如下图:和上面一样,内存中打勾的标记为垃圾

标记-整理的操作就类似于顺序表删除中间元素,有一个搬运操作,我们将 3 搬运到 2 ,再将 5 搬运到 3 ,再把 7 搬运到 4 ,然后把后面的部分整体的释放掉

这个方案空间利用率是高了,但是仍然没有解决复制/搬运元素开销大的问题
分代回收
上述的三个方案,虽然能解决问题,但是都有缺陷,实际 JVM 中的实现,会把多种方案结合起来一起使用,这个思路我们称为 “分代回收”
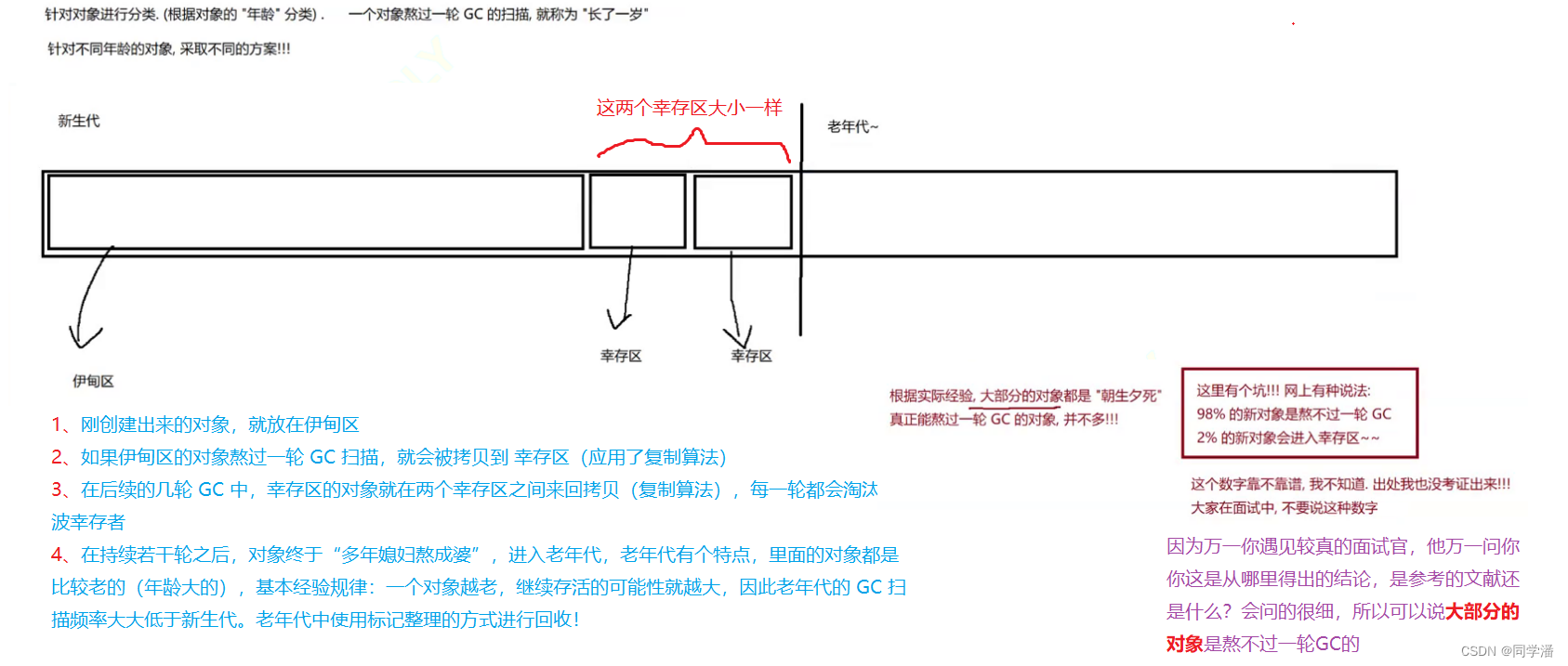
注意:上述过程是面试中的经典问题❗❗❗一定要重点掌握❗❗❗
分代回收中,还有一个特殊情况:有一类对象可以直接进入老年代(大对象,占有内存多的对象),大对象拷贝开销比较大,不适合使用复制算法!
垃圾回收器
上面说的找垃圾,和释放垃圾,说的都是算法思想,不是具体落地实现,在JVM里,真正实现上述算法的模块称为“垃圾回收器”。


由于这些垃圾回收器都还是在不断发展不断进化,所以我们要重点掌握的是垃圾回收算法(引用计数+可达性分析+标记清除+标记整理+复制算法+分代回收),这些垃圾收集器,简单了解即可❗


















 1183
1183

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









