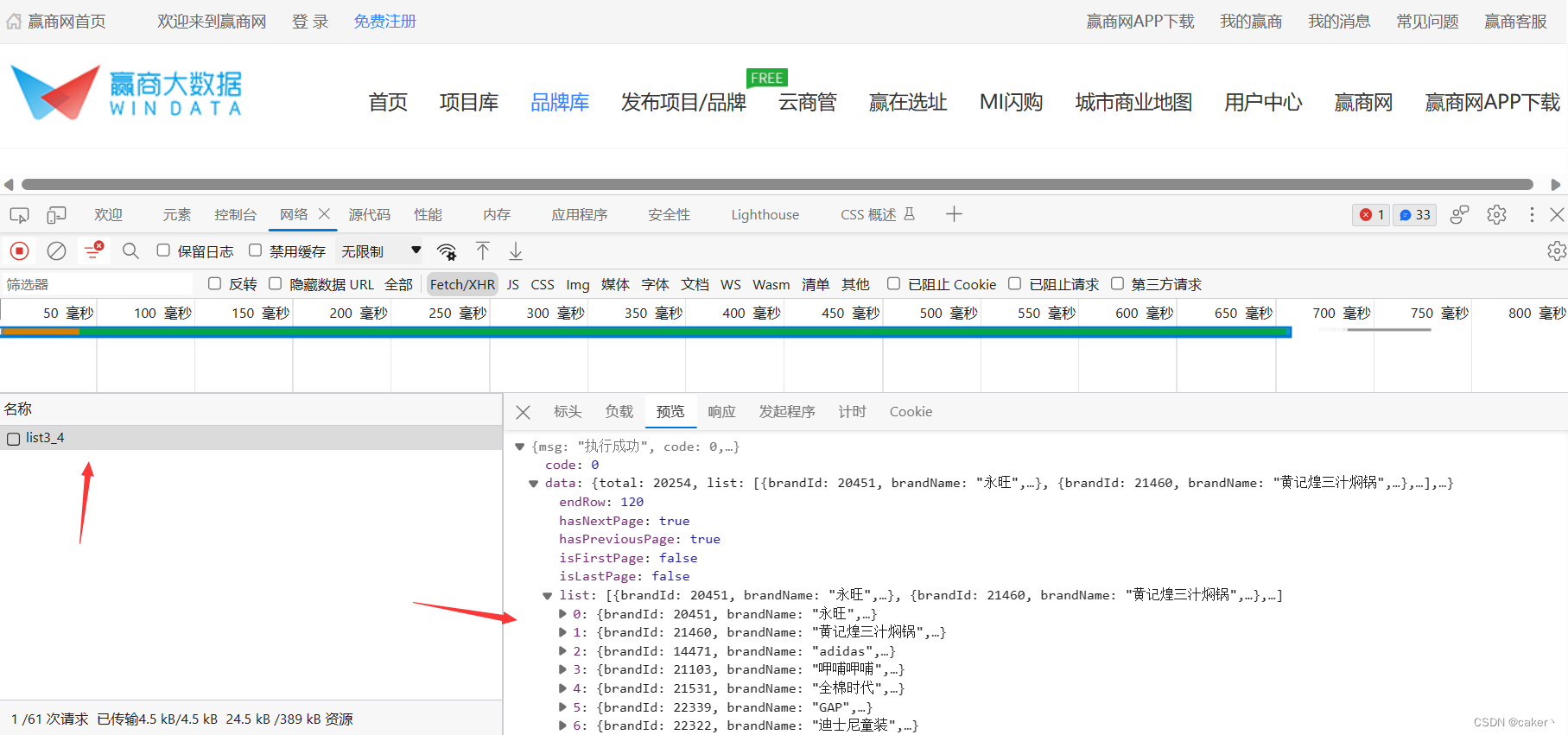
某品牌数据采集 采集需求 地址:http://www.winshangdata.com/brandList 需求:用scrapy框架采集本站数据,至少抓取5个分类,数据量要求5000以上 采集字段:标题、创建时间、开店方式、合作期限、面积要求 网页分析 进入网站后页面如下 打开f12切换到网络这一栏,刷新网页或者点击下一页抓取请求 分析返回的json数据发现,只能获取到我们需要的标题、面积要求









 超级会员免费看
超级会员免费看

 本文详细介绍了如何使用Python的Scrapy框架采集某品牌网站的数据,包括采集需求、网页分析、代码实现和结果展示。目标是抓取至少5个分类、5000条以上的数据,涉及字段包括标题、创建时间、开店方式、合作期限和面积要求。通过分析网络请求,发现部分数据在json中,其余数据需通过详情页的li标签获取。文章指出,爬虫工作流程包括获取brandId,构造详情页URL,并利用XPath提取所需信息。
本文详细介绍了如何使用Python的Scrapy框架采集某品牌网站的数据,包括采集需求、网页分析、代码实现和结果展示。目标是抓取至少5个分类、5000条以上的数据,涉及字段包括标题、创建时间、开店方式、合作期限和面积要求。通过分析网络请求,发现部分数据在json中,其余数据需通过详情页的li标签获取。文章指出,爬虫工作流程包括获取brandId,构造详情页URL,并利用XPath提取所需信息。


 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








