






说明:本文章为自己在复现SSD代码的过程中的经历以及遇到的问题,主要是为自己后续使用时,有所参考!主要参考的是下面博主的文章内容!!!
1. SSD代码的下载
代码下载地址:GitHub - bubbliiiing/ssd-pytorch: 这是一个ssd-pytorch的源码,可以用于训练自己的模型。
推荐:通过git下载代码!!!
2. 数据集的准备
2.1 训练所用数据集
复现所用数据集为VOC2007数据集,SDD代码文件中README.md的数据集下载方式。
给出链接:百度网盘 请输入提取码
提取码:ph32
数据集下载完毕后,直接将数据集放在根目录下即可!如下图所示:
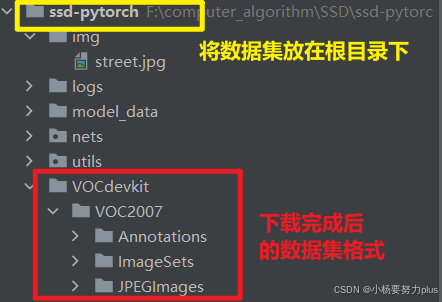
2.2 权重文件的下载
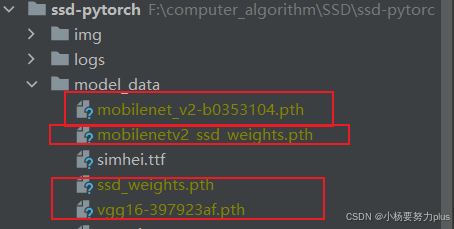
下载完数据集的同时,也将所需要的权重文件一起下载,下载完毕后,将权重文件放在model_data文件夹下。
权重文件的下载链接:
提取码:jgn8
权重文件在项目文件中的位置:
3. 环境配置
3.1 虚拟环境的创建
【重要前提】已经安装好Anaconda3!!!并配置好Pycharm!!!
"win+r"打开Windows运行对话框,然后输入cmd打开命令提示符(Command Prompt),然后输入下列代码:
conda create --name=SSD python=3.9说明:此代码用于创建一个名为SSD的虚拟环境,虚拟环境中所用的python版本为3.9,此处一定要用个版本,包括下面环境安装中所设计到的环境依赖的版本,否则会在后续的运行中出现各种错误。
激活虚拟环境,只需要在Command Prompt中运行下列代码:
#在Command Prompt中输入
conda activate SSD3.2 环境依赖的安装
本文在复现过程中,经过多次尝试,所找到的可以成功将代码运行的环境依赖如下所示:
Package Version
----------------------- -----------
absl-py 1.4.0
cachetools 4.2.4
certifi 2021.5.30
charset-normalizer 2.0.12
cycler 0.11.0
dataclasses 0.8
future 0.18.2
google-auth 2.22.0
google-auth-oauthlib 0.4.6
grpcio 1.48.2
h5py 2.10.0
idna 3.10
importlib-metadata 4.8.3
kiwisolver 1.3.1
Markdown 3.3.7
matplotlib 3.1.2
numpy 1.16.4
oauthlib 3.2.2
opencv-python 4.1.2.30
Pillow 8.2.0
pip 21.2.2
protobuf 3.19.6
pyasn1 0.5.1
pyasn1-modules 0.3.0
pyparsing 3.1.4
python-dateutil 2.9.0.post0
requests 2.27.1
requests-oauthlib 2.0.0
rsa 4.9
scipy 1.2.1
setuptools 58.0.4
six 1.17.0
tensorboard 2.10.1
tensorboard-data-server 0.6.1
tensorboard-plugin-wit 1.8.1
torch 1.2.0
torchvision 0.4.1
tqdm 4.60.0
typing_extensions 4.1.1
urllib3 1.26.20
Werkzeug 2.0.3
wheel 0.37.1
wincertstore 0.2
zipp 3.6.0其中,所用的torch版本为基于GPU的1.2.0版本。此版本的下载,无法直接通过pip从官网进行下载,需要在官网找到之前版本的torch然后提前将其下载下来,然后通过手动安装的方式进行。
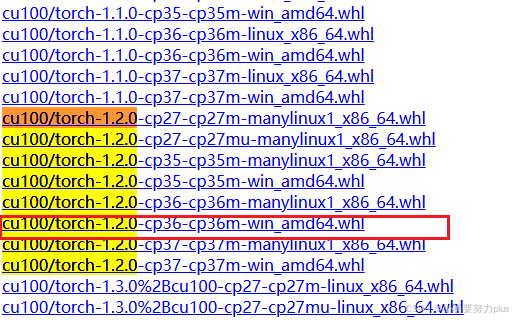
在安装torch-1.2.0之前,需要先安装numpy。注意,由于之前安装的python是3.9且torch版本是1.2.0,所以numpy也需要安装所对应的版本,此处安装的是numpy-1.16.4
#在激活虚拟环境之后,输入下列代码
pip --isolated install numpy==1.16.4完成numpy的安装之后,在下载的torch环境依赖包的根目录下,在路径中输入cmd,打开Command Prompt,然后再激活虚拟环境。然后输入一下代码即可完成torch1.2.0的安装!
pip --isolated install torch-1.2.0-cp36-cp36m-win_amd64.whl numpy --no-index --find-links 路径
注意:代码后面的路径,是需要将其替换为torch1.2.0版本所在的路径地址,例如:
我的torch1.2.0环境安装包放置在G:\ruanjianxiazai\Anaconda\install\envs\SSD路径下,则我的完成的安装代码为:
pip install torch-1.2.0-cp36-cp36m-win_amd64.whl numpy --no-index --find-links G:\ruanjianxiazai\Anaconda\install\envs\SSD
安装剩下的环境依赖:
目前为止,还没有安装的环境依赖有:
torchvision
tensorboard
scipy==1.2.1
matplotlib==3.1.2
opencv_python==4.1.2.30
tqdm==4.60.0
Pillow==8.2.0
h5py==2.10.0
future==0.18.2新建一个requirements.txt文件,将上述环境依赖放置在文件中,然后在requirements.txt所在路径下,输入cmd,打开Command Promp并激活虚拟环境,然后输入下列代码:
pip --isolated install -r requirements.txt此处需要注意:
在运行完requirements.txt文件后,环境中的torch版本会被修改,变成基于cpu的版本,此版本也可以使用,但是使用CPU进行计算速度不如GPU,所以需要卸载现有环境中基于CPU的torch,然后重新再次执行一下torch的安装代码。
#卸载已经安装的torch,首先需要激活SSD虚拟环境
pip uninstall torch
然后执行
pip --isolated install torch-1.2.0-cp36-cp36m-win_amd64.whl numpy --no-index --find-links 路径
但此时环境依赖中的torchvision版本为0.11.3,与torch1.2.0版本不相符,因此需要重新安装
#安装 torchvision 0.4.1
pip --isolated install torchvision==0.4.1至此,SSD所需要的所有的环境依赖配置完毕!!
4. 代码运行
4.1 获得2007_train.txt以及2007_val.txt代码
根目录下的voc_annotation.py,此处有一些参数,在第一次训练时,大部分都不需要进行修改!
但要特别注意以下这个部分:
#--------------------------------------------------------------------------------------------------------------------------------#
# annotation_mode用于指定该文件运行时计算的内容
# annotation_mode为0代表整个标签处理过程,包括获得VOCdevkit/VOC2007/ImageSets里面的txt以及训练用的2007_train.txt、2007_val.txt
# annotation_mode为1代表获得VOCdevkit/VOC2007/ImageSets里面的txt
# annotation_mode为2代表获得训练用的2007_train.txt、2007_val.txt
#--------------------------------------------------------------------------------------------------------------------------------#
annotation_mode = 24.2 开始运行代码
在train.py文件中,只需要点击运行即可完成初步的代码复现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









