







 本文介绍了一种技术,通过提取身份参考图像的特征点,结合音频的MFCC编码和情感特征提取,利用深度学习模型如MLP、LSTM和CBAM,生成具有真实情感和口型同步的面部标志,以实现更逼真的情感说话头生成。
本文介绍了一种技术,通过提取身份参考图像的特征点,结合音频的MFCC编码和情感特征提取,利用深度学习模型如MLP、LSTM和CBAM,生成具有真实情感和口型同步的面部标志,以实现更逼真的情感说话头生成。
解决问题:大多数只关注唇音同步,缺乏再现目标人面部表情的能力。
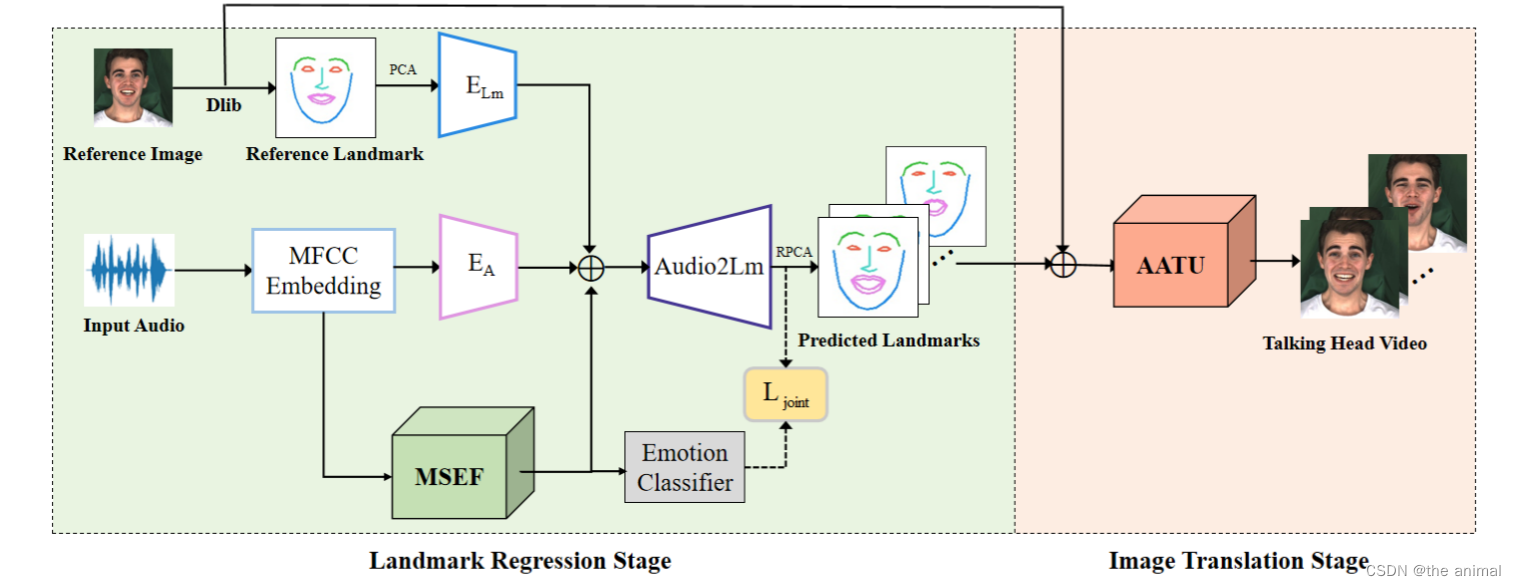
论文的大致流程如上所示。首先使用Dlib从身份参考的图像中,提取特征点,经过由MLP组成的Elm。输入的音频经过MFCC编码,后分为两路。其中一路将编码后的结果送入Ea,另外一路将结果送入MSEF(Memory-Sharing Emotional Feature Extractor)。MESF用于提取情感特征。将Elm和Ea,MSEF的结果一起放入Audio2Lm(由LSTM和一个全连接层组成)。MSEF如下所示: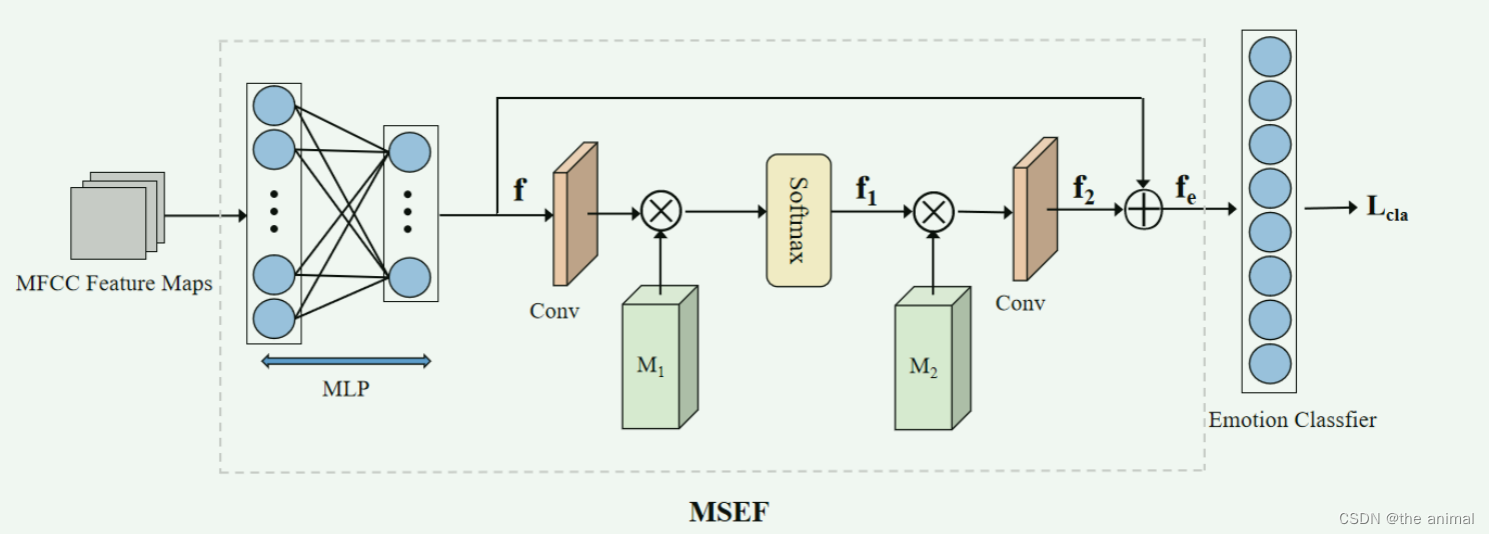
emotion classifier是一个情感分类器,涉及到一个loss函数为:
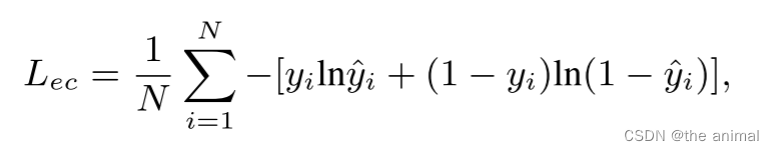
y^为情感分类器预测的情感分类,y为真实的情感标签。Audio2Lm输出为每一帧的面部标志。这里生成的面部标志会与真实的面部标志之间使用loss函数,使生成的标志更加真实。随后将生成的标志与原始图片在通道的维度上拼接,最后放入AATU生成视频帧。
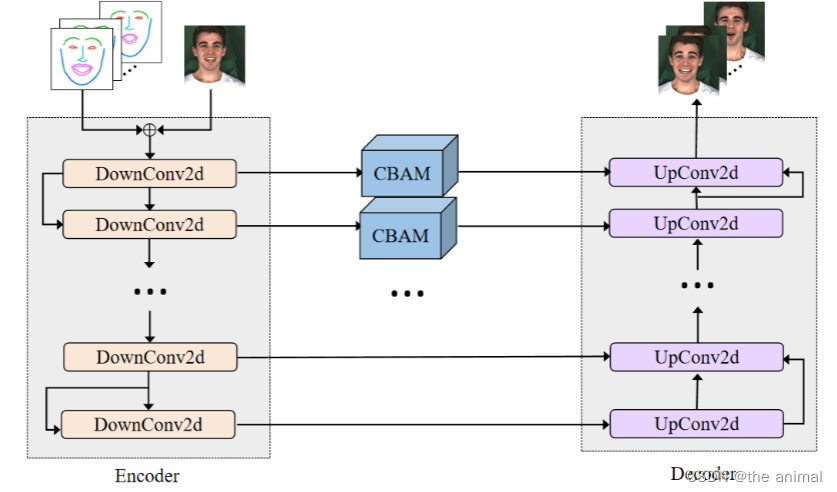
AATU的结构如下所示:们将预测的人脸特征点与参考人脸图像按通道连接起来,并将其作为编码器的输入。解码器的输出是逼真且口型同步的头部说话视频帧。在编码器和解码器的最初四层中,我们分别添加了 CBAM模块。CBAM由空间注意力和通道注意力两个子模块组成,实现了从通道到空间的顺序注意力结构。我们认为,在这个任务中,空间注意力使得神经网络能够更多地关注图像中对面部表情和唇形起决定作用的像素区域,而忽略不重要的区域。通道注意力用于处理特征图通道的分布关系。
https://paperswithcode.com/paper/emotional-talking-head-generation-based-on,在此网站上暂未找到源码。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









