






 这篇博客主要总结了LeetCode中关于二叉树和N叉树的遍历方法,包括前序、中序、后序、层序和垂序遍历。博客详细介绍了递归和非递归的遍历方式,并提供了相关题目链接,适合刷题学习。
这篇博客主要总结了LeetCode中关于二叉树和N叉树的遍历方法,包括前序、中序、后序、层序和垂序遍历。博客详细介绍了递归和非递归的遍历方式,并提供了相关题目链接,适合刷题学习。
LeetCode 刷题笔记 - 树篇
待更新。。。
前言
在刷题之前,最基础的遍历二叉树的理论还是需要先了解一下,所以从大牛的博客中总结了一些,来源也已标注,原文中关于非递归的方法,有更清晰的图解来展示,由于篇幅问题,图片就不一一转载了。如果大家想要更好的理解非递归方法遍历,可以通过链接去学习一下。此外,在总结的基础上我还加上了LeetCode对应的题目以及链接,和一些拓展的方法。
知识点1:二叉树
题目链接: #104. 二叉树的最大深度
题目链接: #108. 将有序数组转换为二叉搜索树
方法一:中序遍历:始终选择中间位置左边元素作为根节点
方法二:中序遍历:始终选择中间位置右边元素作为根节点
方法三:中序遍历:选择任意一个中间位置元素作为根节点
题目链接: #面试题55 - II. 平衡二叉树
题目链接: #面试题 04.02. 最小高度树
题目链接: #面试题28. 对称的二叉树
题目链接: #226. 翻转二叉树(翻转 + 递归即可)
题目链接: #257. 二叉树的所有路径
递归
class Solution(object):
def maxDepth(self, root):
"""
:type root: TreeNode
:rtype: int
"""
if root is None:
return 0
else:
return max(self.maxDepth(root.left), self.maxDepth(root.right)) + 1
迭代
使用栈的方法,和遍历的区别就是存入栈的时候连同节点深度一起,用于后面的深度大小比较
class Solution:
def maxDepth(self, root):
"""
:type root: TreeNode
:rtype: int
"""
stack = []
if root is not None:
stack.append((1, root))
depth = 0
while stack != []:
current_depth, root = stack.pop()
if root is not None:
depth = max(depth, current_depth)
stack.append((current_depth + 1, root.left))
stack.append((current_depth + 1, root.right))
return depth
作者:LeetCode
链接:https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/solution/er-cha-shu-de-zui-da-shen-du-by-leetcode/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题目链接: #559. N叉树的最大深度
class Solution(object):
def maxDepth(self, root):
"""
:type root: Node
:rtype: int
"""
if not root:
return 0
if not root.children:
return 1
return max([self.maxDepth(child) + 1 for child in root.children])
题目链接: #965. 单值二叉树
题目链接: #297. 二叉树的序列化与反序列化
题目链接: #面试题37. 序列化二叉树(和297题相同)
题解: 因为我们要做的是使序列化和反序列化以后的树保持一致,而序列化的方式是可以我们自己决定的,所以通常来说有两种序列化的方式,第一种是用BFS的形式,那么在反序列化的时候我们可以用队列来实现,第二种是DFS的形式,那么反序列化的时候我们可以用递归来实现
BFS
# 序列化
def serialize(self, root):
"""Encodes a tree to a single string.
:type root: TreeNode
:rtype: str
"""
if not root:
return "[]"
ans = "["
queue = collections.deque()
queue.append(root)
# 层序遍历,按顺序独处,即使是None也需要放
while queue:
cur = queue.popleft()
if not cur:
ans += "None,"
else:
ans += str(cur.val) + ","
queue.append(cur.left)
queue.append(cur.right)
return ans[:-1] + "]"
# 反序列化
def deserialize(self, data):
"""Decodes your encoded data to tree.
:type data: str
:rtype: TreeNode
"""
if len(data) <= 2:
return None
# 拆分成list
nodes = data[1: len(data) - 1].split(",")
root = TreeNode(nodes.pop(0))
queue = collections.deque()
queue.append(root)
while queue:
node = queue.popleft()
left_val = nodes.pop(0)
if left_val != "None":
node.left = TreeNode(left_val)
queue.append(node.left)
right_val = nodes.pop(0)
if right_val != "None":
node.right = TreeNode(right_val)
queue.append(node.right)
return root
思路参考:
作者:心谭
链接:https://leetcode-cn.com/problems/serialize-and-deserialize-binary-tree/solution/javascriptceng-xu-bian-li-si-lu-he-shi-xian-by-xin/
来源:力扣(LeetCode)
DFS
class Codec:
def serialize(self, root):
"""Encodes a tree to a single string.
:type root: TreeNode
:rtype: str
"""
def rserialize(node, string):
if not node:
string += "None,"
else:
string += str(node.val) + ","
string = rserialize(node.left, string)
string = rserialize(node.right, string)
return string
return rserialize(root, "")
def deserialize(self, data):
"""Decodes your encoded data to tree.
:type data: str
:rtype: TreeNode
"""
def rdeserialize(l):
if l[0] == "None":
l.pop(0)
return None
root = TreeNode(l[0])
l.pop(0)
root.left = rdeserialize(l)
root.right = rdeserialize(l)
return root
l = data.split(",")
return rdeserialize(l)
# Your Codec object will be instantiated and called as such:
# codec = Codec()
# codec.deserialize(codec.serialize(root))
作者:LeetCode
链接:https://leetcode-cn.com/problems/serialize-and-deserialize-binary-tree/solution/er-cha-shu-de-xu-lie-hua-yu-fan-xu-lie-hua-by-leet/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
知识点2:二叉树遍历
二叉树遍历是比较重要的知识点,以下知识点是从各个博客中总结而来。
那下面这张图为例:
前序遍历:A B D E C F G
中序遍历:D B E A F C G
后序遍历:D E B F G C A
层序遍历:A B C D E F G
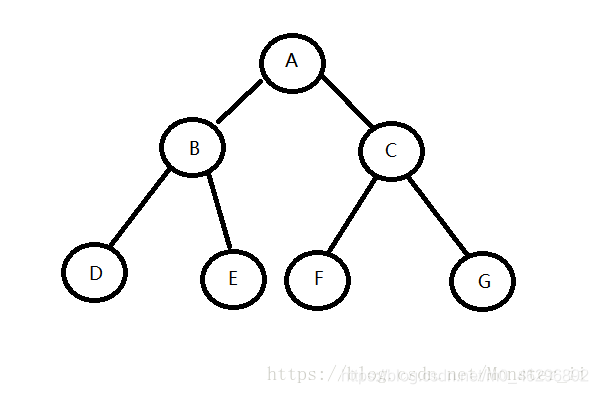
前序遍历
前序遍历可以理解为DFS的搜索,先中间,再左右,通常有两种方法可以用来做前序遍历
递归
# 前序遍历
def search(root):
if not root:
return
print(root.val)
search(root.left)
search(root.right)
栈 (非递归)
方法一
# 前序遍历
def search(root):
stack = []
cur = root
while cur or stack:
while cur:
print(cur.val)
stack.append(cur)
cur = cur.left
top = stack.pop()
cur = top.right
前序递归的实现方法还是比较容易理解的,相比之下非递归的方法会比较南想到一些。非递归的方法通过栈的形式,先一直搜索left并把元素放入栈中,如果left是None,便将栈的顶端元素pop出,并继续搜索该元素的right。
方法二
class Solution(object):
def preorderTraversal(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
if root is None:
return []
stack, output = [root, ], []
while stack:
root = stack.pop()
if root is not None:
output.append(root.val)
if root.right is not None:
stack.append(root.right)
if root.left is not None:
stack.append(root.left)
return output
作者:LeetCode
链接:https://leetcode-cn.com/problems/binary-tree-preorder-traversal/solution/er-cha-shu-de-qian-xu-bian-li-by-leetcode/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
第二种方法就是依次将子节点放入即可,由于栈后进先出的特性,我们需要把子节点倒序放入栈中,才能使遍历顺序为正序,后面提到的N叉树遍历也是使用了此方法。
前序遍历相关题目
题目链接: #144. 二叉树的前序遍历
题目链接: #105. 从前序与中序遍历序列构造二叉树
题目链接: #面试题07. 重建二叉树 (和105题相同)
题解:这道题要求根据前序遍历和中序遍历结果,构造出所给的二叉树,原理是每次取出前序的第一个点作为root节点,在中序中根据该点位置把左右两边分成左子树和右子树,一直递归。代码如下,想要看详细解释的可以点下面的链接,是一个大佬的题解,我觉得写得挺详细的。
链接: 题解
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode:
self.dic, self.po = {}, preorder
for i in range(len(inorder)):
self.dic[inorder[i]] = i
return self.recur(0, 0, len(inorder) - 1)
def recur(self, pre_root, in_left, in_right):
if in_left > in_right: return # 终止条件:中序遍历为空
root = TreeNode(self.po[pre_root]) # 建立当前子树的根节点
i = self.dic[self.po[pre_root]] # 搜索根节点在中序遍历中的索引,从而可对根节点、左子树、右子树完成划分。
root.left = self.recur(pre_root + 1, in_left, i - 1) # 开启左子树的下层递归
root.right = self.recur(i - in_left + pre_root + 1, i + 1, in_right) # 开启右子树的下层递归
return root # 返回根节点,作为上层递归的左(右)子节点
作者:jyd
链接:https://leetcode-cn.com/problems/zhong-jian-er-cha-shu-lcof/solution/mian-shi-ti-07-zhong-jian-er-cha-shu-di-gui-fa-qin/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
中序遍历
同样的,中序遍历也可以通过递归和非递归实现,对于二叉搜索树来说,中序遍历的结果其实就是一个sort过的list
递归
中序遍历和前序遍历递归的区别就是前序为先中间,在左右,而中序为左中右
# 中序遍历
def search(root):
if not root:
return
search(root.left)
print(root.val)
search(root.right)
栈(非递归)
中序访问的非递归写法和前序一样,都要用到一个栈来辅助存储,不一样的地方在于前序访问时,栈中保存的元素是右子树还没有被访问到的节点的地址,而中序访问时栈中保存的元素是节点自身和它的右子树都没有被访问到的节点地址。
# 中序遍历
def search(root):
stack = []
cur = root
while cur or stack:
while cur:
stack.append(cur)
cur = cur.left
top = stack.pop()
print(top.val)
cur = top.right
中序遍历相关题目
题目链接: #94. 二叉树的中序遍历
题目链接: #897. 递增顺序查找树
后序遍历
后序遍历还是分递归版本和非递归版本,后序遍历的递归版本和前序中序很相似,就是输出根节点值的时机不同,而后序遍历的非递归版本则要比前序和中序的要难一些,因为在返回根节点时要分从左子树返回和右子树返回两种情况,从左子树返回时不输出,从右子树返回时才需要输出根节点的值。
后序遍历和前两者的区别是后序的顺序为:左右中
递归
# 后序遍历
def search(root):
if not root:
return
search(root.left)
search(root.right)
print(root.val)
栈(非递归)
后序遍历的非递归同样要借助一个栈来保存元素,栈中保存的元素是它的右子树和自身都没有被遍历到的节点,与中序遍历不同的是先访问右子树,在回来的时候再输出根节点的值。需要多一个last指针指向上一次访问到的节点,用来确认是从根节点的左子树返回的还是从右子树返回的。
方法一
# 后序遍历
def search(root):
stack = []
last = None
cur = root
while cur or stack:
while cur:
stack.append(cur)
cur = cur.left
top = stack[-1]
if not top.right or top.right == last:
stack.pop()
print(top.val)
last = top
else:
cur = top.right
方法二 (特殊)
后序遍历的顺序为left -> right -> root
如果我们把先序遍历的顺序改为 root->right->left,再把结果倒序输出,其实就是我们所需的后序遍历了,这是LeetCode官方给的题解,代码如下:
class Solution(object):
def postorderTraversal(self, root):
"""
:type root: TreeNode
:rtype: List[int]
"""
if root is None:
return []
stack, output = [root, ], []
while stack:
root = stack.pop()
output.append(root.val)
if root.left is not None:
stack.append(root.left)
if root.right is not None:
stack.append(root.right)
return output[::-1]
作者:LeetCode
链接:https://leetcode-cn.com/problems/binary-tree-postorder-traversal/solution/er-cha-shu-de-hou-xu-bian-li-by-leetcode/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
后序遍历相关题目
题目链接: #145. 二叉树的后序遍历
层序遍历
层序遍历相对于前三种是比较特别的一种,前三种都属于DFS的不同变形,而层序遍历就是BFS
递归
class Solution:
def levelOrder(self, root):
"""
:type root: TreeNode
:rtype: List[List[int]]
"""
levels = []
if not root:
return levels
def helper(node, level):
# start the current level
if len(levels) == level:
levels.append([])
# append the current node value
levels[level].append(node.val)
# process child nodes for the next level
if node.left:
helper(node.left, level + 1)
if node.right:
helper(node.right, level + 1)
helper(root, 0)
return levels
作者:LeetCode
链接:https://leetcode-cn.com/problems/binary-tree-level-order-traversal/solution/er-cha-shu-de-ceng-ci-bian-li-by-leetcode/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
迭代
from collections import deque
class Solution:
def levelOrder(self, root):
"""
:type root: TreeNode
:rtype: List[List[int]]
"""
levels = []
if not root:
return levels
level = 0
queue = deque([root,])
while queue:
# start the current level
levels.append([])
# number of elements in the current level
level_length = len(queue)
for i in range(level_length):
node = queue.popleft()
# fulfill the current level
levels[level].append(node.val)
# add child nodes of the current level
# in the queue for the next level
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
# go to next level
level += 1
return levels
作者:LeetCode
链接:https://leetcode-cn.com/problems/binary-tree-level-order-traversal/solution/er-cha-shu-de-ceng-ci-bian-li-by-leetcode/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
# 层序遍历
def search(root):
queue = []
if not root:
return
queue.push(root)
while queue:
top = queue.pop(0)
if top.left:
queue.append(top.left)
if top.right:
queue.append(top.right)
print(top.val)
参考自:
作者:Monster_ii
链接:https://blog.youkuaiyun.com/monster_ii/article/details/82115772
来源:优快云
层序遍历相关题目
题目链接: #102. 二叉树的层次遍历
题目链接: 面试题32 - I. 从上到下打印二叉树
题目链接: 面试题32 - II. 从上到下打印二叉树 II(和#102相同)
题目链接: #107. 二叉树的层次遍历 II
题目链接: #637. 二叉树的层平均值
垂序遍历
在LeetCode中有一些相关垂序遍历的题目:
题目链接: #987. 二叉树的垂序遍历
这道题的大致思路就是先遍历整颗树,把root节点的坐标设为(0,0),然后把每个节点的坐标以及值存进一个列表中,并按列,行,值的优先顺序对列表进行排序。最后遍历排序完的列表并输出即可
class Solution(object):
def verticalTraversal(self, root):
"""
:type root: TreeNode
:rtype: List[List[int]]
"""
seen = []
def dfs(root, x, y):
seen.append([x, y, root.val])
if root.left:
dfs(root.left, x - 1, y + 1)
if root.right:
dfs(root.right, x + 1, y + 1)
dfs(root, 0, 0)
seen.sort(key=lambda x: (x[0], x[1], x[2]))
ans = []
prev = None
for x, y, val in seen:
if x != prev:
ans.append([val])
else:
ans[-1].append(val)
prev = x
return ans
知识点3:N叉树遍历
前序遍历
题目链接: #589. N叉树的前序遍历
# Definition for a Node.
class Node(object):
def __init__(self, val=None, children=None):
self.val = val
self.children = children
递归
class Solution(object):
def preorder(self, root):
"""
:type root: Node
:rtype: List[int]
"""
# 递归
ans = []
def search(root):
if not root:
return
ans.append(root.val)
for child in root.children:
search(child)
search(root)
return ans
栈(非递归)
class Solution(object):
def preorder(self, root):
"""
:type root: Node
:rtype: List[int]
"""
# 非递归
if not root:
return []
stack = [root]
ans = []
while stack:
top = stack.pop()
ans.append(top.val)
stack.extend(top.children[::-1])
return ans
链接:https://leetcode-cn.com/problems/n-ary-tree-preorder-traversal/solution/
来源:LeetCode
后序遍历
题目链接: #590. N叉树的后序遍历
和二叉树后序遍历使用了相同的方法:
class Solution(object):
def postorder(self, root):
"""
:type root: Node
:rtype: List[int]
"""
if root is None:
return []
stack, output = [root, ], []
while stack:
root = stack.pop()
if root is not None:
output.append(root.val)
for c in root.children:
stack.append(c)
return output[::-1]
作者:LeetCode
链接:https://leetcode-cn.com/problems/n-ary-tree-postorder-traversal/solution/ncha-shu-de-hou-xu-bian-li-by-leetcode/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
知识点4:二叉搜索树
二叉查找树(Binary Search Tree),(又:二叉搜索树,二叉排序树)它或者是一棵空树,或者是具有下列性质的二叉树: 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它的左、右子树也分别为二叉排序树。
以下是LeetCode中涉及到二叉搜索树的一些题目,链接已附上:
题目链接: #669. 修剪二叉搜索树
题目链接: #700. 二叉搜索树中的搜索
题目链接: #938. 二叉搜索树的范围和

















 442
442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









