






ConcurrentHashMap
我们知道,HashMap是线程不安全的,而其它两种HashTable和Collections.synchronizedMap性能又很差,因此在这种并发环境下,为了能够兼顾线程安全以及执行效率,ConcurrentHashMap就应运而出了
ps:如对上述Map知识有所不了解,可以点击此处链接
HashMap小结
ConcurrentHashMap1.7中主要功能的实现
概念及背景
ConcurrentHashMap 其底层可以看做一个二级的 HashMap,第一层存储的是 Segment 数组对象,每个 Segment 存储着一个 HashEntry 数组,其下存储着很多 key-value 键值对

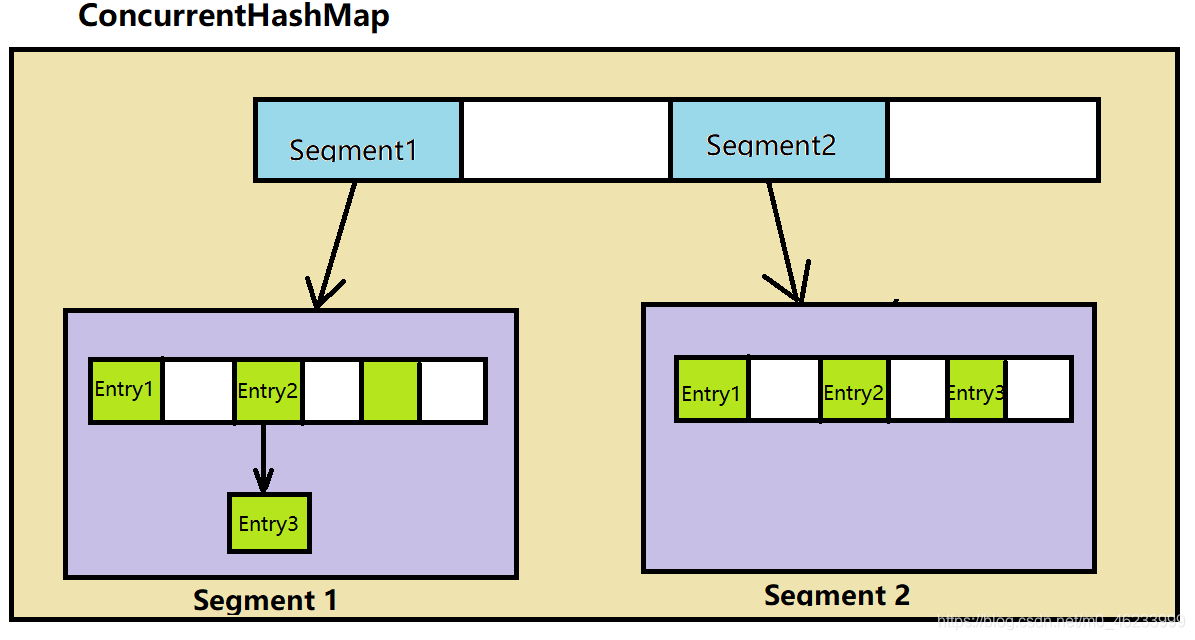
ConcurrentHashMap 此种设计采用分治的方法,让每个 Segment 实现读写的高度自治,如此一来就能很大程度上减少锁的使用基础上还能保证安全
并发环境下的ConcurrentHashMap:
-
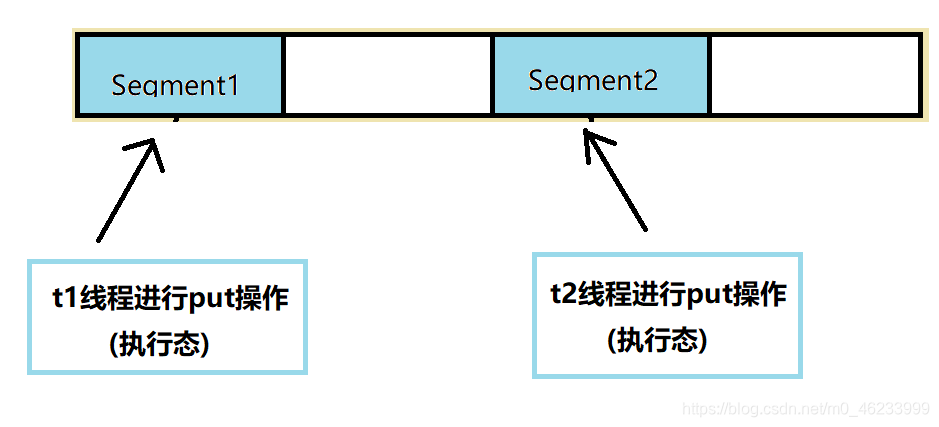
不同的 Segment 在两个线程同时进行读写操作,因为在不同 Segment 中不会有线程安全问题
-
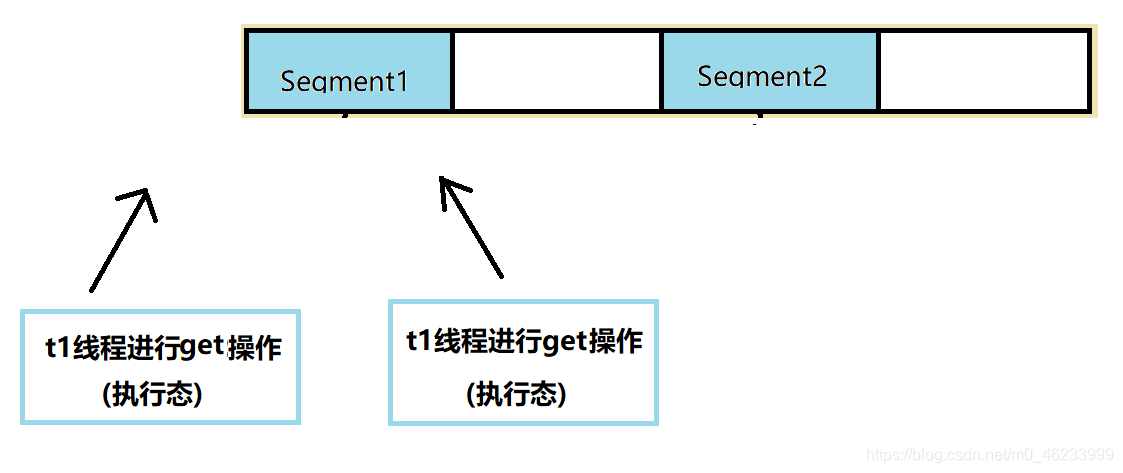
同一 Segment 下两个线程同时进行读操作,因为没有进行数据的修改所以无需上锁,没有安全问题
-
同一 Segment 下两线程同时进行读写操作,写操作会有数据的修改,两个线程不能同时进行
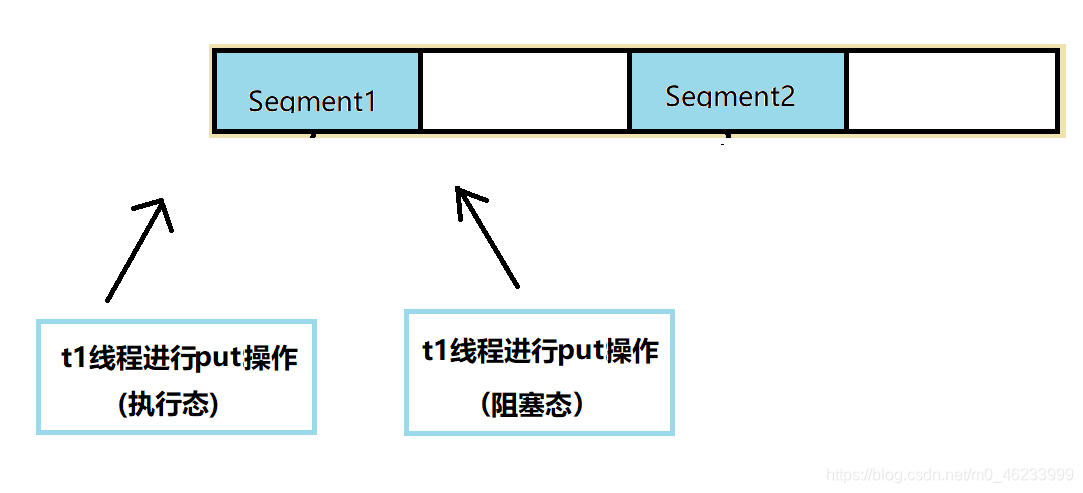
Segment的写操作有加同步锁,对同一个线程进行写操作获取不到锁时,会进入阻塞态
如此一来,每个Segment各持一把锁,这样就能最大程度的增大效率并且保证了线程安全
get方法
- ConcurrentHashMap通过对 key 进行hash运算
- 通过得到的hash值确定在哪个 Segment对象下
- 再通过hash值,确定在Segment数组的具体哪个位置
- 最后返回该节点的value
put方法
- ConcurrentHashMap通过对 key 进行hash运算
- 通过得到的hash值确定在哪个 Segment对象下
- 获取锁,若获取到进入第4步,否则阻塞等待
- 再通过hash值,确定在Segment数组的具体哪个位置
- 对要修改的HashEntry进行操作
- 释放锁
Size方法
ConcurrentHashMap的size()方法是一个循环嵌套方法
- 遍历全部Segment
- 给Segment的元素数量求和
- 给Segment的修改次数求和
- 将计算得的修改次数之和与上次的和将比较,若增加,说明在计算中有数据的修改,则重新统计,并且定义一个尝试次数,对其++
- 若尝试次数大到一个阈值,则对Segment对象加锁,再做统计
- 统计结束释放锁,返回统计的size
其size的加锁操作为乐观锁的方式,即先假设在统计次数过程中不会有数据的修改,如果最后发现则重新统计,如果重复多次依旧不安全,则为该Segment加锁
ConcurrentHashMap1.8中主要功能的实现
简单认识
- 与 jdk1.7 不同,ConcurrentHashMap 没有用到 Segment创建一个二级HashMap,而是沿用了HashMap的底层 散列表+红黑树实现
- ConcurrentHashMap是线程安全的,支持多线程环境下的并发读写
- 查找操作即get方法并没有加锁,因为其操作不会影响线程安全
- ConcurrentHashMap中的key 和 value都不允许为空
较jdk1.7的改进
- 取消了 Segment 的设计,取而代之的是直接的Node对象,使用Node数组来存储数据,并对每个数组中的元素考虑进行加锁
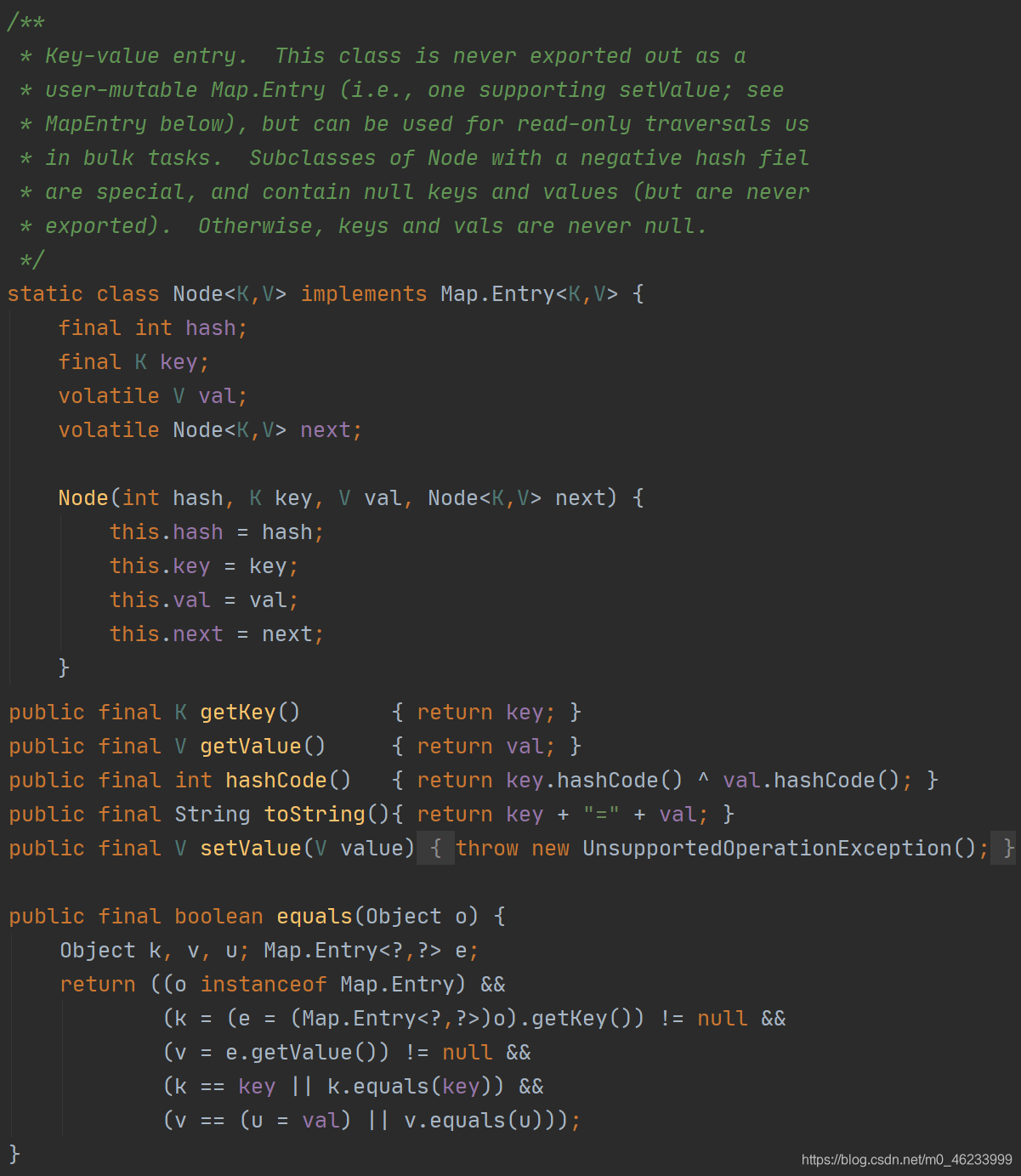
- 底层引入红黑树,当Node元素下的链表长度大于8时,该链表由于过长,查询元素时效率较低(O(n))于是就将其转化为红黑树,从而提高查找效率
- 取消jdk1.7的Segment分段锁机制,改为CAS+Synchronized实现线程安全
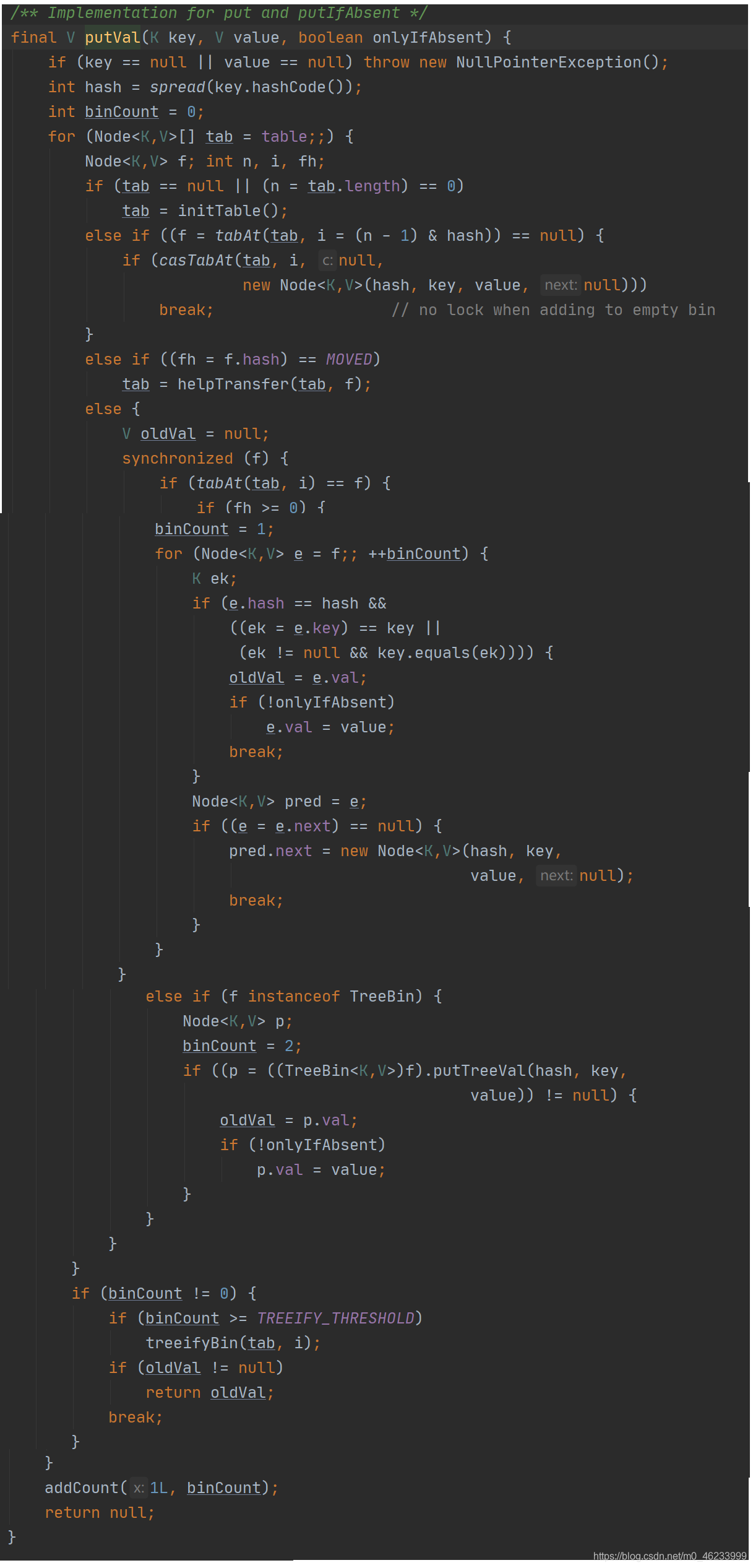
get方法
- 获取hash值,通过hash值确定在散列表的哪个位置(Node)
- 若key == node.val,则直接返回node
- 如果此时在扩容则调用该节点的find()方法,查找到就返回结点否则返回null
- 如果key == node.val,则遍历节点找它的下一个,直到全部遍历完还没找到则返回null
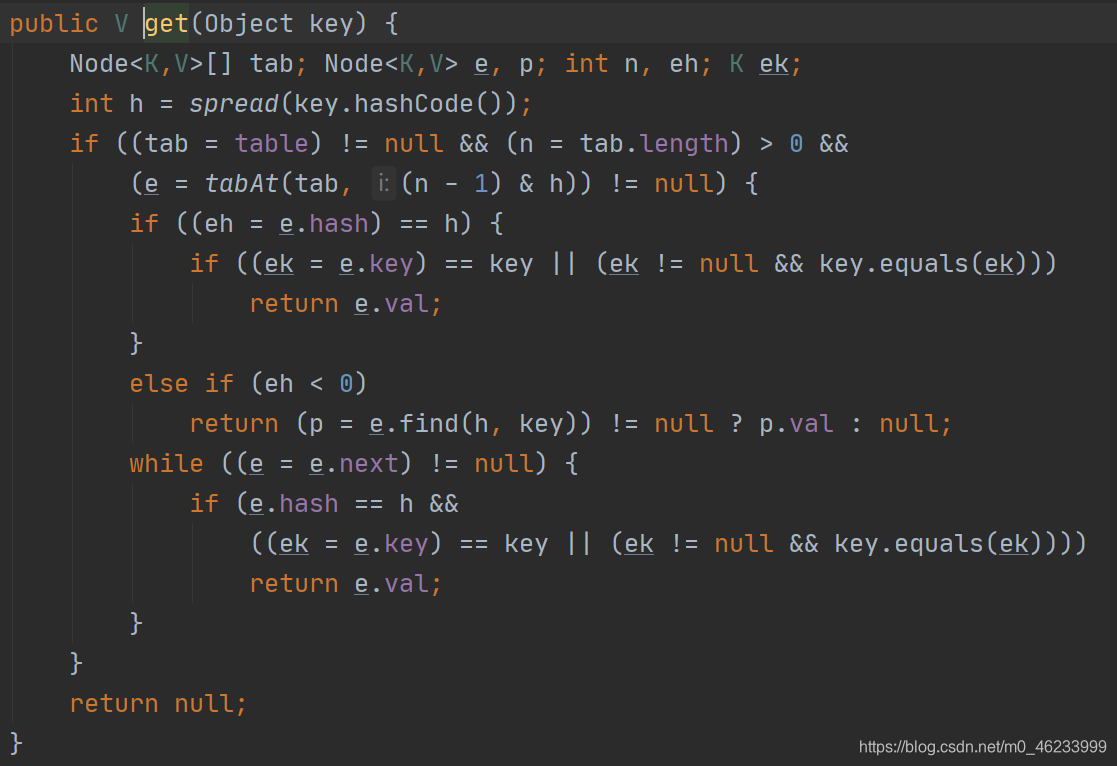
put方法
- 首先进入自旋过程,直到抢占到所该线程put成功
- 如果数组没有初始化,先进行初始化操作吊桶initTable()方法
- 如果没有发生哈希冲突,就调用casTabAt()方法,执行CAS操作
- 此时如果有线程正在执行扩容操作,则扩容操作先一级进行
- 如果发现哈希冲突,就去抢占锁,当链表时直接尾插,当为红黑树时按其树结构插入
- 如果插入前是链表,插入结束后链表长度大于8,则将链表转化为红黑树
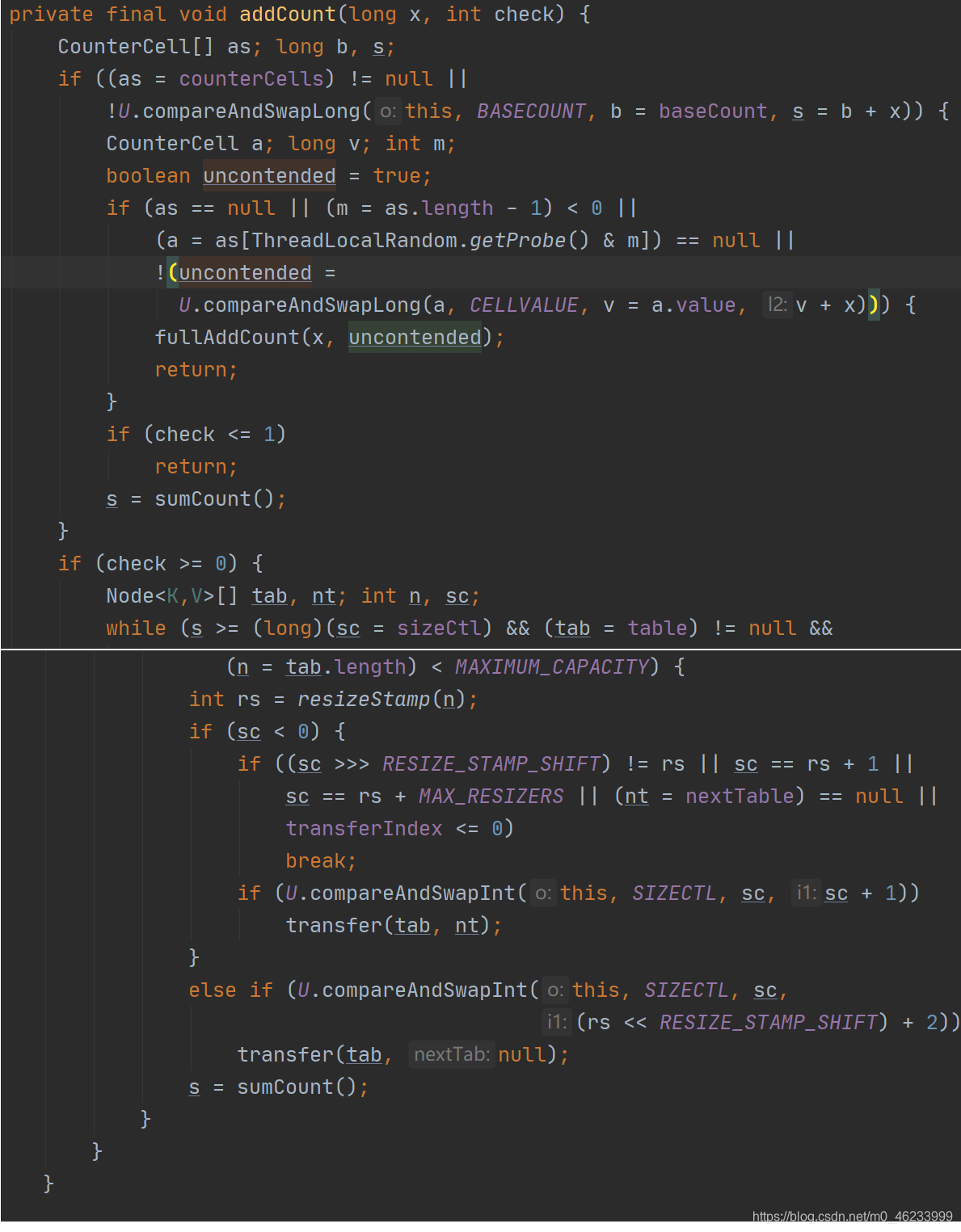
- 如最后添加成功则调用addCount()方法统计size,检查是否需要扩容
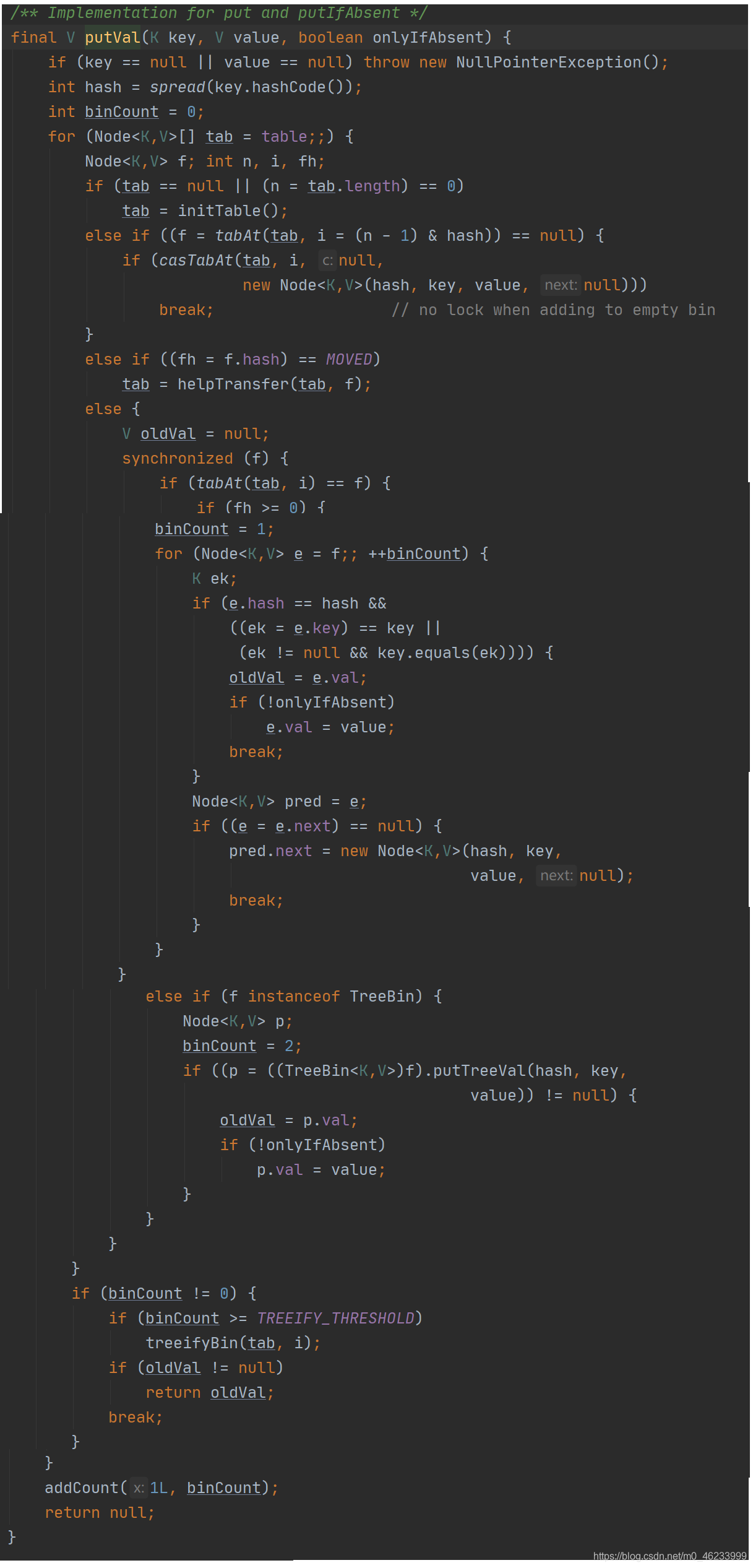
获取size方法
jdk1.8获取 size 是通过维护两个变量,对 baseCount 和 counterCell 进行 CAS 计算,最终通过 baseCount 和 遍历 CounterCell 数组得出 size
- baseConnt:为记录节点个数的变量,volatile修饰
- counterCells:其本质是一个数组,其内部存放着counterCell,每个 counterCell 存放着部分节点个数,counterCell类其内部只有一个 volatile 修饰的变量,用于存放结点个数,该类被@sun.misc.Contended 这个注解标识着这个类防止需要防止 “伪共享”。
伪共享:缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能
每次put 和 remove 操作中,如果操作成功最后方法返回前都会调用addCount()方法,此方法会根据传入的参数更新baseConnt 与 counterCells,从而实时记录节点个数
- List item
具体addCount()操作:
- 当 counterCells == null 时,尝试对baseCount进行CAS,如果成功则完成更新,否则尝试对counterCells进行CAS,执行fullAddCount()
- 线程通过随机数ThreadLocalRandom.getProbe() & (n-1) 计算出在counterCells数组的位置,如果不为null,则fullAddCount()一直循环直到成功,否则counterCells数组会进行扩容为原来的两倍,继续随机,继续添加
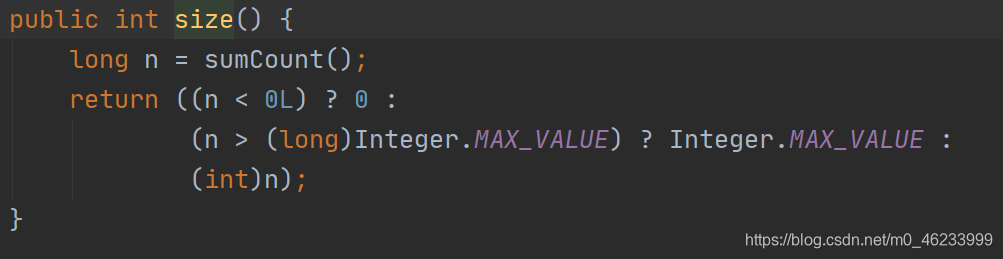
具体的size()操作:
-
通过 sumConut() 获取当前的size
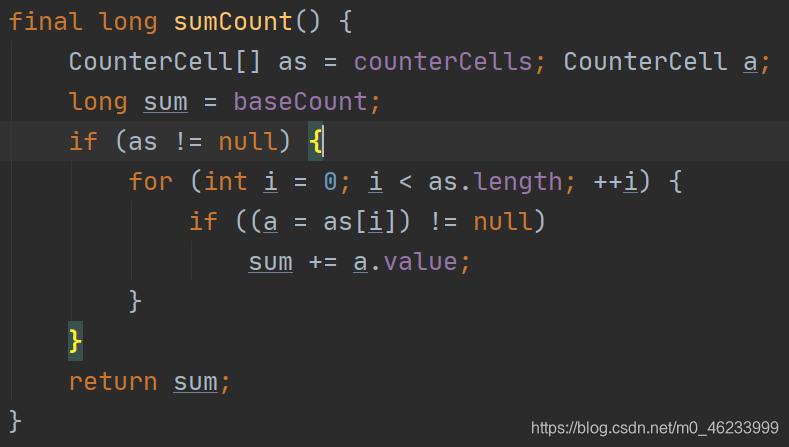
-
进入 sumCount() 方法,迭代counterCells,将其与baseConnt加和最终统计
-
因为 size() 最终返回的是int类型,而Map的size有可能超过int定义的最大值Integer.MAX_VALUE,当大于最大值是,返回 Integer.MAX_VALUE,因此jdk中获取size的方法推荐使用mappingCount(),其与size()唯一的区别是,返回值为long类型,无序考虑size的大小

ConcurrentHashMap 在 jdk1.7 与 jdk1.8的不同:
- 底层实现不同:1.8中取消了 Segment 的二级HashMap结构,而是使用散列表+链表/红黑树来实现
- 线程安全机制不同:1.7中使用 Segment 分段锁机制,1.8中使用 CAS+Synchronized 实现线程安全
- 锁的粒度不同:1.7中是对 每个Segment对象加速,1.8中对每个元素,即Node结点加锁
- 哈希冲突时存放相同hash值元素的底层数据结构不同,1.8在1.7链表储存的基础上,进行优化当链表长度超过阈值8时,链表会转化为红黑树,从而提高查询效率
HashTable、HashMap、ConcurrentHashMap的区别
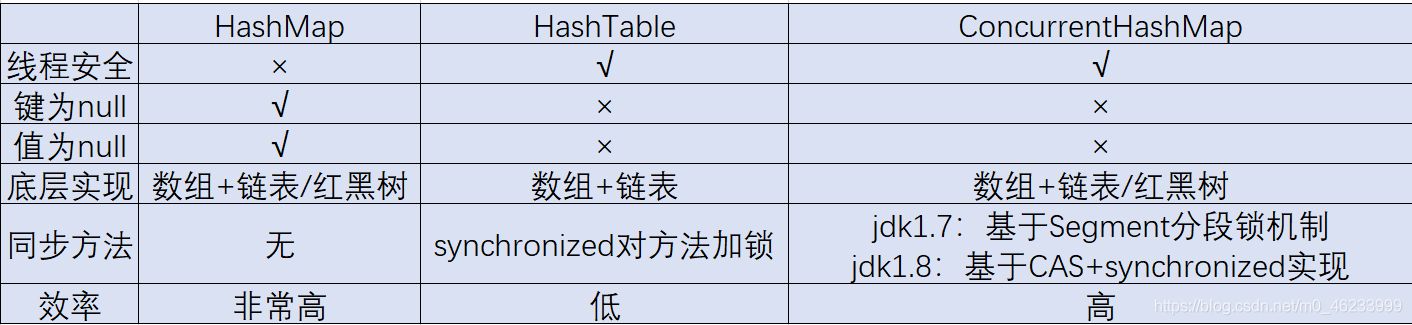
- HashMap允许可以有一个key和多个value为null,HashTable和ConcurrentHashMap不允许
- HashMap线程不安全,HashTable与ConcurrentHashMap是线程安全的
- 效率:因为三者单线程理论上操作的时间复杂度都为O(1),总体上
HashMap由于不保证线程安全,所以效率最高
HashTable直接使用Synchronized修饰方法实现线程安全,但每次操作都会将HashTable整体锁住,执行效率很低
ConcurrentHashMap使用CAS+Synchronized实现线程安全,在方法内部对部分代码块使用Synchronized,操作时先尝试CAS若多次尝试仍失败,则进入Synchronized - 底层数组扩容:
HashTable初始大小为11,扩容方式为 new = old*2+1
HashMap和ConcurrentHashMap相同,初始值都为16,扩容方式为
new = old²
以上便是对ConcurrentHashMap的知识点小结,随着后续学习的深入还会同步的对内容进行补充和修改,如能帮助到各位博友将不胜荣幸,敬请斧正

















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









